# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在机器人、自动驾驶、AR等真实场景中,空间理解从来都不是“看一眼图像”就能解决的问题。
相机持续移动、视角不断变化、目标时隐时现,空间信息从来不是明确且集中的,而是往往分散在长时间视频流里,模型不仅要“看得见”,更要“记得住、连得起来、还能持续更新”。
这使得流式空间智能成为多模态大模型迈向真实世界应用的一道关键门槛。
这篇文章的出发点是思考:多模态Agent如何在动态变化的世界中持续更新自己,而不是每次都像第一次看见世界。
真实世界不是一张静态图片,也不是一段固定长度的视频,而是一段持续展开的经验流。
正如人理解空间,也不是一次性看完整个房间,而是在移动、观察、遗忘、修正中,逐渐形成稳定的空间记忆。
近日,由清华大学博士生刘芳甫担任一作,联合多位研究者共同完成的Spatial-TTT,被计算机视觉顶级会议ECCV 2026正式接收。
ECCV与CVPR、ICCV通常并称为计算机视觉三大顶级会议,每两年举办一届,用率常年偏低。
对于一项工作而言,入选ECCV不只是多了一个会议标签,也意味着它需要在研究问题、方法创新与实验完整性上接受严格的同行评审。
Spatial-TTT瞄准的,正是多模态模型从“看懂画面”迈向“理解真实空间”过程中一个尚未解决的核心问题:
当视频不断延长,模型能否不依赖无限膨胀的上下文,而是在观看过程中,持续形成并更新自己的空间记忆?
实验中,仅有2B参数的Spatial-TTT,在论文测试的多个专项空间智能基准上超过GPT-5、Gemini-3-pro等闭源模型,并能够处理最长120分钟的流式视频。
它所给出的答案可以概括为一句话:
让模型不只是看视频,而是在观看过程中,边看、边更新、边“长出”一份空间记忆。

