# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
过去一年,不少AI创业者,都会在某个时刻说“我们是 AI-native 的”,但怎么样才算是AI-native的工作流?
它既可能指,一家真正把自己的工作流,喂进了模型、越用越聪明的公司;也可能指,一家在别人的大模型上套壳、明天换个供应商就得推倒重来的公司,两者在 demo 上常常看不出区别。
微软CEO 萨蒂亚·纳德拉,上周发的那篇《没有生态的前沿,立不住》(A frontier without an ecosystem is not stable),是近期挺有意思的一篇文章。
不在于它提出了多少新概念,里面的很多要点,在近一年里大多已有讨论,而在于说它的不是旁观者,而是亲手运营着庞大 AI 基础设施的人,并且纳德拉用很朴素的语言,把两件非常重要的事情讲清楚了:一家公司怎么才算真正拥有了 AI 能力?这一轮的价值,最终会落进谁的口袋?
Satya的这篇文章,在X上获得了很高的关注
下面是这篇文章中,最值得讨论的四个要点,文末也附了全文翻译,如果感兴趣可以亲自读一读~
纳德拉这篇的一个核心观点,是说每家公司未来都要同时建两种资本:人的那部分(人力资本),和公司自己构建、真正拥有的 AI 能力(Token 资本)。
但在说这个双资本模型之前,还有一点更该先提,那就是人在背后承担责任的能力,它是其余一切的地基。
这一年大家都在争 AI 会不会取代人,但更要紧的问题是:有没有一样东西,是 AI 在结构上就接不过去的?答案是“承担责任的能力”。一个 AI 可以在能力上无限强,但它一旦做错了,板子最后总要打在一个人身上。
任何体系要运转,都得有一个能被追责的主体:一个能被剥夺资产、被追究法律与经济责任的人。AI 对惩罚是无感的,而恰恰是“可被惩罚”,才让一个人真正担得起责任。之所以把它放在最前面,正因为它是后面一切的底座。
带着这一点,再回到纳德拉的框架:首先,这一次和过去任何一次技术浪潮都不同。PC、互联网、移动、云,本质上都是在“增强”人,给人更快的工具,但人始终还是唯一干活的那个;而这一次,人和系统,第一次形成了一个真正的认知闭环(cognitive loop),系统从旁边递工具的角色,变成了和人一起干活、甚至主动提议怎么干的参与者。
正因如此,纳德拉说,每家公司未来都要同时构建两种资本:人力资本(human capital)和 Token 资本(token capital)。人力资本是人的那部分:知识、判断、人脉、创造力、模式识别;Token 资本则是这家公司自己构建、并且真正拥有的那部分 AI 能力。值得一提的是,Token 资本是五年前,根本不存在于任何公司资产负债表上的资产,如今却正在变成一家现代公司,最重要的资产之一。
而对于这两种资本的关系,纳德拉说:人力资本不会因为 Token 资本变大而贬值,恰恰相反,它只会更值钱。他甚至说,人的能动性(human agency),才是 Token 资本增长的发动机,因为是人去设定有野心的目标,在不同领域之间连点成线,去建立关系,去识别出哪些规律才真正要紧;一旦失去了人的引导,你手里那些算力,不过是在原地空转。
但纳德拉把人的价值落在“能动性”和“判断力”上,这两样恐怕都只是阶段性的优势,算不上人和 AI 的根本分界。能动性,说到底来自马斯洛那串需求,可这套“想要、然后主动去够”的机制,正在被代码复刻——proactive 的 agent、auto-research 已经在自己挖需求、自己提目标,你只要把它写进系统里。判断力也一样:人的判断很大程度上是被数据“洗”出来的,并非天生,而“从数据里学判断”恰恰是模型越来越擅长的事。
当然,就“眼下”而言,判断力确实还稀缺、还值钱——当 AI 把“执行”压成几乎零成本的商品,知道什么值得做、知道一个输出什么时候算“对了”(哪怕它技术上挑不出错)、知道一个复杂系统里高杠杆的决策点到底在哪。
这些暂时还没有公式可循,也确实正在把人分成两拨:靠执行速度吃饭的被压缩,靠判断吃饭的被放大,但它算不上长期的护城河。真正长期、暂时还卸不掉给 AI 的,还是前面那句话:谁来担责,谁可被惩罚。
这件事落到一家公司层面,就是一种全新的高杠杆形态:一小撮判断力足够强、也能为结果担责的人,外加足够多的 Token 资本,产出能顶过一支大得多的团队。这正是那批真正 AI-native 的公司如今跑出来的样子——人均产出复利式往上走,人头却越来越扁平。
说到底,未来公司的形态,是把稀缺的判断力(以及最终的那份责任)摆在正中间,再用尽可能多的 Token 资本,去把它身后的执行规模化。
那 Token 资本到底怎么“建”、怎么“拥有”?
