# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
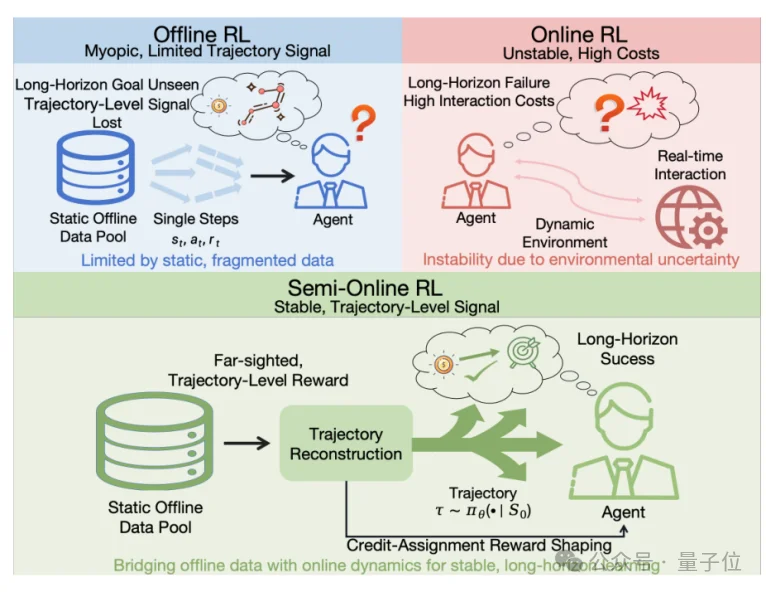
想训练能自动操作手机的GUI(图形用户界面)智能体,总会遇到两难困境:
为破解这一难题,vivo AI Lab联合之江实验室、中国科学院大学杭州高等研究院,提出半在线强化学习框架SOLAR-RL。
它不依赖昂贵的在线环境交互,而是把全局轨迹信号直接“回填”进离线学习过程,在多个基准上以约10%的数据预算取得了与在线/SFT强基线相当甚至更优的表现,同时彻底规避了长程RL训练中常见的策略崩溃。该工作已经被ACL 2026 会议接收。

在长程GUI任务上应用RL,两条主流路线各有硬伤:
两条路线还共同卡在信用分配难题(Credit Assignment Problem,CAP)上:一条长轨迹结束时只有末端一个“成功/失败”的二元信号,无法判断到底是中间哪一步推理立了功、哪一步操作拖了后腿,梯度因此稀疏而嘈杂。我们的思路是:能否既保留离线训练的稳定性,又把通常只有在线交互才具备的轨迹级全局信号补回来?SOLAR-RL正是这一“半在线”范式的具体实现。
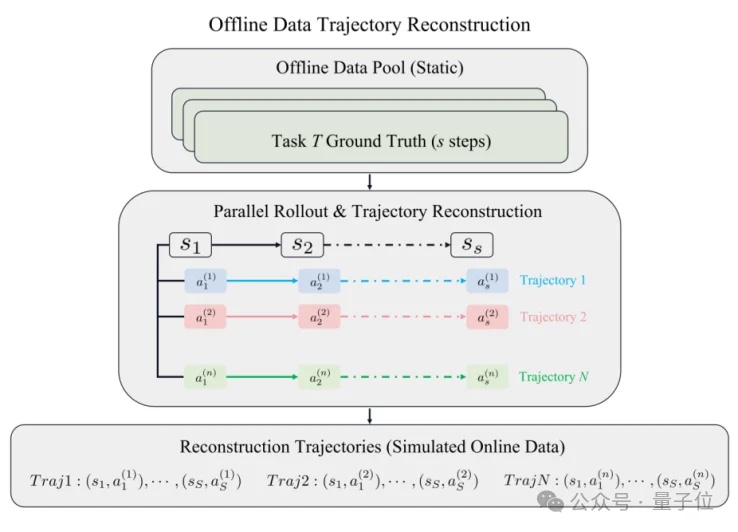
我们将GUI导航建模为部分可观测马尔可夫决策过程(POMDP),SOLAR-RL由两个关键组件构成。
对同一任务,我们在每一步并行采样N条候选rollout,再把相同索引的候选首尾相接、拼成N条“重构轨迹”,从而把有限的静态数据扩展成一批多样化的“伪在线”探索数据。其中关键的一点是:每条轨迹都按逐步有效性(per-step validity)逐帧核验,一旦某步动作被判无效,轨迹便在这个“首次失败点”被截断、丢弃其后步骤。有效性判定采用基于真值标签的严格协议——坐标类动作用高斯核度量、文本输入用F1分数、应用启动用相似度阈值、系统类动作用精确匹配,既剪掉低质量偏差,又保留探索多样性。
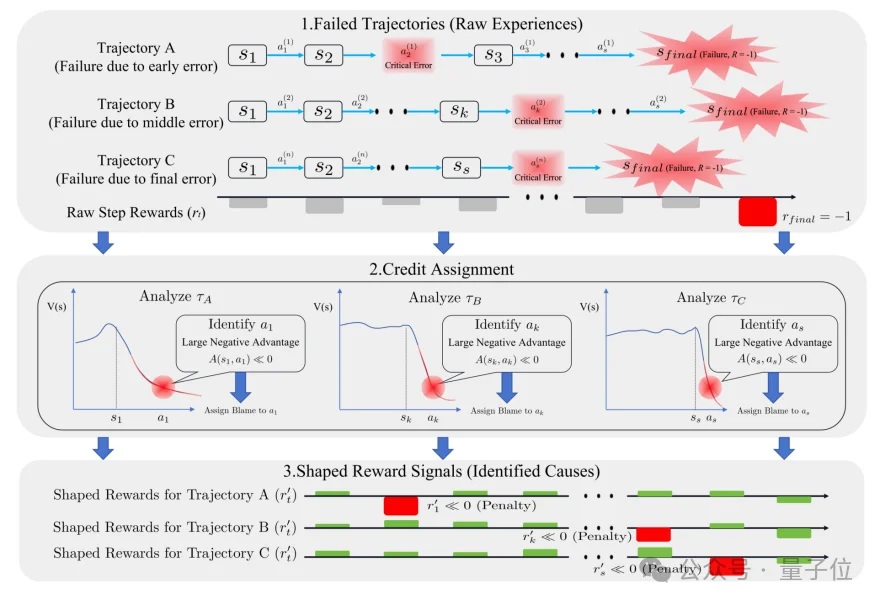