空间智能的难点,从来不只是“把上下文做长”,而是空间信息该如何在时间维度上被选择、组织、保留下来。
在真实场景中,模型面对的是一段持续涌入的视觉流:
相机移动会改变视角,遮挡会打断观察,物体的显隐又会让关键证据散落在相距很远的时刻。
现有方法尝试过引入深度信息、多视角输入、空间专项微调数据,乃至训练专用空间模型,但大多仍局限于单张图像或短视频片段,很难扩展到真实应用中动辄几十分钟、几小时的长时程流式视频。
更进一步看,问题的核心并不只是模型"窗口不够长",而是它缺少一种机制,能在推理过程中不断把新观察吸收进内部状态,再把这些状态组织成一份可供后续调用的空间记忆。
传统的静态推理范式很难解决这一点,而TTT恰好提供了另一种可能:让模型在推理时边看边更新参数,用参数本身的变化来承担记忆功能。
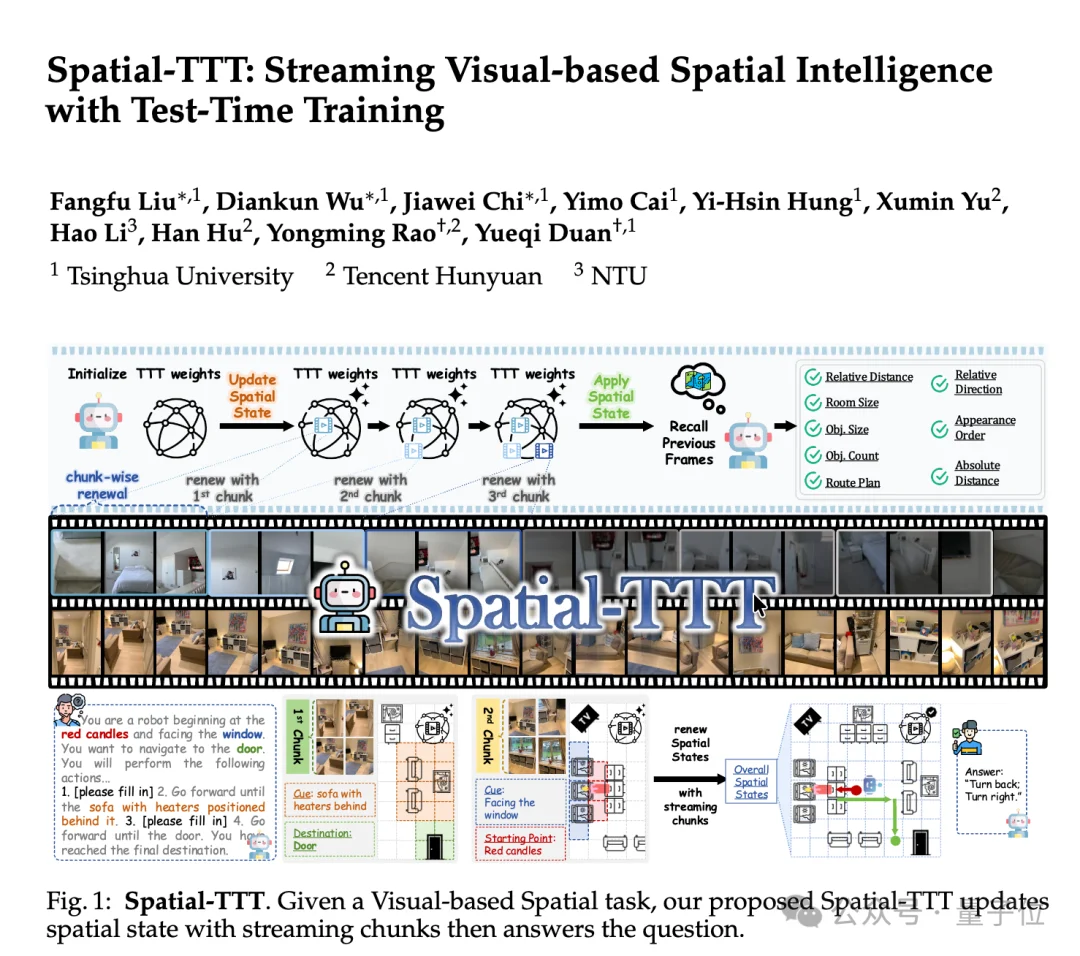
为应对上述挑战,研究团队提出Spatial-TTT,将fast weights作为一种紧凑的非线性记忆,在处理视频流的同时进行在线更新,不断累积跨时间的3D空间证据。
与把整段视频一次性塞进上下文不同,Spatial-TTT更像是在持续“维护一份空间状态”:
每当新的视频chunk到来,模型就对已有的空间记忆做一次增量式刷新。
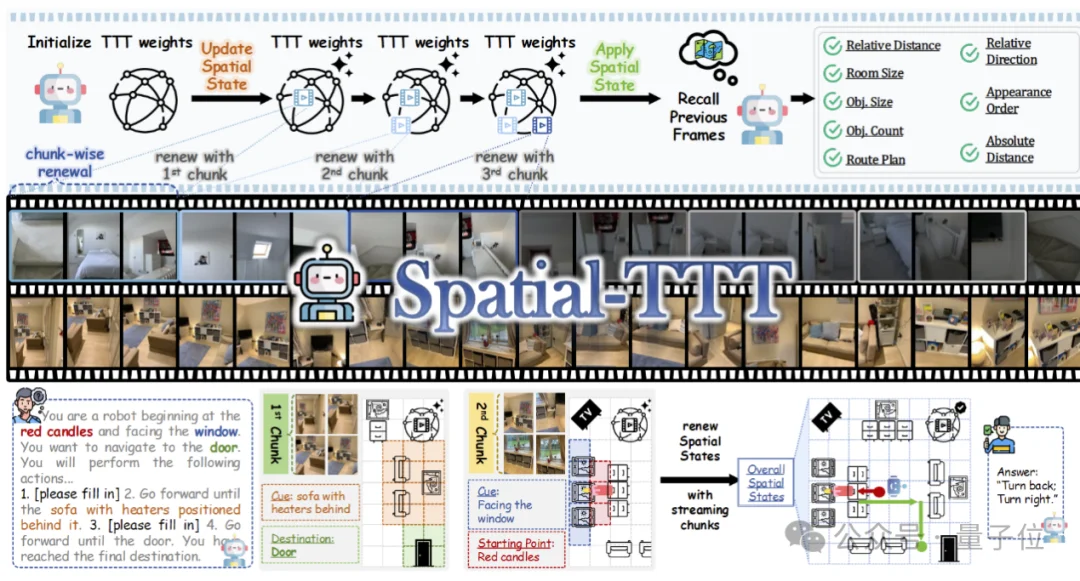
TTT此前已经被用于语言建模、新视角合成和视频生成,但流式视觉空间理解有其特殊性:
模型既要保留预训练阶段形成的视觉—语言能力,又要显式利用视频token的局部几何与时间连续性,还需要足够密集的监督,教会快速权重哪些空间信息值得长期保留。
围绕这三个问题,Spatial-TTT分别设计了混合架构、空间预测机制和密集场景描述监督。