纳德拉认为,真正的机会不在于挑那个“最强的模型”,而在于在模型之上搭起一个学习闭环(learning loop)——把公司的工作流、领域知识和长年累积的判断,变成一套越用越聪明的 AI 系统。
具体是三件东西:1)私有评估(private evals),衡量模型有没有在那些对业务真正要紧的结果上变好,而不是只盯着外部榜单;2)私有的强化学习环境,让模型基于公司内部真实的交互轨迹,持续变强;3)再加一个把机构记忆(institutional memory),变得随时可查的知识库。
他把这套机制,叫作一台不断向上、寻找更优解的“爬山机器”,或者说“它会复利”。与大多数会折旧的资产不同,每一次被改进的工作流,都会产生更好的训练信号,信号又加速沉淀那些,只属于这家公司的隐性知识(tacit knowledge),知识再回头改进下一个工作流。
打个比方:两家公司,同样的模型、同样的业务、同一个行业,五年后却可能拉开巨大的差距,区别只在于一家把这层学习沉淀了下来,另一家没有。
而模型本身,是那个可以随时替换的“输入”;沉淀下来的知识,才是抄不走的资产,把模型换掉仍然有价值。纳德拉有一句话说得很好:你可以把一项任务、甚至一整份工作“卸载”出去,但你永远卸载不掉自己的“学习与成长”。
再往深里说一层:这个所谓的“学习闭环”,本质上是对 prompt 的升级。最原始的 prompt,是你扔给模型的一句话;而最完整的 prompt,是一整个环境——它包含明确的评价标准(什么算“好”)、可读写的状态和记忆,以及在里面不断跑出来的真实轨迹。
模型更像一个“放大器”:你给它一句话,它把这句话压榨到极致(你给它一匹马,它能拼出一辆车;你给它一座城,它就能折腾出一个帝国)。所以真正的功夫,不在于挑哪个模型,而在于你能为它注入多完整的一个环境。
比“搭好一个环境”更靠前沿的问题,是这个环境怎么自我进化。最朴素的方式是线性迭代:跑一次、看结果、改一版。但已经有人在走别的路子——像 AlphaEvolve 那类做法,更接近 DNA:一次裂变出许多变体,扔进环境里去碰,留下“活下来”的,再继续裂变、再突变;围棋式的自博弈又是另一种更新方式。“怎么更新”本身,正在变成一门有讲究的手艺。
于是问题就开放在这里:一个“完整的环境”,到底是不是 context 的尽头?还是说,它外面还套着一个暂时还没看清的、更大的东西?
前面说过,护城河是那个学习闭环,而不是模型本身。
更进一步,纳德拉提出了一道检验题:一家公司,是否能换掉某个“通用型”模型,却不会因此丢失那些,早已沉淀进学习系统里的、“公司老兵”般的私有专业经验。
换句话说:如果换个模型,护城河还在不在?
