# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

如果我们谈到 AI 赋能带来的科学突破,AlphaFold 一定是不可忽略的一项。它解决了困扰生物学界半个多世纪的蛋白质折叠难题,大量压缩了得到蛋白质结构的时间,从原来的一年,到现在的几分钟。它的核心开发者之一 John Jumper 也因这一贡献在 2024 年摘得诺贝尔化学奖。
乍看之下,AlphaFold 似乎是另一个 Scaling Law 的佐证,足够大的模型,足够多的数据,涌现出惊人的突破。而这就关联出 AI 圈近年来反复被提及的理念:“苦涩的教训”(the bitter lesson),即凡是依赖人类领域知识和人工设计的方法,长期来看都会被纯算力和数据击败。
但 Jumper(前 Google Deepmind 科学家,现已加入 Anthropic)本人在最近与 Machine Learning Street Talk 的访谈中亲口否认了这一点,他认为 AlphaFold 的成功并不来自于无脑堆算力。相反,它的成功是对“苦涩的教训”的有力反驳。
AlphaFold 解决了什么
为了更好地理解 AlphaFold 带来的突破,我们需要先回到蛋白质上。蛋白质最初是一条长链,由二十种氨基酸像字母表一样串接而成。这条链一旦合成完毕,就会自我组装;通过扭曲、盘绕和折叠,形成一个紧凑而独特的三维形状,里头有螺旋、有折叠片。而正是这个最终形状决定了它的功能。Jumper 喜欢这样比喻:这就像一个宜家书架,打开包装箱的瞬间,它就开始自动成型。
(来源:DeepMind)
蛋白质相关研究的难点在于蛋白质结构复杂,需要大量人力物力的投入。过去科学家只能先把蛋白质结晶,再依赖体积庞大的同步加速器,产生超高亮度的 X 射线去做结构分析。
这个摸索过程非常耗时,往往要耗上数年。Jumper 回忆,有些学生直到博士快毕业了,做汇报的进展还只停留在某个蛋白质的“结晶过程”。同时他们心里明白,也许他们毕业了也没能等到“结晶”结束。在这个问题中,无数科学家投入了大量的资源,最终也只积累了大约二十万个结构数据。在 AlphaFold 立项时,这个数字还只有十四万左右。
AlphaFold 的突破体现在三个层面:它的预测误差缩小到了原子半径级别,精度开始足以媲美传统实验方法; 速度从一年缩短到五到十分钟; 规模的进展是最为惊人的,AlphaFold 团队已经预测了两亿个蛋白质的结构,几乎囊括了地球上所有已测序生物体内的每一种蛋白质,并且向全球免费开放。
Jumper 说,AlphaFold 的意义不仅在于它科学层面上的突破,更在于它的示范性,我们究竟该如何利用 AI 解决人类的科学难题。
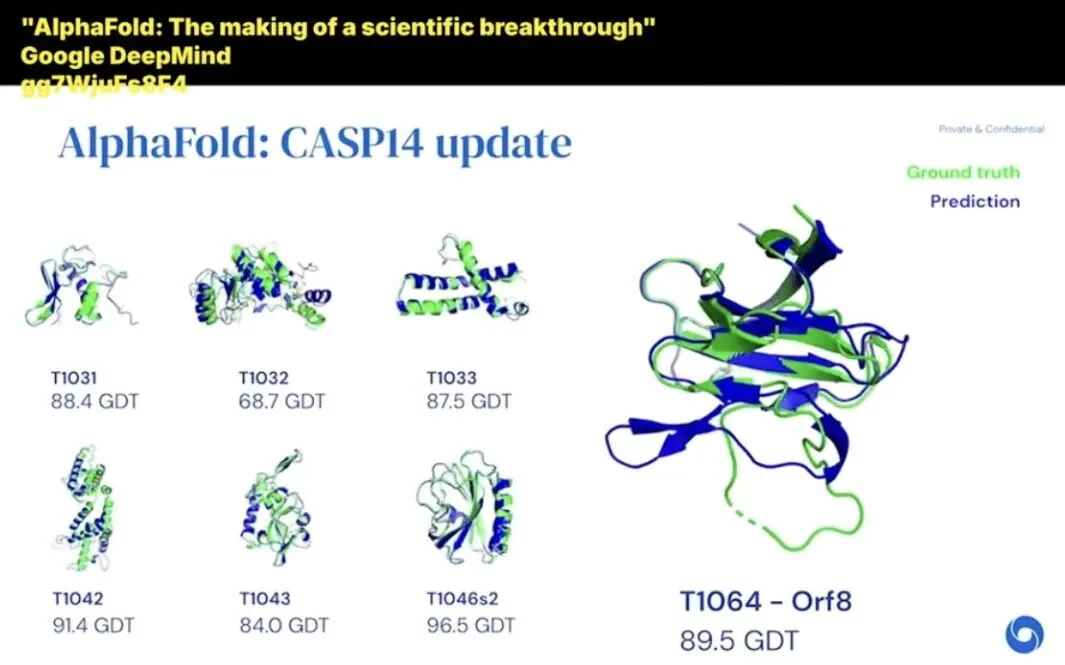
(来源:Machine Learning Street Talk 访谈视频截图)
从结构到生物: Midnolin 蛋白的启示
Jumper 谈到,结构本身只是起点。从“拥有结构”到“真正搞懂生物学”之间,中间还有很长的路。
他举了一个让他印象深刻的例子。几年前有一项研究,探讨细胞如何回收清除废弃的蛋白质。研究者发现,在细胞发育的某个阶段,有数百个基因被关闭了,但不知道具体涉及到哪些蛋白质。通过遗传学分析,他们锁定了一种此前几乎无人研究过的蛋白质:Midnolin。而它的运作方式不符合任何已知的标准路径。
