# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
“Full Attention 正在被遗忘”
随着 Agent 的广泛应用带来的长序列需求,传统 GPT 架构的 Attention 部分,由于其 O (N^2) 的计算复杂度,正逐渐被视为性能瓶颈而遭到替换。而 Attention 机制的架构迭代,也正在以前所未有的速度推进。目前业界的主流方案大致可以分为两种:Linear Attention 和 Sparse Attention。其中 Linear Attention 以 Qwen-Next 和 Kimi-K2 为代表,本质上是通过改进后的 Linear Attention 来实现信息压缩,使得存储代价压缩到 O(1) ,计算代价压缩到 O(N);而 Sparse Attention 则主要通过稀疏化来优化计算开销,实践中往往能够达到接近 90% 以上的稀疏度,这也是在 DeepSeek-V4 中被正式采用的技术路线。
然而,在 RTPurbo 中 [1],前期工作已经充分指出,使用 Full Attention+Sliding Window Attention(SWA)就已经可以在精度无损的保证下,将原生 Transformer 的 85% 注意力头变成 SWA,实现 15% Full Attention + 85% SWA 的混合架构,实现 5X 的 KV 和 Attention 压缩。无独有偶,在近期的一些开源架构,如 MIMO、Gemma4、GPT-OSS 中,也使用了 SWA+Full Attention 这一设计,颇有一种 “大道至简” 的设计思路。
尽管替换了 85% 的 Full Attention 成 SWA,剩下的 15% Full Attention 在超长序列(1M)下仍然会成为性能瓶颈。今天,为了彻底解决 Attention 的推理瓶颈,来自阿里的 RTP 团队推出了第二代 Attention 压缩技术:RTPurboV2。通过结合 Headwise 压缩,低秩投影压缩,以及聚类技术,RTPurboV2 可以在 V1 架构的基础上,进一步在 Full Attention 部分实现 16~32 倍计算压缩。