这道题落到具体公司上很好用:对于一家自称 AI-native 的公司,如果把底层模型从一家换成另一家,甚至换成一个目前还不存在的未来模型,它还能保持原来的运营优势吗?系统里那些攒下来的“公司老兵”经验还在吗?编码进去的工作流、上下文和运营判断,还能像以前一样运转吗?
随着Anthropic只开放少量机构使用Mythos权限、Fable 5被封禁,“模型的可得性”突然变成了一个大问题,令无数CEO和CTO们头疼,也凸显把命脉押在某一家模型上有多脆弱。
如果换掉某个通用模型,那些一点点攒下来的“老兵经验”仍然存在,那就说明你真的建起了 Token 资本,模型对你只是个可替换的零件;如果一换就垮,那说明你所谓的护城河,其实是从模型供应商那里“租”来的——人家哪天涨了价、改了行为、关了API接口,你的壁垒一夜之间就没了。
真能过关的公司往往有几个共同点:基础设施对模型保持中立,自己的评估盯的是业务结果,而非某个模型的优势,沉淀下来的交互轨迹能换到任何模型上重放。
到这里,纳德拉还把视角从单个公司,拉到了整个经济体,而这恰恰是最重要的问题——价值最终会流向谁?
这里得先交代一个背景。表面上看,微软是 OpenAI 最大的外部投资人,似乎“最该希望价值都沉淀在模型这一层”,所以他出来主张“价值应该流到模型之上”,很容易被读成一种违背自身利益的高尚。
但其实,微软同时是模型公司的股东、是云厂商、又是调用模型的入口,这个生态里不管发生什么样的“裂变”,基本都在它的覆盖范围之内,很难冒出一个能把它卷死的东西。
换句话说,这盘棋他怎么下都赢:保底看,价值落在哪一层他都能分到;进攻看,他最舒服的局面,恰恰是模型公司别一家独大、最好 agent 公司和模型公司都很多、谁也吃不掉谁,而这正好就是纳德拉这篇文章呼吁的那个“生态”。所以与其说这是高尚,不如说,这是一个怎样都会赢的人,在为对自己最有利的格局站台。
顺带一提:马斯克对这篇的全部回应,只有一个词——“Interesting”。一个同样坐在这张牌桌上的人,留下这么一句没头没尾的“Interesting”,你大可以读出好几层意思。
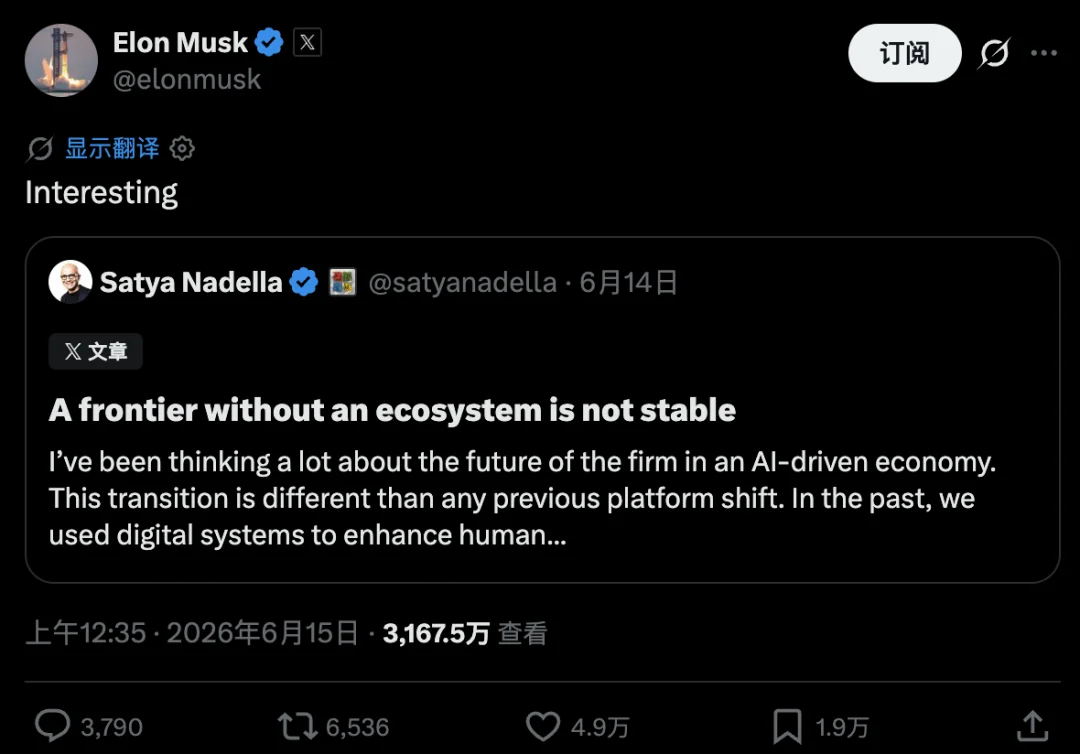
去年8月,纳德拉宣布把 GPT-5 全面接入 Copilot、GitHub、Azure 时,马斯克就撂过一句“OpenAI 会把微软活活吃掉”,而纳德拉今天这篇“别让少数模型吃掉所有人”,某种程度上像是在回应、甚至默认马斯克当年那句话。所以马斯克回应的这句“interesting”,也带有旁观者看穿棋局的轻轻一刺
纳德拉现在担心的,是这样一个世界:各行各业的每一家公司,都把自己的价值拱手让给少数几个“见什么吞什么”(eat everything they see)的模型。
被吃掉的不是别的,正是各个行业辛苦攒下的专业知识、判断和 IP资产,一旦这些被商品化、被从脚下一点点抽走,公司就再没有什么能让自己区别于竞争对手。