于是他们运行 AlphaFold,把 Midnolin 和受敲除影响的近五百种蛋白质一起输入做联合预测。团队惊讶地发现,约 40% 蛋白质呈现出一个非常独特的模式:目标蛋白质的某个部分,被死死卡在 Midnolin 的两个部分之间,就像被一把铁钳夹住。
研究人员随后回到实验室继续验证:把 AlphaFold 预测中“被夹住的位点”人工移除,降解立刻停了。研究人员总共测了 10 个样本,9 个完美吻合结论。但第 10 个的结果只是部分减弱,于是他们回头复核,发现 AlphaFold 实际识别出了两个结合位点; 当把第二个位点也移除后,降解现象便彻底消失了。就这样,科学家对一种新蛋白质建立起了机制层面的理解。
Jumper 强调,AlphaFold 在研究里最核心的贡献,是精准锁定那些我们尚不了解其重要性的蛋白质。他用了一个老套的比喻,工厂里最重要的机器罢工了,技术员走进来,径直拧了某颗螺丝四分之一圈,机器立刻恢复轰鸣。
但仅仅只是这么一个简单的动作,它的维修费却可能高达一万美元。因为拧螺丝本身只值五毛钱,而知道该拧哪里值剩下的九千九百九十九块五。Jumper 说,这和如今药物制造的困境很像,在庞大复杂的细胞工厂里,人们需要具体弄明白到底是哪一处出了问题。
主持人随即提出了一个机器学习圈普遍的担忧:人体结构非常复杂,干预一处,别的机制立刻补偿。因此,会不会出现生物学版的“打地鼠”的场景?Jumper 的回答是,正因如此,AlphaFold 才必须保持克制:
“我们并不企图解释一切,更不是整个细胞的通用模型。你以前做这种实验可能要花上一年,而我们只是这个实验结果的预测器。”
在他看来,AlphaFold 的价值恰恰在于它的窄。它能非常精准地量化自己复现某个实验结果的能力,然后把这台机器交给研究者,由他们自己去探索用处。研究者会以团队意想不到的方式使用它:跑成千上万次预测,去寻找能相互结合的蛋白质对,去挖掘复杂系统里的未知成分。
反对“苦涩的教训”
接着,主持人问起 AlphaFold 各版本架构是怎么一步步演进的,并且特意提到外界对几何深度学习、对 SE(3) 对称性的津津乐道。很多人把 AlphaFold 2 的成功,归到这些很酷的概念上。
Jumper 先是把 AlphaFold 发展的脉络捋了一遍:AlphaFold 1 用的是在计算机视觉里开发好的现成 CNN,所有针对蛋白质的特殊处理,不过是包在外面的一层补丁。到了 AlphaFold 2,核心理念变了:它要针对蛋白质折叠这个任务,从头搭一个科学架构。
于是就有了那个庞大的主干 EvoFormer。它利用了一个事实:蛋白质演化极其缓慢(人体内的蛋白质结构,往往和酵母菌、甚至大肠杆菌里的极其相似),所以能抓来成百上千条进化相关的序列,这便可以在“几何认知”和“演化认知”之间搭起桥梁。
这一主干占用了 90% 以上的计算量,但也贡献了 90% 以上的准确率。再往后,是被 Jumper 称作“几何化引擎”的结构模块,里头有巧妙的“不变点注意力机制”(IPA),和一个起了决定性作用的损失函数,“框架对齐点误差”(FAPE)。
外界一口咬定,等变性(equivariance)和 SE(3) 不变性就是 AlphaFold 2 能成功的唯一原因。Jumper 并不认可,于是索性做了一大堆消融实验,把各个组件一个个关掉,看结果会如何发展。
他发现 AlphaFold 2 在 GDT 指标上比 AlphaFold 1 高出大约 30 分;而把不变性和等变性拿掉,顶多也就损失 2 到 2.5 分。Jumper 无奈地说,“它确实有贡献,可这只是 30 分里的 2.5 分而已。我本以为这足够平息争论了,结果并没有。”