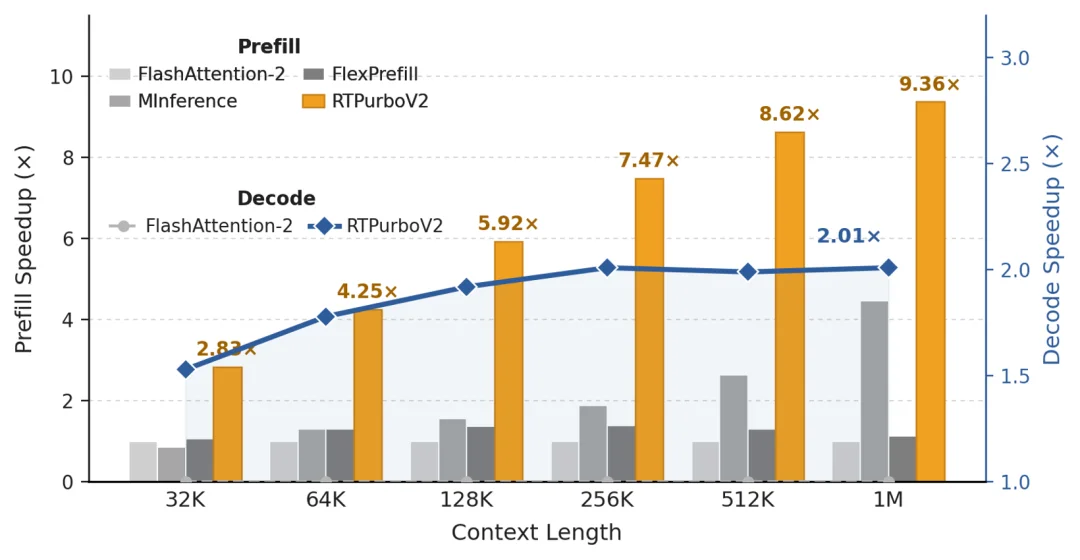
图 1:RTPurboV2 性能
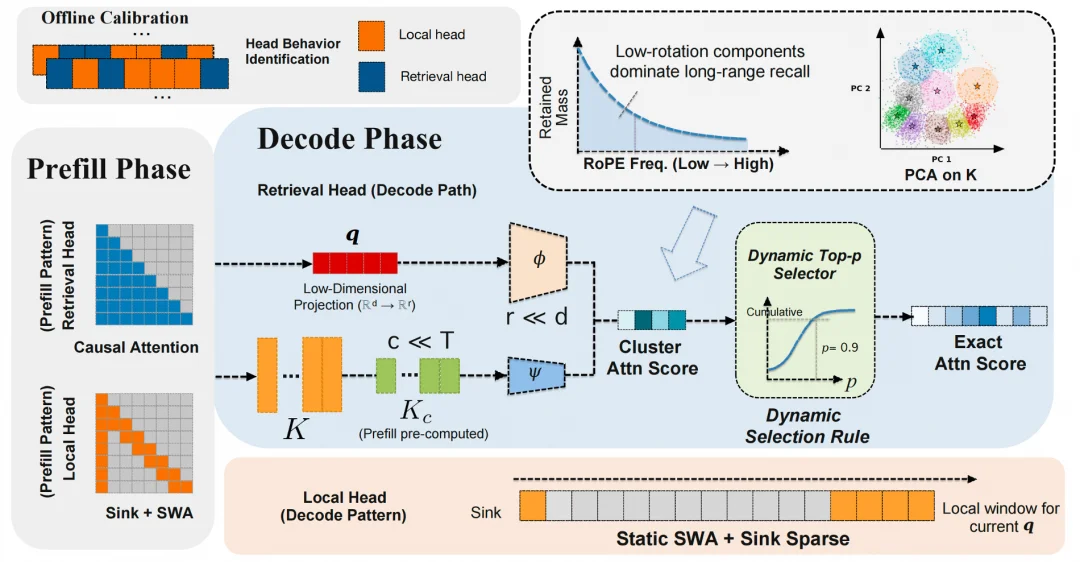
图 2:RTPurboV2 整体架构
Full Attention 模型在预训练过程中,已经自发地形成了高度稀疏的注意力结构。我们要做的不是 "强加" 稀疏性,而是 "释放" 它。这个判断建立在四个可量化的关键发现之上。
发现一:85% 的注意力头天然适配滑动窗口
研究人员发现,在 Full Attention 模型中,不同的 Attention Head 实际上承担着不同的职责。有些 Head 专注于捕捉局部信息(比如相邻 token 之间的关系),有些 Head 则负责捕捉长距离依赖(比如与自身相关信息的关联)。
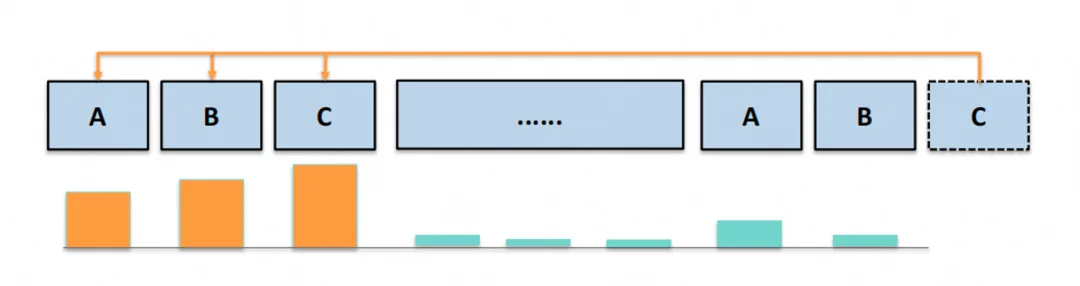
图 3:与大多数只关注局部信息的 Attention Head 不同,Retrieval Heads 会关注与当前 query token 语义相关的区域,即使这些区域在上下文中距离很远
更具体地说,通过可视化分析,研究者观察到,在 Qwen3 系列模型中:
这种分工模式在不同输入、不同序列长度下高度稳定,是模型在预训练中自发习得的内在结构。直接推论:85% 的 Full Attention 计算可以安全地替换为 SWA(参考 RTPurbo),几乎不影响模型能力。 真正需要解决的,只有剩余 15% 召回头的高效计算问题
发现二:长程检索由低维子空间主导
召回头的核心任务是在整个序列中做语义匹配 —— 看起来仍然是 O (N^2) 的问题。RTPurboV2 的核心技术升级之一是对于召回头和 RoPE 的细致理解。在深入分析 RoPE 位置编码的频率结构后,团队发现了召回头的 RoPE 分量存在显著的维度冗余。在 RoPE 下,Query-Key 的注意力得分可以分解为不同频率分量的叠加:
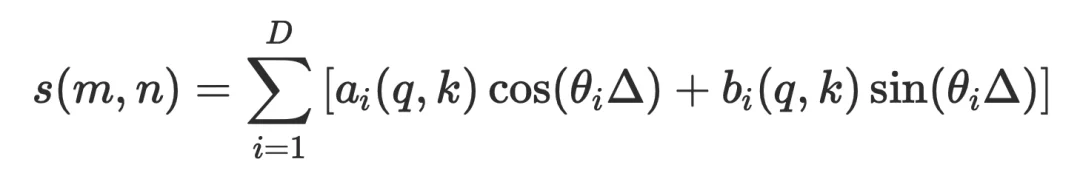
其中 △ = m - n 为位置偏移。不同频率分量的作用存在本质差异:
对于长距离检索而言,高频分量导致注意力得分随位置距离剧烈波动,削弱了语义信号的稳定传递。而从召回任务本身的性质出发:一个 token 的召回强度不应随相对位置的变化而快速波动。由此可以推断,在召回头上的高频分量一定是出于被压制状态,召回头本质上只会利用 RoPE 低频分量。
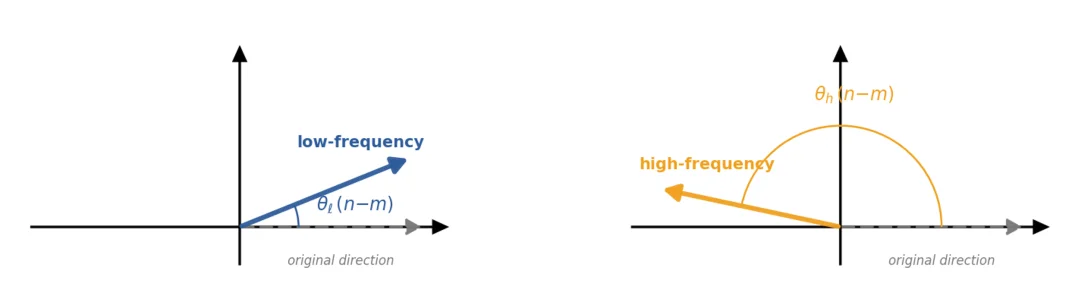
图 4:RoPE 下高频分量随位置快速旋转,影响长程检索
因此,一个很自然的设计是训练一个低维 projector,我们通过低秩映射将原始特征维度从 D 压缩至 r=16 (其中 r ≪ D),系统性地保留低频语义分量、过滤高频位置噪声。实验验证,仅 16 维即可达到 90%+ 的 token 召回率。
发现三:序列维度的冗余:基于高质量特征的自适应聚类
这是 RTPurboV2 的核心技术升级之二。团队意识到低秩投影带来的增益不止于计算量的直接降低 —— 它从根本上改善了 Key 向量在语义空间中的分布质量。高频噪声被过滤后,语义相似的 token 在低秩空间中天然聚拢,语义无关的 token 彼此远离。这为序列维度的进一步压缩创造了理想条件。
基于这一特性,我们在序列维度上引入自适应聚类,构建两级漏斗式计算流程:
1. 粗粒度匹配:将 N 个 token 聚类为 K 个语义簇(如 K=128),Query 先与 K 个簇中心做轻量级匹配,复杂度仅 O (N·K)
2. 细粒度计算:仅在命中的相关簇内执行完整 Attention 计算
两阶段串联,整体复杂度从 O (N^2) 跃迁至 O (N·K):
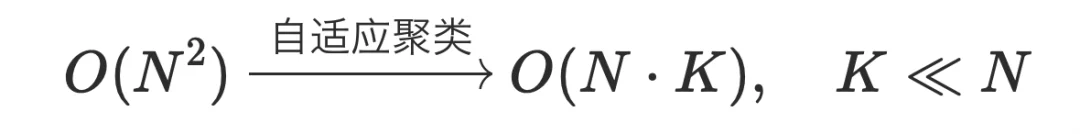
两步压缩之间存在显著的协同增益:
两者形成乘法效应:压缩比越激进,协同增益越显著。
发现四:动态 top-p 显著优于固定 top-k
传统的稀疏注意力方法通常采用固定 top-k 策略,即每个 query 只保留 attention score 最高的 k 个 token。但这种做法存在一个根本性问题:不同的 attention head、不同的序列长度、不同的 query,所需的上下文 token 数量差异巨大。
以同一模型同一层的三个召回头为例,在 64K 上下文下,覆盖 90% 注意力质量所需的 token 数:
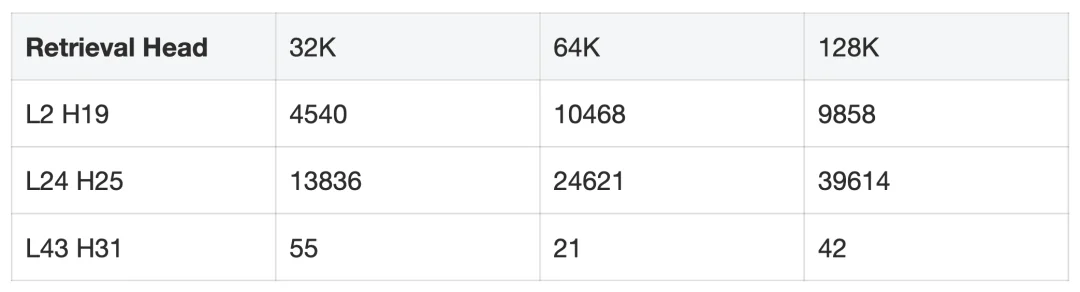
表 1:不同 Attention Head 在不同序列长度下,top_p = 0.9 时召回的 Token 数量
三个数量级的差异,意味着不存在一个固定的 k 值能同时满足所有场景。

四个发现汇合,RTPurboV2 的推理架构自然成型:
而让模型适配这套稀疏化架构,仅需训练约 600 步,约 1M label tokens。更具体的,RTPurboV2 的训练分为两个阶段:

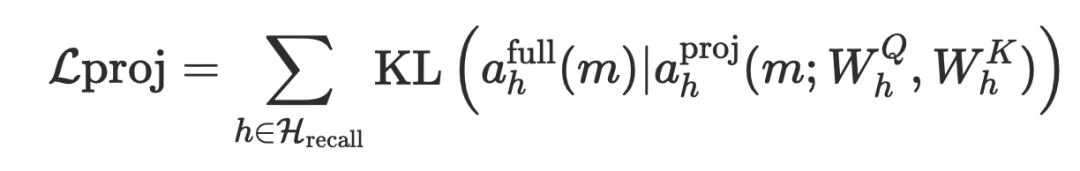
在数十万亿 token 的预训练语境下,1M token 几乎可以忽略。这也从另一个角度验证了核心论点:Full Attention 的稀疏性是内生的,微调只是完成从隐式到显式的转化。
为了全面验证 RTPurboV2 的有效性,我们在 Qwen3-Coder-30B-A3B 和 Qwen3.5-35B-A3B 两款主流模型上,针对长文本核心基准进行了系统性评估。
1. Ruler 基准测试:长程检索的精度突破
在 Qwen3-Coder-30B-A3B 模型上,我们通过离线校准识别出约 15% 的关键 “召回头”。针对这些 Head,我们在 Prefill 阶段采用 Full Attention 并配合 K Cache 聚类,在 Decode 阶段则应用 RTPurboV2 实现稀疏化;其余流式头统一采用 SWA(局部窗口设为 8192)。
如图 3 所示,RTPurboV2 在 32K 和 64K 序列长度下均取得了最优平均分(分别为 89.69 和 85.61),显著优于除 Full Attention 外的所有基线方法,证明了其在长程信息召回上的卓越精度。
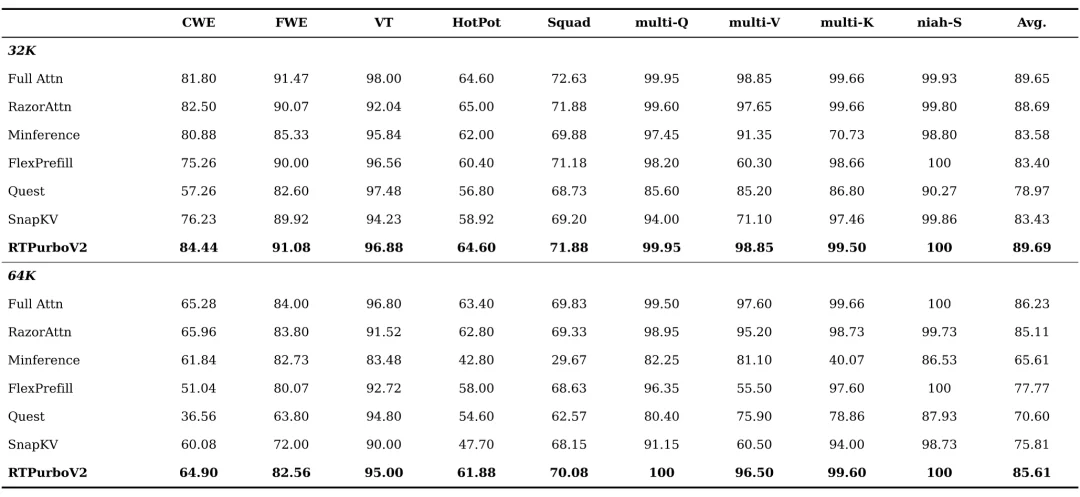
图 5:Ruler 测评结果
2. LongBenchV2 基准测试:高召回比例下的无损压缩
针对 Qwen3.5-35B-A3B 模型,校准显示其超过 70% 的 Head 具有召回特性。为此,我们采取了全量稀疏化策略。实验结果(图 4)表明,RTPurboV2 在大幅降低计算开销的同时,完整保留了模型的基础能力,精度表现与 Full Attention 持平。