在他看来,如果所有价值,最后只汇到极少数模型公司手里,整个政治经济根本不会容忍;一个把整个产业彻底掏空的 AI 未来,是拿不到社会许可(societal permission)的。
他特意搬出全球化的第一阶段来类比:当年一个个工业经济体,被外包掏空,GDP 数字表面上还挺好看,可它对就业、对整个产业的冲击是真实的,直到今天仍然有人在为此付出代价。这套剧本,不该在 AI 时代再演一遍。
而历史的经验是,这样的清算迟早会来,区别只在于,是这个行业趁着现在还在赚钱时主动调整,还是等到被一场危机逼着调整。
说到底,摆在面前的是两种结局:要么价值高度集中到极少数模型手里,要么它宽广地分布到许多层——云厂商、平台搭建者、各垂直行业的 AI 公司、开源生态、基础设施,以及一整批在这套底座上长出来的新公司,乃至整个社会。唯有如此,价值才能流向每一家公司、每一个行业、每一个国家。
这背后,其实是一条很朴素的“平台价值观”:一个平台健不健康,要看长在它上面的价值,是不是远多于它自己抽走的那一份。
这也正是纳德拉文章标题的意思:没有生态的前沿,立不住(A frontier without an ecosystem is not stable)。
作者:萨蒂亚·纳德拉(Satya Nadella,微软董事长兼 CEO)
@satyanadella
我最近一直在想一个问题:在 AI 驱动的经济里,企业的未来会是什么样子。
这一次的转变,和以往任何一次平台变革都不一样。过去,我们用数字系统来增强人力资本;这一次,我们第一次能在人和数字系统之间建立起一个认知闭环(cognitive loop)。这件事很颠覆认知,因为它改变了我们对企业内部“工作”本身的理解。
这里真正要紧的,不是某个数字工具或系统怎么用,而是:在一个 AI 模型能不断吸收人和组织的专业知识、再把它商品化的世界里,组织要怎么持续学习、构建 IP、做出差异化,并且活得好。
每家公司都将不得不构建两样东西,我把它们叫作人力资本(human capital)和 Token 资本(token capital)。人力资本,是员工的知识、判断、人脉、巧思和模式识别;Token 资本,是这家公司自己构建、自己拥有的 AI 能力。
要紧的是,人力资本不会因为 Token 资本变大而贬值。恰恰相反,它只会更值钱!我相信,人的能动性(human agency)会成为 Token 资本增长的驱动力。是人在设定有野心的目标,在不同领域之间连点成线,建立关系,识别出最要紧的规律。没有人的引导,算力不过是在原地空转。
这意味着,真正的机会不在于挑那个“最好的模型”,而在于在模型之上搭一个学习闭环(learning loop),让人力资本和 Token 资本在里面复利累积。你可以把一项任务、甚至一整份工作卸载出去,但你永远卸载不掉自己的学习。企业的未来,就看它能不能让这种学习在人和 AI 之间不断复利。