直接把所有注意力层替换成TTT层,理论上效率更高,但会破坏原始多模态模型的跨模态对齐与语义能力,相当于在获得长程记忆的同时,丢失了模型原本的语义理解能力。
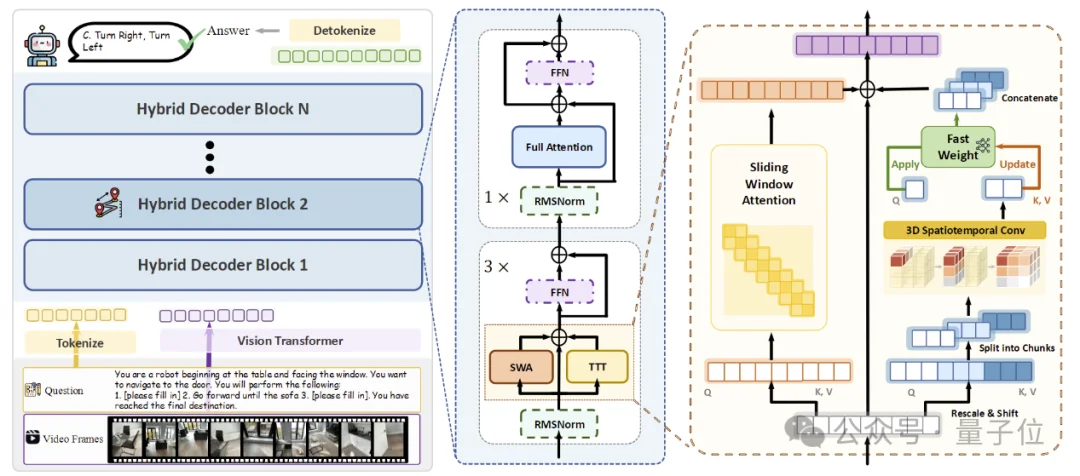
为此,研究团队设计了混合式TTT架构:
也就是说,Spatial-TTT并非用TTT取代注意力,而是让两者各自承担不同角色:TTT负责记得更久,全注意力负责理解得更准。
与此同时,为提升大块视觉token的处理效率,模型还引入了large-chunk更新,并搭配并行的sliding-window attention——
前者大幅提升GPU利用率,避免传统TTT小块频繁更新导致的效率低下,以及强行切断帧内空间结构的问题;
后者则保证chunk内部仍具有完整的因果局部交互,避免空间连续性被更新边界打断。
两者分工明确:滑动窗口负责处理近期帧和局部结构,快速权重则负责跨块保存更长期的信息。
这一设计让模型在长视频场景下既具备线性复杂度带来的可扩展性,又不会牺牲局部时空建模能力。
仅仅把TTT搬到视频中还不够。
研究团队观察到,传统TTT中Q/K/V通常通过逐点线性投影生成,这意味着每个视觉token在进入快速权重之前,主要被当成一个孤立单元处理——
这种方式忽略了视觉token之间天然存在的局部几何结构和时间连续性,不利于空间状态的稳定更新。
但视觉空间信息天然存在于局部关系中,如果忽略这种局部连续性,快速权重就需要从零开始推断几何关系,记忆也更容易变得碎片化。
为此,Spatial-TTT在TTT分支中引入了空间预测机制(spatial-predictive mechanism),对Q/K/V加入轻量级3D时空卷积。