图 6:LongBenchV2 测评结果
3. CoT 推理任务:复杂逻辑的稳定支撑
在链式思维(CoT)推理任务中,RTPurboV2 同样表现出色(图 5),实现了模型推理能力的近乎无损保留,进一步验证了该方案在复杂逻辑场景下的鲁棒性。
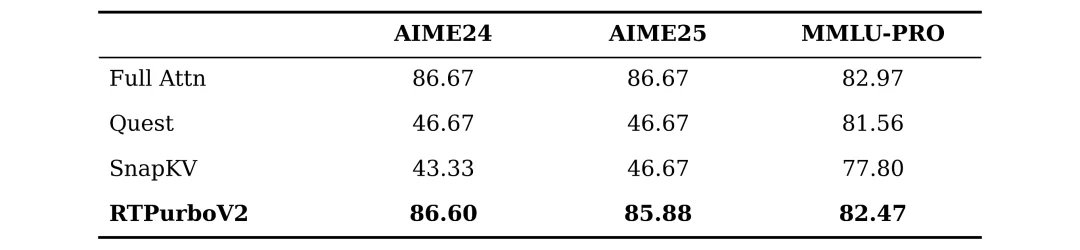
图 7:CoT 任务测评结果
当前注意力机制的研究重心,大量集中在设计全新的高效架构上。这条路径无疑有其价值。但 RTPurboV2 揭示了一个容易被忽视的事实:Full Attention 模型自身就蕴含着巨大的效率空间,而释放这种内生稀疏性的成本极低。
600 步训练,精度几乎无损,Prefill 最高 9.36 倍加速。这意味着,对于选择 SWA + Full Attention 混合架构的团队 —— 包括 MIMO、Gemma 4、GPT-OSS—— 不需要替换架构就能获得接近 SOTA 新方案的压缩效率。
“原生 Transformer,从未过时。Full Attention strikes back.”
团队介绍
RTP-LLM 是阿里巴巴智能引擎团队自研的高性能大模型推理引擎,支持了淘宝、天猫、高德等核心业务的大模型推理需求。智能引擎源自阿里巴巴搜索、推荐和广告技术,是阿里 AI 工程领域的先行者和深耕者。团队专注于 AI 工程系统的建设,主导建立了大数据 AI 工程体系 AI・OS,持续为阿里集团各业务提供高质量的 AI 工程服务。
RTP-LLM 项目已开源,欢迎交流共建: https://github.com/alibaba/rtp-llm
参考文献:
[1]: 仅需 15% 全量 Attention!「RTPurbo」阿里 Qwen3 长文本推理 5 倍压缩方案来了 :https://mp.weixin.qq.com/s/wFAJ6oG1CsKBJiCBE45BsQ
[2]: Full Attention Strikes Back: https://huggingface.co/papers/2605.16928
文章来自于"机器之心",作者 "机器之心"。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