这是SOLAR-RL的核心贡献,把“整条轨迹的执行质量”回溯性地拆解为稠密的步级奖励,包含三层设计:
如此一来,SOLAR-RL在零环境交互的前提下,产出稠密、稳定、且与全局目标对齐的训练信号,相当于在静态数据上“模拟”出了在线反馈。
我们以Qwen2.5-VL-7B-Instruct为基座、基于verl框架,仅用15k条高质量静态轨迹(约94k步)训练,每步采样N=8、温度1.0,在32张NVIDIA L40S上训练650步、约60小时,并在三大基准上进行了评测。
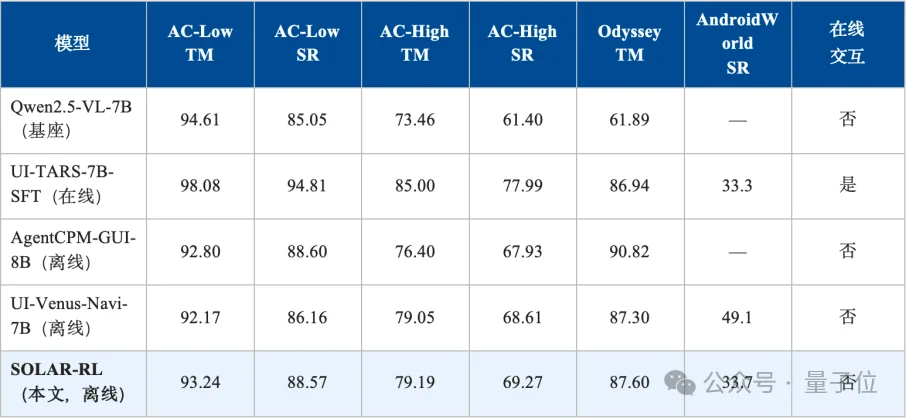
在离线类方法中,SOLAR-RL在Low划分上取得93.24%TM/88.57%SR;在更考验多步推理的High划分上,以69.27%SR拿下离线类方法的最高分,超过UI-Venus(68.61%)与AgentCPM(67.93%),表明轨迹感知信用分配能有效防止复杂任务中的推理退化。
在以长链路、跨应用著称的GUI-Odyssey上,SOLAR-RL取得87.60%TM。尽管AgentCPM此项原始指标略高,但它使用了超过55k条轨迹——是本文(15k)的三倍多,反衬出我们方法的样本效率。
在最具挑战的动态基准AndroidWorld上,SOLAR-RL取得33.7%SR,位列离线类第二;更值得注意的是,它在完全不做在线交互的情况下超过了使用145k轨迹的在线方法UI-TARS-7B-SFT(33.3%),而训练数据量仅约为对手的10%。这说明:堆原始数据规模并非提升性能的唯一路径,把学习信号“精炼”好同样关键。
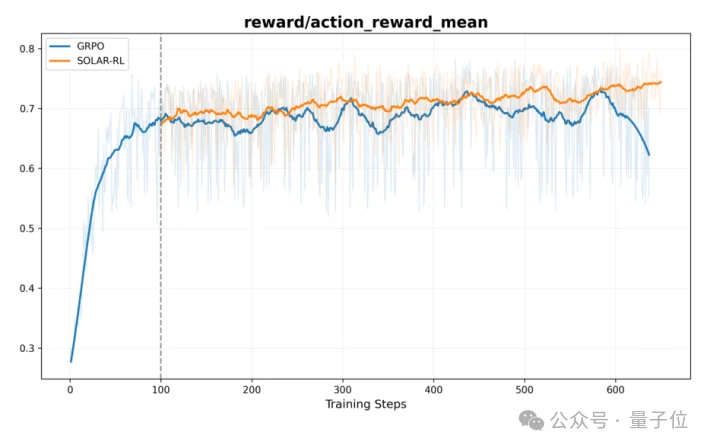
与强基线GRPO的对比很能说明问题:GRPO早期会涨,但在约600步后出现典型的“策略崩溃”——奖励断崖式下滑、智能体陷入无效循环;而SOLAR-RL的平均动作奖励单调上升,最终稳定收敛在约0.75的更高水平。在PressBack(回退纠错)这类关键动作上,GRPO剧烈震荡、迟迟学不会“何时该后退”,SOLAR-RL则快速收敛到0.8以上的高精度,有效避免了导航死循环;在“超长(≥14步)”任务上,这一稳定性优势进一步放大。