人们照旧把 AlphaFold 2 捧成等变性的伟大胜利,对真正要紧的 FAPE 只字不提,反倒揪着一个等变 Transformer 不放。在这件事上,Jumper 把自己形容成一个“极度冷酷的实证主义者”。
他认为是全局 SE(3) 对称性其实算不上一种很强的对称性,跟“所有残基都是置换不变的”那种量级根本没法比;它只是一个乱糟糟的现实问题里冒出来的对称性,起不到物理学里那种从对称群一路推出整套定律的决定性作用。
有一回团队在处理成对信息时,把轴向注意力和卷积混着用;后来有人干脆把所有卷积层都删了,一个参数没加,总参数量实打实地降了下来。结果模型反而更准,验证损失也改善了。还有消融实验显示,把原始遗传信息去掉、改用成对相关性,性能也就掉一两分。
而可解释性分析又发现,AlphaFold 大部分的模型容量,都花在了从几何层面去优化结构上;过了最初几层之后,它更像一个“几何引擎”,而不是“进化引擎”。这些洞见后来全被带进了 AlphaFold 3。团队选择大刀阔斧砍掉 EvoFormer 的层数,换成简化版的 Pairformer,性能反倒上去了。
也正是由此,Jumper 表明了他对“苦涩的教训”的反对:AlphaFold 2 在架构和训练上注入的那些定制化创新,换来的是 100 倍的数据效率飞跃;AlQuraishi 实验室曾经只用 1% 的 PDB 数据(大约 1,500 个结构)重训 AlphaFold 2,准确率竟然就超过了 AlphaFold 1。所以他认为,AlphaFold 带来的启迪绝不是学者不该继续做架构研究。
扩散模型
谈到一年前发布的 AlphaFold 3,外界又习惯性地贴上一个标签:扩散模型。Jumper 再次表示要在概念层面提出异议,他不喜欢简单地把 AlphaFold 3 称作一个扩散模型,因为这会重复“因为它是 Transformer 所以才有效”那种过度简化的理解。
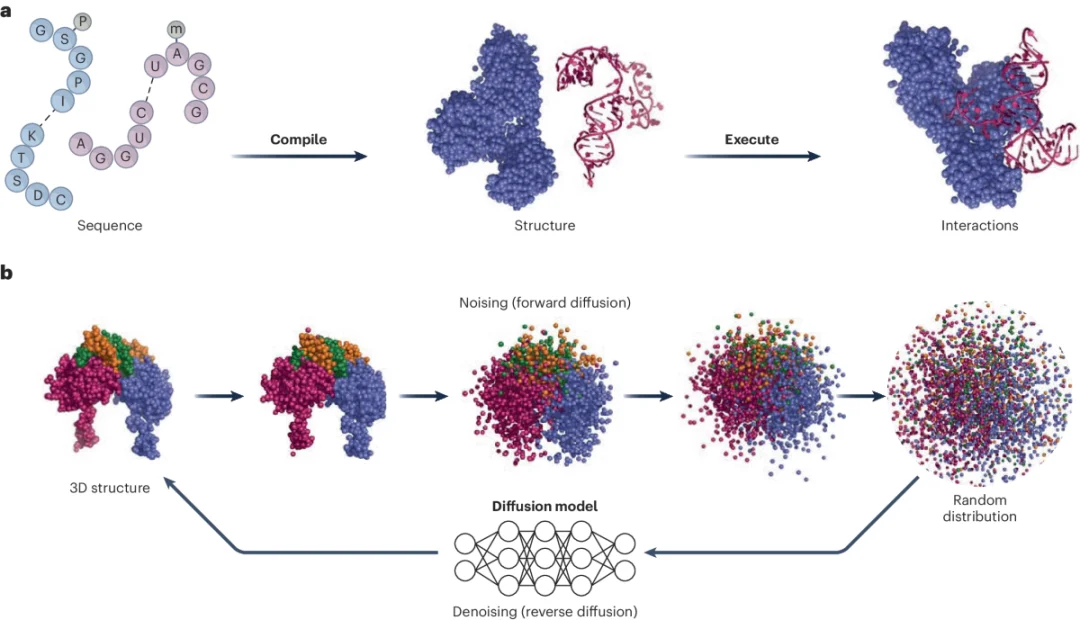
(来源:Nature)
AlphaFold 3 的真正突破,是从只盯着单个蛋白质,扩展到整个蛋白质电影宇宙:蛋白质会和胆固醇这样的脂质分子结合,也会和药物(通常是二三十到五十个原子的小分子)结合。AlphaFold 2 不能回答“这种药物如何结合”的问题,它只会说“你最好给我一个蛋白质”;而 AlphaFold 3 把模型扩展到了 PDB 里出现的所有物质,所以能指出药物结合的精确位置。
至于其中的扩散过程,Jumper 强调它和图像领域的扩散截然不同。AlphaFold 3 有一个巨大的、只运行一次的主干网络,这部分根本不是扩散;分子结构很可能就是在这里被决定的。扩散过程扮演的角色,更像当年的结构模块:一台“几何化引擎”,接收一组相当精准的约束,对整体结构已有清晰的宏观概念,再据此求解微观细节。
他举了一个很妙的对比。图像扩散是先生成一堆彩色色块,到后期才决定这些色块代表什么意思;你甚至能中途叫停、重新运行,对同样的色块得出截然不同的解读。但蛋白质不行。对蛋白质而言,宏观的大尺度结构才是最难的部分。
AlphaFold 2 是凝聚式地工作:先搞定最容易预测的局部碎片,再慢慢拼装成整体。而 AlphaFold 3 的扩散网络必须反过来,率先跨过“两个蛋白质如何相互结合、它们主干的相对位置在哪”这道门槛。它靠的是前面庞大的主干加上扩散网络的第一遍前向传播,先求解出整体宏观结构,之后的扩散过程只是在敲定那些尚未解决的细枝末节、在各种可能的细节里采样。
