# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
机器人视觉语言动作(Vision-Language-Action, VLA)模型越来越多地开始展示叠衣服、倒茶、做咖啡等复杂操作。但是,今天的大多数 VLA 更像 “展台机器人”。它们在固定场景、固定布局、固定光照下表现惊艳,可一旦真正进入开放环境,就立刻暴露其泛化性问题:物体位置变一点、背景换一下、光照改变一些,VLA 的成功率就会暴跌。对于新任务,往往需要重新收集大量示教轨迹(demonstration),才能让 VLA 学会。
但这些其实只是表面困境。真正困难的,也是 VLA 走向实际应用场景真正需要的,其实是:
主流范式往往过度对齐原始轨迹本身,却缺少对 “轨迹背后意图” 的显式表征与推理,从而在泛化与迁移上受限。
针对上述问题,上海创智学院 × 上海交通大学 x 智动未来提出:

MINT 是一种面向强泛化、强迁移的 VLA 架构与训练范式。它的核心思想是:机器人不应该只模仿 “动作轨迹”,而应该分层次地理解:
一旦 VLA 能显式理解和表征抽象的行为意图,长期困扰 VLA 的泛化性和迁移性问题,就可以打开新的解法。
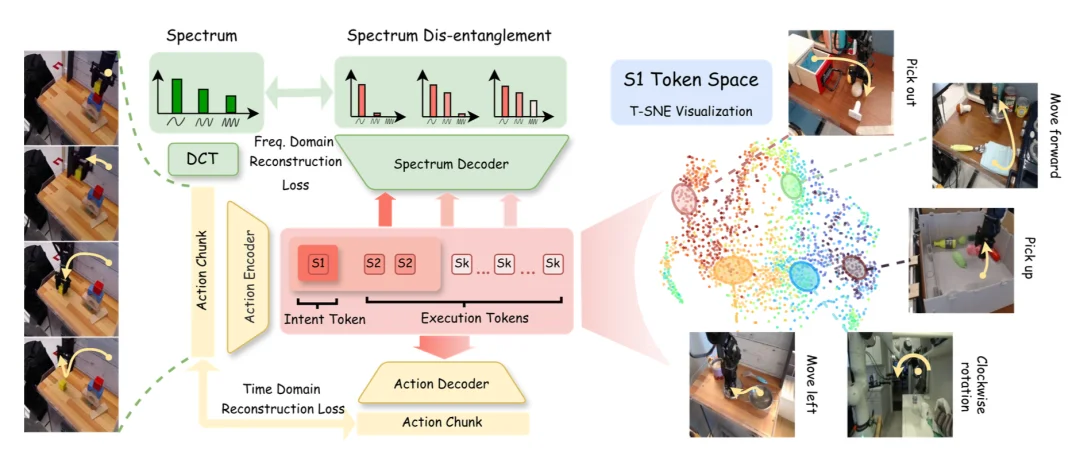
MINT 的关键技术来自一个信号处理视角:动作轨迹可以被看作时间信号,天然具备频谱结构。
SDAT 把动作表征映射到多个尺度的词元:
S1-SK 尺度的词元数逐步增多,形成金字塔形状的词元表征体系。
那么,不同尺度的词元是如何与低频和高频信号建立对应关系的呢?