经过这一处理,fast weights学到的就不再是孤立token之间的映射,而是时空上下文到时空上下文的预测关系,从而能更好地捕捉几何对应、视角变化与时间连续性,显著增强在线更新的稳定性与有效性。
现有空间智能数据大多是稀疏、局部的Q&A监督,例如判断两个物体的相对关系,或者回答一个整数计数问题——
这类短答案,只能覆盖场景状态中的极小部分,对fast weights学习长期有效的更新动态帮助有限。
问题在于,快速权重需要学习的是如何持续维护整个场景,而不仅仅是提取某个局部答案。
如果训练中只问桌子和椅子的关系,模型就没有动力记住房间里其他物体,也没有动力形成完整的空间布局。
因此,研究团队构建了一份稠密的3D场景描述数据。
这份数据要求模型生成覆盖场景全局语境、物体类别与数量、空间关系等内容的scene walkthrough,用更高覆盖率的监督信号来训练fast weights。
该训练采用两阶段spatial-aware progressive training方式:第一阶段,模型先在密集场景描述上学习如何“记住整个空间”,形成全局3D意识;
第二阶段,再用数百万条spatial VQA数据,进一步强化方向判断、距离估计、计数、房间大小估计和路线规划等流式空间推理能力。
实验结果显示,Spatial-TTT在多个空间智能基准上都取得了非常强的表现。
在VSI-Bench上,作为一个2B规模模型,Spatial-TTT-2B取得了64.4的平均分,超过多种闭源与开源基线;
其中在Absolute Distance、Relative Direction、Route Plan、Appearance Order等任务上表现尤为突出,说明它在度量级空间估计、方向判断与路径规划等任务上具备更强能力。
