# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

导语
2026年6月17日,Nature 刊登了一项里程碑式的研究,来自海德堡大学医院的研究团队开发了一个名为MIRA(Medical Intelligence for Reasoning and Action) 的自主医疗AI智能体。与以往仅能提供文字建议的聊天工具不同,MIRA是首个能够在沙盒化电子健康记录(EHR)环境中,独立完成从问诊、检查到治疗、入院全流程的AI系统,其诊断准确率达到88%以上,显著优于专科医生团队的78%。在468条用药医嘱中未出现任何严重药物相互作用或剂量错误,且对需收治患者的识别召回率达到100%。尽管目前仅在模拟环境中运行,但该研究标志着AI从辅助工具向具备执行能力的临床智能体迈出了关键一步,其未来应用有望将医生从重复性事务中解放,聚焦于更具人文价值的医疗环节。
关键词:医疗自主智能体(Medical AI Agent)、电子健康记录(EHR)、沙盒电子病历(Sandboxed EHR)、MIRA(Medical Intelligence for Reasoning and Action)、临床全流程决策、诊断精度、医疗指南依从性、用药安全

论文题目:Nature: Towards autonomous medical artificial intelligence agents
论文链接:https://doi.org/10.1038/s41586-026-10675-5
发表时间:2026 年 6 月 17 日
论文来源:Nature
尽管大语言模型(LLMs)已经能够在医疗问答、影像判读、临床推理测试中取得接近甚至超过医生的成绩,医疗领域也涌现出一批能够检索诊疗指南、整理病历、自动生成疾病编码的辅助工具,但它们至今仍难以独立完成一次完整的临床接诊。
原因在于,绝大多数医疗 AI 仍停留在 “被动答题者” 阶段:它们擅长回答问题,但这样只能处理零散、割裂的单一诊疗小事,没办法像真实医师一样,在电子病历系统中持续采取行动,从问诊获取病史,到开具检查、整合结果,再到制定治疗方案和安排入院,每一步都需要根据最新信息动态调整决策。换句话说,现有系统大多只能完成某一个孤立环节,而无法贯穿整个诊疗流程。
标准临床诊疗是一套闭环决策流程:医师依托电子健康记录(EHR)持续采集和更新患者信息、开具各类检验影像,在不断获得新证据的过程中形成并修正诊断假设,最终执行药物治疗、手术干预或住院管理。重要的是,这些决策最终都必须转化为电子病历系统中的结构化指令,并通过快速医疗互操作性资源(FHIR)等统一标准完成规范化记录。因此,真正进入医院工作流的医疗 AI,不仅要具备临床推理能力,还必须能够持续调用工具、执行操作并动态调整决策——这正是AI智能体(AI Agent)的技术范式。
过往不少研究已经尝试让医疗AI从“回答问题”向 “采取行动” 靠拢。例如:AMIE 等系统显著提升了优化医患对话质量,但仍局限于问诊场景,无法调取病历、开立检查;OpenAI联合企业推出的基层医疗辅助工具虽然能够嵌入临床工作流,却不具备自主操作权限;基于MIMIC-IV数据集的研究开始模拟完整诊疗流程,但由于缺乏与FHIR等通用医疗体系的深度整合,也未覆盖医患沟通、入院用药核对等关键环节,最终普遍认为,现有模型仍难以可靠地自主完成复杂病例管理。
综合来看,医疗 AI 领域始终存在两大核心空白:其一,缺少能原生嵌入现有EHR体系、真正实现端到端诊疗闭环的自主智能体;其二,尚无研究系统验证AI在沟通、诊断、治疗、入院分流等完整临床链路中的综合性能与安全边界。也就是说,医疗 AI 面临的真正挑战,从来不是能否回答医学问题,而是能否在真实医院工作流中持续采取行动。
和只会输出文字建议的传统医疗大模型截然不同,MIRA 实现跨越式突破:它不止具备专业临床推理能力,更是首个能在标准化沙盒电子健康记录(EHR)环境自主完成一整套可落地诊疗操作的 AI 智能体,整套体系包含两大核心技术创新与一套标准化仿真评测底座。