所以,尽管技术上它确实是扩散模型,但其内在逻辑远比想象中更接近 AlphaFold 2。Jumper 真正想表达的是,纠结“它是扩散模型还是 Transformer”远不如理解那些关键的技术细节来得重要。
预测、控制与理解
Jumper 在访谈中区分了三件容易混淆的事:
预测:我要做一件事,未来我的屏幕上、我的仪器上会出现什么数值。
控制:我希望未来测到的那个值是 17,那我应该如何干预。
理解:它和预测很像,区别在于有人类参与循环(human in the loop)。理解意味着我只掌握极少量事实,你就能据此预测,而且能用紧凑的形式,把它传达给另一个人。
Jumper 认为机器赋予了我们预测和控制的能力,但理解这件事,仍然必须由人类自己去推导和构建。我们可以拿这两亿个预测结构当作实验对象去研究、去帮助理解,但机器本身并不能替我们完成“理解”这个动作。
由此,他还引出一个机器学习里极重要的概念:世界上有两种算法,一种是你亲手编写的;另一种是你最终训练出来的。
机器学习的本质,就是代码与数据相遇、凝结成权重的过程。而长久的争论在于,最终的本领里有多少归功于代码,多少归功于沉淀在权重里的数据。AlphaFold 的迷人之处在于,它最终学会的算法是一种我们能够理解、能用寥寥数语讲清楚的算法:连续的几何精炼。
智能与表征
访谈的最后落到了一个更宏大的问题:这一切发展对通用人工智能意味着什么。Jumper 的态度一如既往地克制。

(来源:Youtube)
他认为,以显式方式去设定“表征”的重要性,已经远不如五年前人们以为的那样了。AlphaFold 就是证据。代码强制它做的,它固然会做;但它许多惊艳之举,并非出自代码的强制规定。为了把数据预测得足够准,它必须自己去寻找优质的中间表征。
机器学习曾长期沉迷于一种诱惑:既然我知道最终一定需要某个概念,就在网络里专设一个单元去命名它、强制中间层生成解耦表征。但后来人们发现,许多曾被认为“智能”必不可少的要素,仅仅在模型精准预测下一个 token 的过程中,就自然涌现了。
用 Jumper 的话说:它们涌现,不是因为你在预测下一个 token,而是因为你把预测下一个 token 这件事做到了极致。
代价是 Scaling Law 里那条大家最不喜欢的对数线性关系,往往要投入指数级的算力和数据,才能换来能力的线性提升。
Jumper 这样理解当下未解的核心问题:我们的确获得了这些概念和表征,但如何才能用更低的成本获得它们?今天我们能用软件脚手架给模型外挂记忆、不断提醒智能体当下的目标,来修补它的固有缺陷;可我们还不知道,如何把这些外部能力无缝“蒸馏”回神经网络内部,让它本身具备不再依赖外挂的本领。
这大概是 AlphaFold 这个故事最有意思的地方。一个刚刚为人类破解了半个世纪难题并因此封神的系统;它的缔造者却始终拒绝把它供上神坛——等变性没那么神,扩散模型没那么神,“理解”这件事本身也远没有被解决。Jumper 在乎的始终是那些不起眼的笨功夫,以及从预测到控制、再到人类自己去构建理解的那段距离。
参考链接:
https://www.youtube.com/watch?v=e3gBwLWAerw
文章来自于微信公众号 “DeepTech深科技”,作者 “DeepTech深科技”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