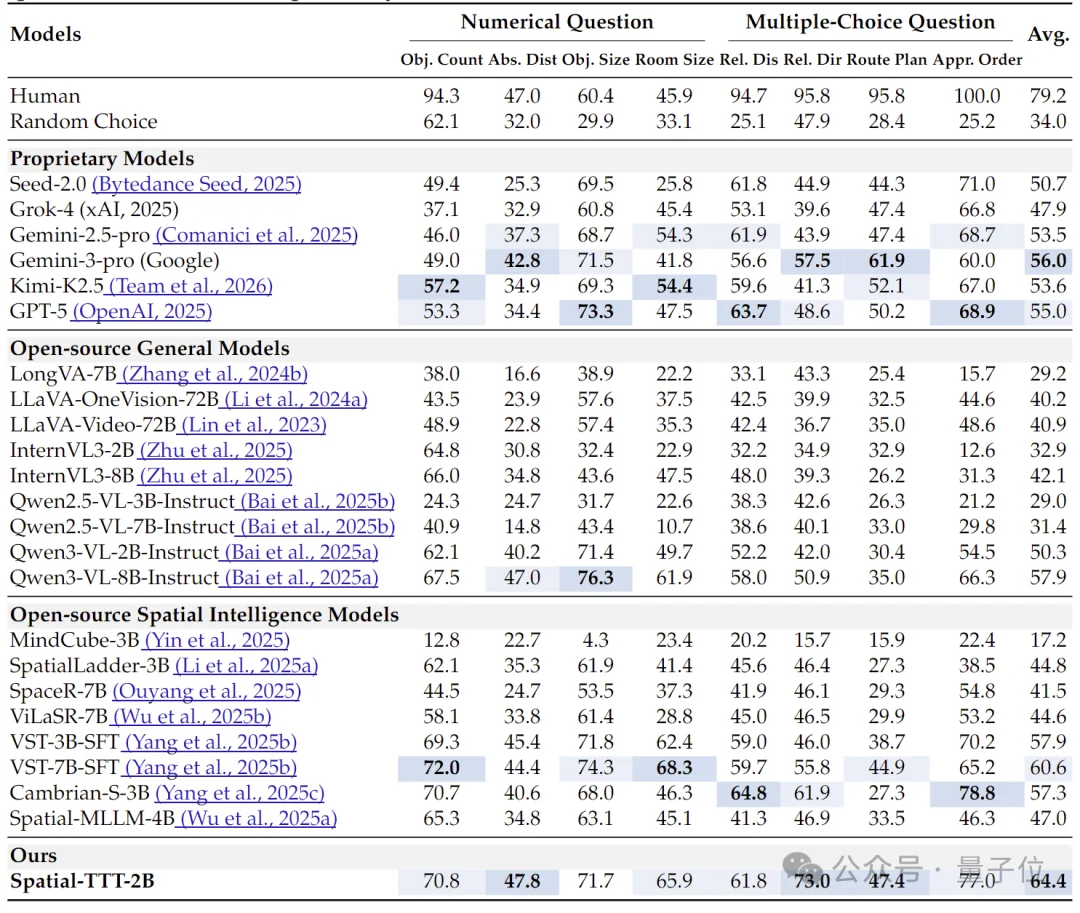
在更考验多视角细粒度空间推理的MindCube-Tiny上,Spatial-TTT拿下76.2%的准确率,比最强闭源基线Gemini-3-pro(63.9%)高出12个百分点,比代表性开源空间模型MindCube-3B(51.7%)高出近25个百分点。
论文有效证明了Spatial-TTT在视角变化与遮挡条件下展现出更稳健的空间推理能力。
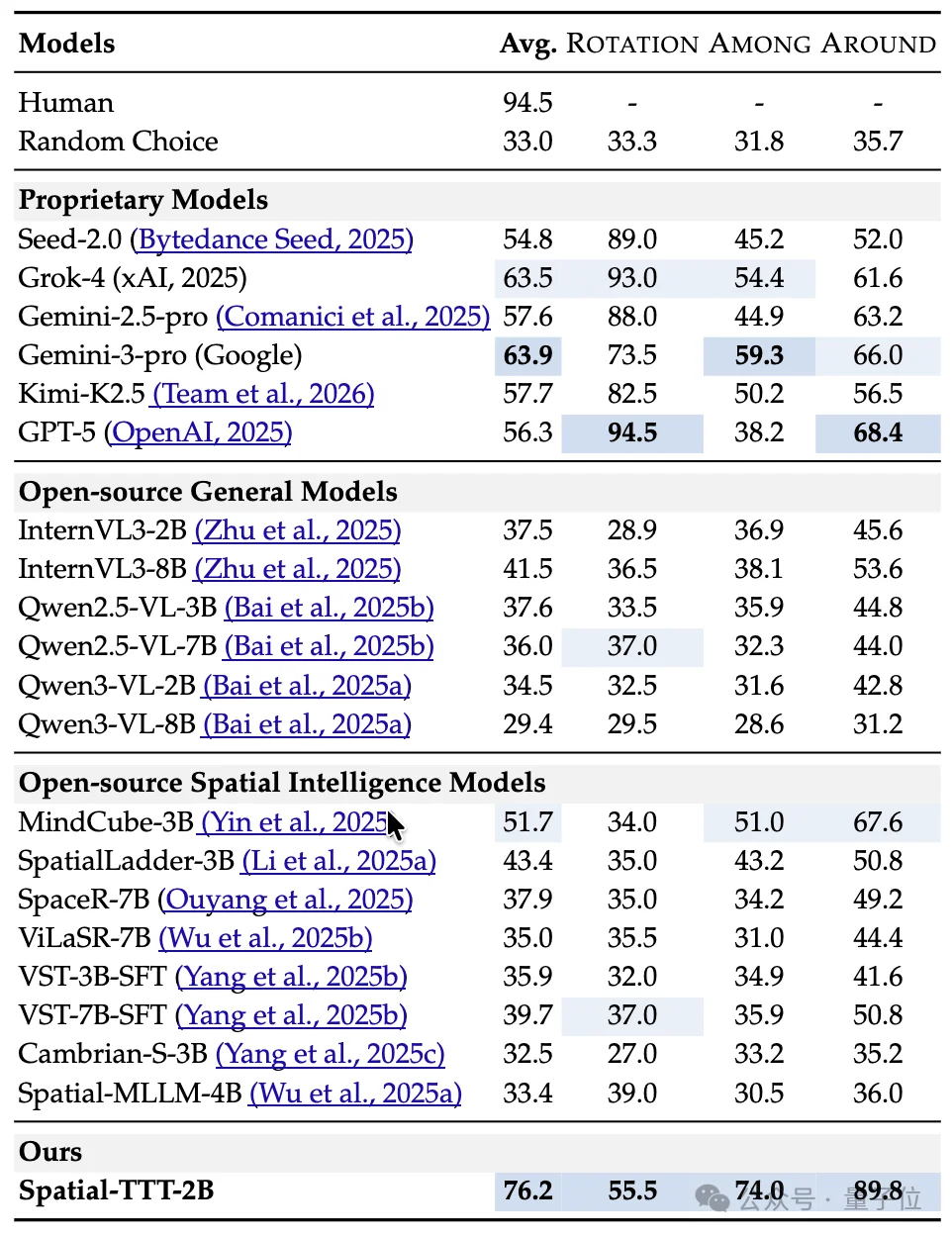
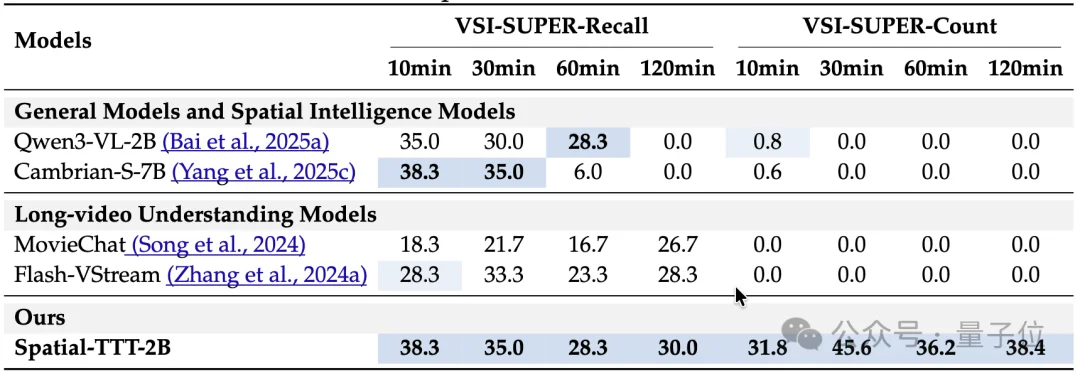
在考验“长期记忆”的VSI-SUPER系列任务上,Spatial-TTT的优势进一步被放大。
对于需要长时间累计证据的VSI-SUPER-Count,Spatial-TTT在10、30、60、120分钟视频上的得分,分别达到31.8、45.6、36.2、38.4;
相比之下,一些通用多模态模型和空间模型在更长视频上要么性能快速崩塌,要么直接OOM(内存/显存耗尽)。
而之所以能在更长时程下保持稳定,正是因为Spatial-TTT通过在线更新逐步整合新观察,而不是被动依赖一次性长上下文处理。
消融实验表明,Spatial-TTT的性能提升并不是单一技巧带来的,而是三个设计协同发力的结果:
这说明架构设计、时空归纳偏置与监督信号之间存在显著的协同效应。
效率分析同样值得关注。
在1024帧输入设置下,Spatial-TTT-2B的峰值显存占用为11.9GB,理论计算量为799.4 TFLOPs;
相比之下,行业领先的大厂模型分别为21.2GB和1403.1 TFLOPs——
也就是说,Spatial-TTT在长上下文下实现了超过40%的显存与计算节省。