论文给出的一个训练案例颇具代表性:在Simple SMS Messenger里“把刚发给Juan Alves的消息重新发一遍”。
轨迹一:智能体先在会话列表里误用长按(错误),随后纠正、进入正确的聊天页(第一次纠错成功);但当它发现“长按已发送消息”也无效时,却没能切换到“重新输入并发送”的正确策略,于是被困在一个看似合理、实则走不通的行为里——任务失败。
轨迹二:起步几乎相同,但它完成了连续两次纠错——先从会话列表切到正确的聊天页,再果断放弃无效的长按、改为重新输入并发送,最终成功完成任务。
这揭示了长程GUI任务的本质:成功不在于“一次都不犯错”,而在于“能否一错再纠、连续从次优状态里爬出来”。这正呼应了SOLAR-RL的设计动机——失败点信用分配帮助定位轨迹从哪一步开始走偏,轨迹感知奖励塑形则抑制智能体在失败后继续重复无效动作链,鼓励它放弃无效局部行为、重新回到有效决策路径上。
我们也坦诚指出了方法的边界与下一步:
其一,半在线机制受限于离线数据的覆盖面,无法见到分布之外的全新状态(如未见过的弹窗、延迟引起的界面变化),它“模拟”在线反馈但并不替代真实环境交互;
其二,当前有效性校验依赖真值标签,未来可替换为学习型验证器或奖励/评判模型,从而拓展到弱标注、无标注的GUI数据;
其三,目前评测主要集中在移动(Android)环境,将轨迹感知奖励塑形推广到动作更丰富的桌面操作系统与网页浏览器,还需要平台特定的有效性标准与基准。这些都是我们后续探索的方向。
论文标题:SOLAR-RL: Semi-Online Long-horizon Assignment Reinforcement Learning
论文地址:https://arxiv.org/abs/2604.22558
文章来自于"量子位",作者 "vivo AI Lab团队"。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