MINT 应用了如下技术:
如此,使得粗尺度词元专注于学习轨迹的大体形态,而细尺度词元则专注于补充轨迹细节。
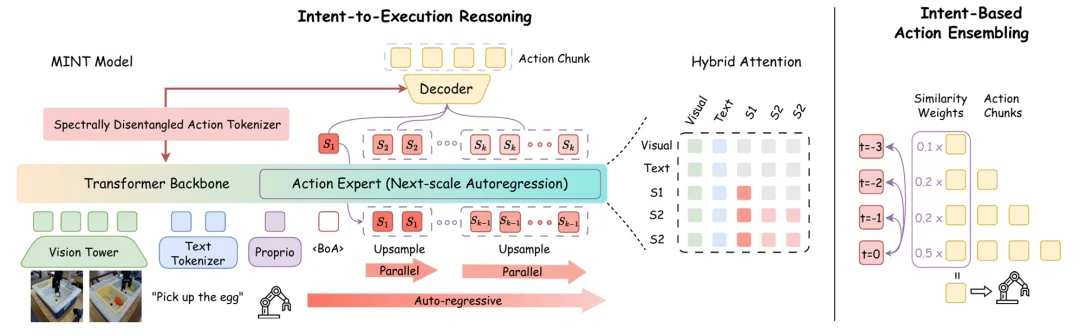
在策略层面,MINT 采用 “Intent → Execution” 的分层生成:
先预测 Intent Token-> 再逐层生成 Execution Tokens-> 最后将多尺度词元解码为连续控制轨迹
这个由粗到细的过程相当于在词元空间里进行分步推理:先确定要执行的行为意图,再补上达到该意图所需的控制细节。这种方式可以提升学习效率,并在长程任务中带来更稳定的执行表现。
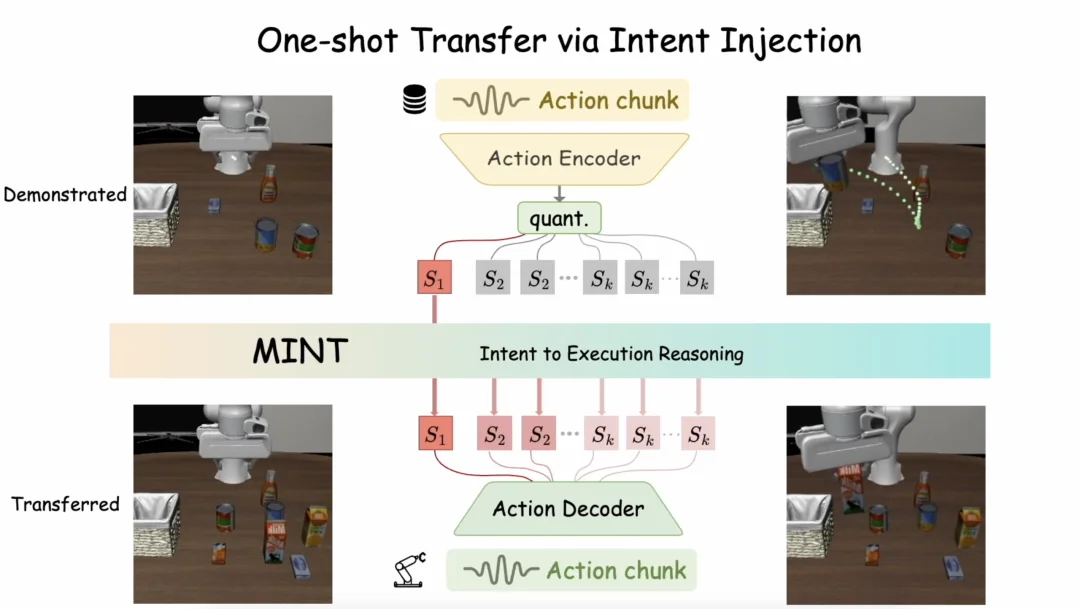
MINT 最有意思的部分来了:Intent Token 可以直接用于策略迁移。