此外,带显式几何编码器的Spatial-MLLM-4B在512帧和1024帧场景下已无法运行。
Spatial-TTT最值得关注的,不只是一个2B模型在多个空间智能基准上的领先成绩,它还提供了一种重新理解长视频记忆问题的方式。
传统长上下文方案试图保留更多历史内容,Spatial-TTT则进一步追问:
模型能否将持续到来的视觉观察,转化为一份能够不断更新、修正和调用的内部空间状态?
它不需要永久保存每一帧画面,却需要知道自己经过了哪里、看到了什么,以及空间关系如何随着新的观察发生变化。
这对于真正进入物理世界的Agent尤其重要。
机器人不会只进入一次房间,自动驾驶系统不会只经过一次路口,AR设备也不会只观察几秒钟的环境。
它们需要在长期运行中积累空间经验,让此前的观察真正影响之后的感知与决策,而不是在每一次任务开始时重新理解周围世界。
对于这些需要长期连续运行的Physical Agent系统而言,这项入选ECCV 2026的工作所提供的,或许不只是一个表现更强的空间智能模型,更是一条从流式视觉感知走向持续世界状态建模的路径。
更关键的变化在于,过去的观察开始参与下一次判断与行动。
当空间信息能够被持续积累、修正和调用,Agent面对的就不再是一帧帧彼此割裂的画面,而是一个具有连续性、能够被理解并进一步作用于其中的世界。
论文链接:https://arxiv.org/pdf/2603.12255
项目主页:https://liuff19.github.io/Spatial-TTT/
GitHub:https://github.com/THU-SI/Spatial-TTT/
文章来自于"量子位",作者 "允中"。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