要做到这一点,需要一套新的架构思路:让每家公司都能搭出会随时间不断自我改进的智能体系统(agentic systems),同时仍然掌握着对自己 IP 的控制权。一家公司,应该能换掉某个“通用型”模型,而不丢失那些已经沉淀进它学习系统里的“公司老兵”经验。这就是检验你在未来掌不掌握控制权与主权(control and sovereignty)的试金石。
公司要把自己的工作流、领域知识和长年积累的判断,变成越用越聪明的 AI 系统。私有评估(private evals)要衡量的是:一个模型有没有在那些对业务真正要紧的结果上变好,而不是只看外部榜单。私有的强化学习环境,要让模型基于组织内部真实的交互轨迹变得更强。它的知识库,让机构记忆随时可查,也让 token 用得更省。
这个闭环,会成为公司新的 IP。我把它看成一台爬山机器(hill climbing machine):不断往更优解上爬。而且和大多数会折旧的资产不一样,它会复利。每一次工作流被改进,都会产生更好的训练信号,信号又加快沉淀这家公司独有的隐性知识,知识再回头改进下一个工作流。越早把这套机制搭起来的公司,优势越难被复制;而且不管以后单个模型的能力又跳了多大一步,这个优势都还在。
我们谁都最不愿意看到这样一个世界:每个行业、每家公司,都把自己的价值拱手让给少数几个“见什么吞什么”的模型。如果所有价值最后都汇到极少数模型手里,整个政治经济根本不会容忍。一个把整个产业掏空的 AI 未来,是拿不到社会许可(societal permission)的。
想想全球化的第一阶段:一个个工业经济体被外包掏空。表面上 GDP 数字还挺好看,但那种错位是真实的,它的后果到今天还有人在承受。千万别让这一套在 AI 时代重演:少数几个 AI 系统拿走全部经济回报,一个个完整的产业,只能看着自己的知识被商品化、从脚底下被一点点抽走。
在我看来,我们的首要任务,是建一个前沿生态(frontier ecosystem),而不只是一个前沿模型,这样价值才能宽广地流到每一家公司、每一个行业、每一个国家。在这样的生态里,每个组织都能拥有自己的学习闭环,把自己的机构知识编码进去,让人力资本和 Token 资本一起复利。
这是我一直信奉的理念:好平台让别人在它上面创造的价值,远大于它自己拿走的那一份;在这样的平台上,每家公司都能不断创新,长出自己的价值。
等这一切发生,公司既会为自己创造价值,也会为周围的经济创造价值。员工会看到自己的专业能力被放大,他们的判断也会进入某种系统,被复制、被规模化;而这些好处,会落到他们身边的公司和社群身上。
这就是公司为自己、也为更大的经济创造价值的方式。这也是我们应该一起建起来的那个稳定均衡(stable equilibrium)。
文章来自于微信公众号 “五源资本 5Y Capital”,作者 “五源资本 5Y Capital”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