既然 Intent Token 表示的是抽象 “行为意图”,那它就可以直接替代语言,作为「任务表达(task specification)」。
这意味着,对于一个全新任务,模型不需要重新训练:只要提供一条示教轨迹,提取其 Intent Token,并将该 Token 注入到策略的生成过程中,模型就能在相同的推理框架下生成对应的执行细节并完成任务。
由于注入的是更抽象的意图而不是整段轨迹细节,这种迁移方式在跨任务、跨场景时更容易保持稳定。论文将这一能力称为:「One-shot Transfer via Intent Token Injection」 而这也是 MINT 最重要的创新之一。
一、基准任务性能:全面超越 SOTA 方法
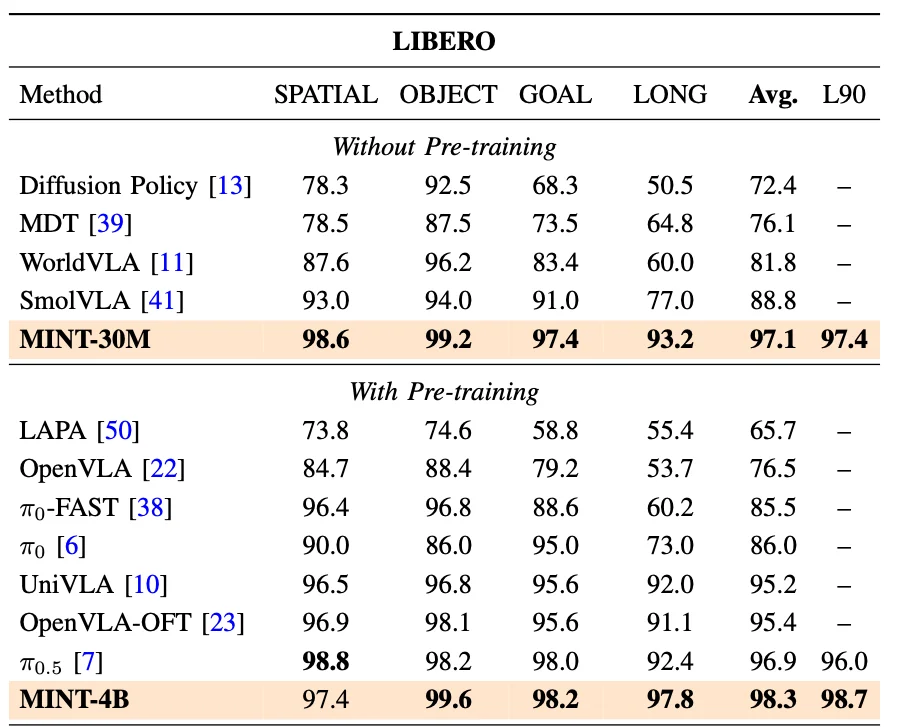
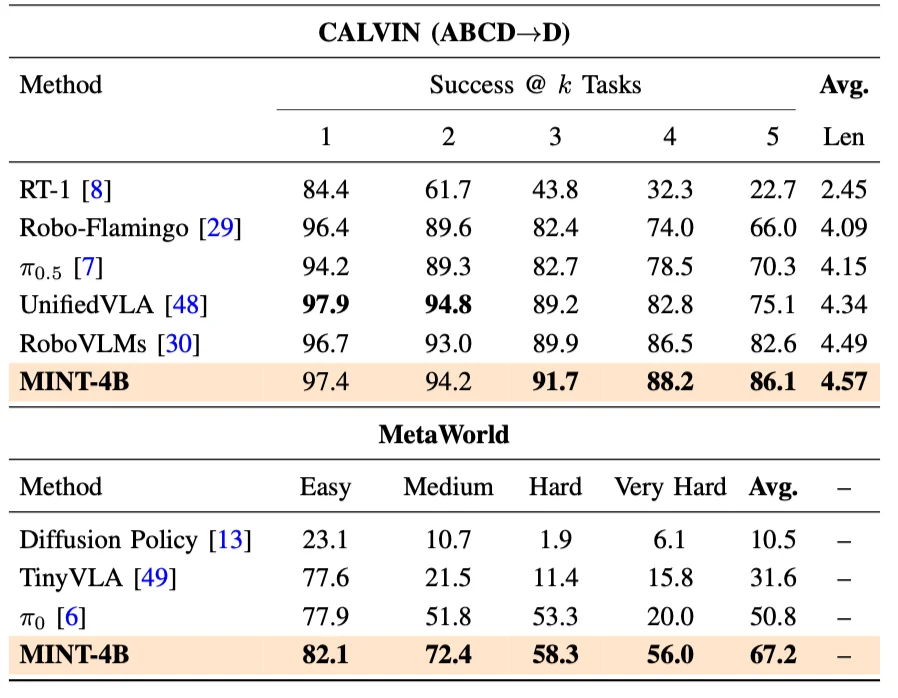
在 LIBERO、CALVIN 和 MetaWorld 三个基准上,MINT 的性能全面超越了当前的 SOTA 方法:
二、泛化性:对抗分布外强扰动
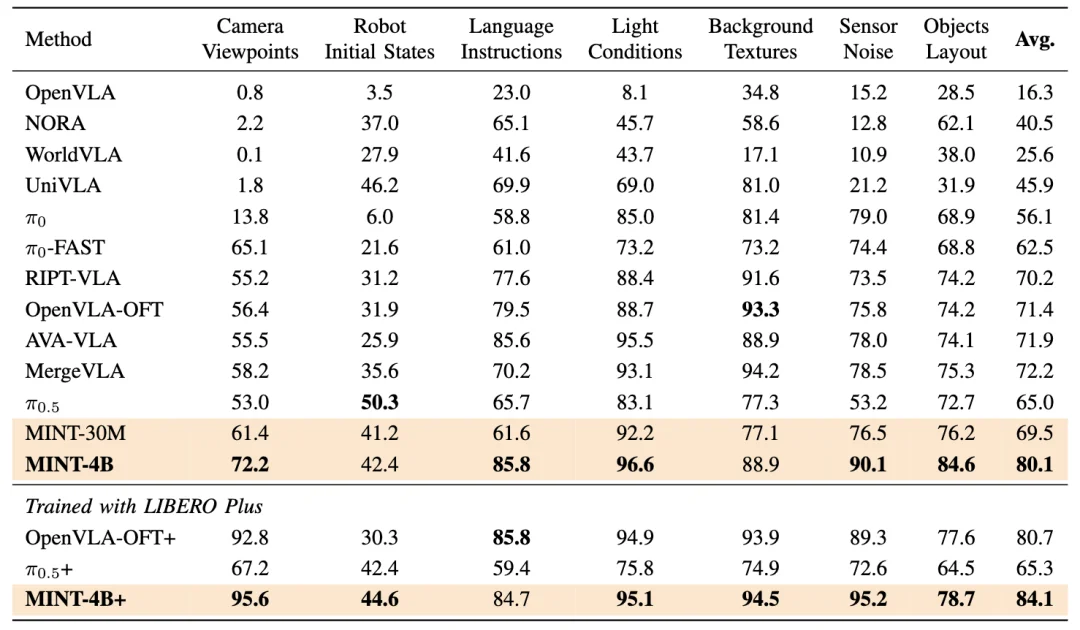
在更强调分布外鲁棒性的测试中,作者在 LIBERO 上训练、并在分布更广的 LIBERO-Plus 上评估,考察相机视角、初始姿态、光照、背景纹理与视觉噪声等多类强扰动。
这些结果都印证了:“行为意图认知” 对于提升 VLA 泛化性的关键作用。
三、技能迁移:只需要演示一次
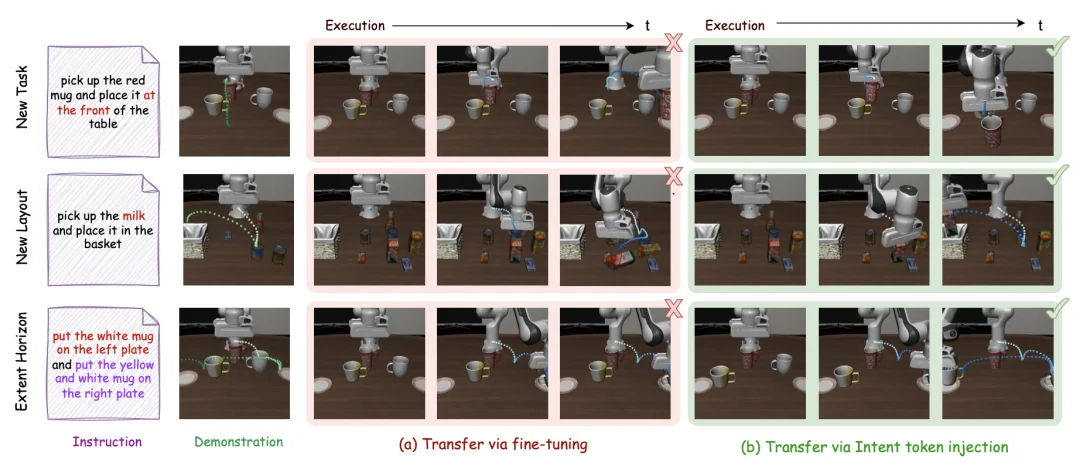
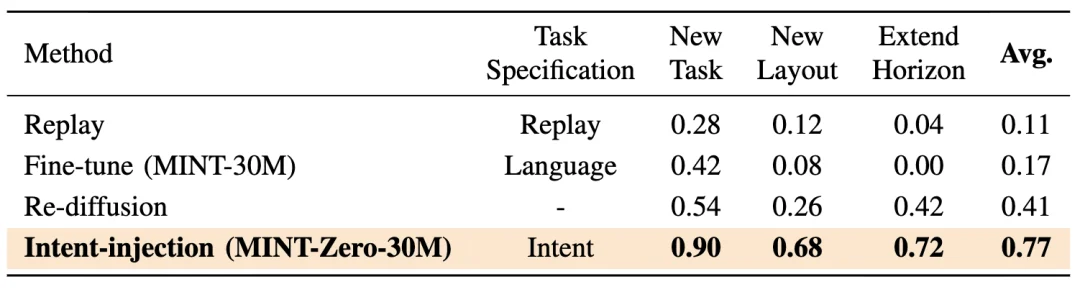
现有的迁移方法无论是通过微调(fine-tuning)还是重扩散(re-diffusion),在只有单条示教轨迹的条件下,都很难完成迁移。而 MINT 通过 Intent Token Injection,能稳定完成新任务迁移、新场景迁移:
四、真机验证:物理世界的高效落地
研究团队进一步在真实的 Piper-X 6DoF 机械臂上进行了真机实验。训练任务包括抓放香蕉、堆叠积木、插马克笔等,各提供了仅 20 条示教轨迹供模型后训练。测试任务还包含了从未见过的叠杯子任务,用以测试零样本泛化。
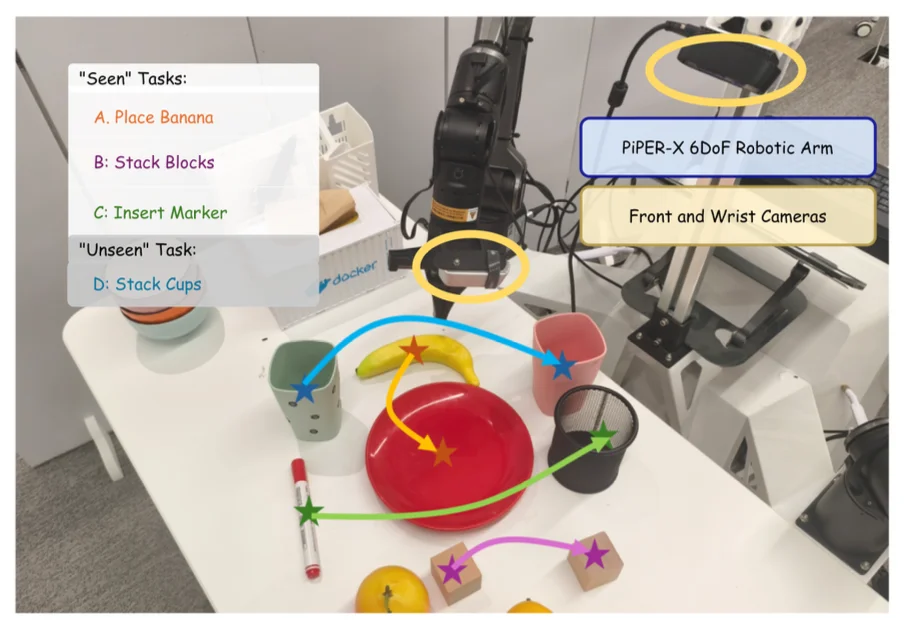
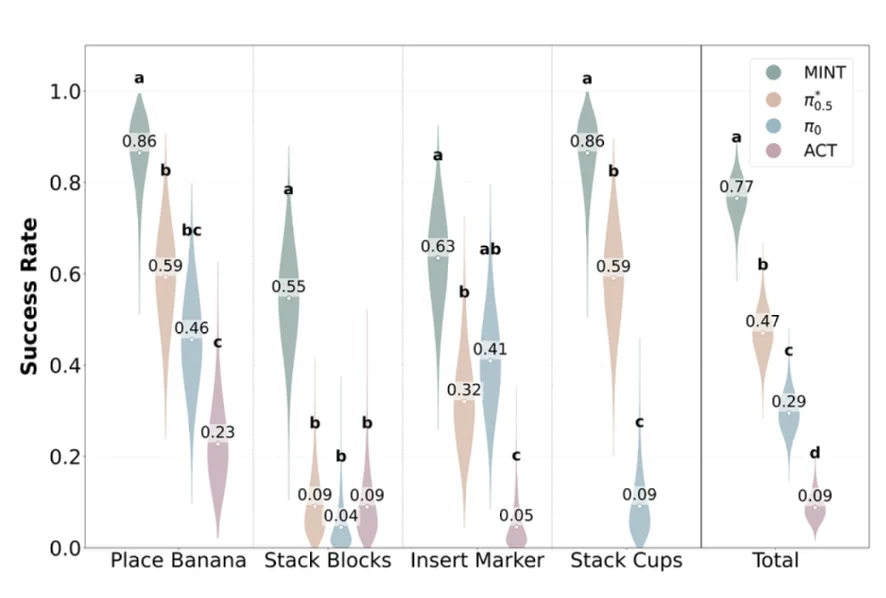
结果显示:
这些真机结果进一步证明:MINT 学到的,已经不是单纯的轨迹,而是真正可迁移的行为结构。
文章来自于"机器之心",作者 "机器之心"。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