图1|MIRA工作流程。 MIRA是一个自主医疗AI智能体,在EHR沙盒环境中运行,利用一套工具模拟临床工作流程:它能够开具检查、综合结果并生成诊断和治疗方案,同时通过聊天与一个基于真实病例回顾性记录中记录的现病史(HPI)构建的患者AI智能体进行交互。
为填补前述研究空白,研究团队开发了MIRA自主医疗智能体,并基于MIMIC-IV数据库500余例急诊真实病例开展仿真对照试验,试验病种涵盖阑尾炎、胰腺炎、肺炎、胰腺癌等8类常见急诊疾病。
以往绝大多数医疗 AI 仅能输出自然语言建议,难以真正接入医院电子病历。MIRA 搭建独立隔离的沙盒电子病历运行环境,全面兼容 FHIR 交互协议与 ICD、LOINC、SNOMED-CT 六大国际通用医疗编码体系,所有诊疗指令均生成标准化、结构化数据,可无缝适配遵循统一标准的院内信息系统,突破了传统医疗大模型“只能建议、无法执行”的局限。
MIRA 内置 11 类临床工具、85,000 余种可执行临床操作,智能体能够自主梳理完整病史、开立解读各类检查、推导鉴别诊断、开具处方、预约手术、规划入院。区别于传统模型单次碎片化答题,这套多工具联动机制让 AI 模仿真实医师逐步收集信息、动态调整方案,形成首尾贯通的完整诊疗链路。
为了尽可能模拟真实问诊场景、规避试验失真,研究还构建了专门的患者仿真智能体。该系统的所有回答严格受真实现病史(HPI)约束,避免模型 提前获取患者最终诊断信息,从而降低因后验信息泄露导致的性能高估风险。
大模型测试数据结果表明,这套仿真交互系统具有很高的稳定性:无论问题如何改写,回答内容的一致性、与原始病历匹配度均超 99%;即便面对诱导泄露诊断信息的对抗性提问,患者智能体也不会提前披露患者最终诊断结论,为后续人机对照实验提供了一个可信、可复现的评测环境。
研究设置了两组独立的人类医师对照组:4名持证专科医师作为高水准参照组,6 名混合资历团队复刻全球普及的德国急诊人力模式(无专职急诊医师,多由轮转低年资医生接诊)。两组医师与 MIRA 使用完全相同的患者信息输入,从诊断、治疗、用药安全三个维度横向对比综合诊疗水平,从而保证研究结果具有较强的现实参考价值与外部有效性。
过去的大多数医疗 AI 只能完成问诊、诊断、开药、手术建议中单一环节,无法连贯走完整套诊疗流程;而在本研究中,研究团队围绕临床决策链的四个核心环节——诊断、检查、治疗和安全,系统评估了 MIRA 的综合表现。结果显示,MIRA 不仅能够像医生一样连续处理急诊病例,还首次在统一实验条件下证明,自主医疗智能体具备完成端到端临床决策的能力。
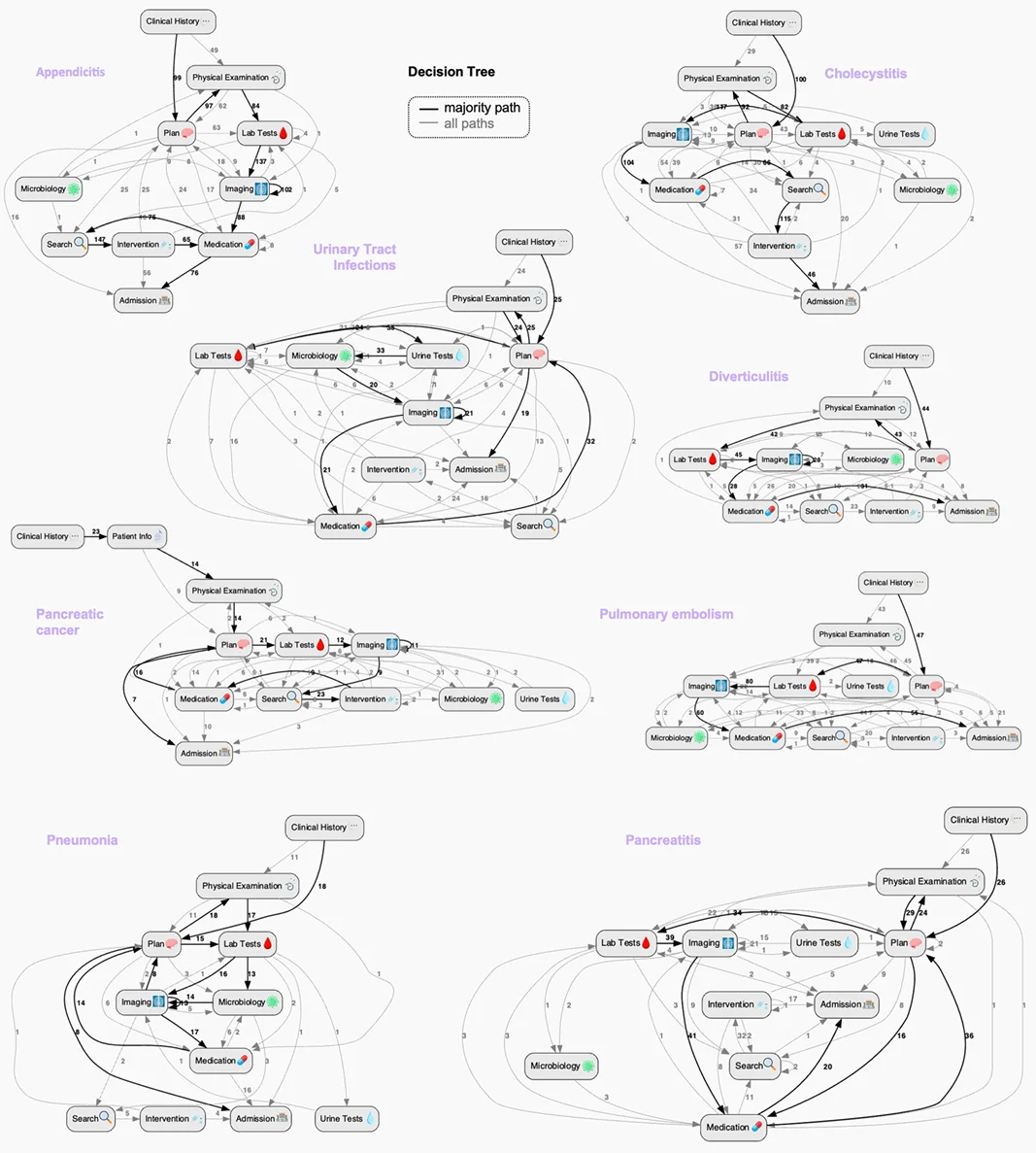
图2 MIRA的推理轨迹。 展示MIRA在每种目标诊断下的决策路径,均以“病史”起始、以“入院”结束。粗黑线为最常见的工具转换路径,边线数字为转换频次;整体流程与人类医生的诊疗顺序高度吻合。自循环箭头表示同一工具的重复调用(如初始影像不可用时改选其他模态)
首先,研究评估了 MIRA 的诊断能力。以 MIMIC-IV 数据库中的出院确诊结果作为参考标准MIRA 在八类疾病上的平均诊断准确率达 88.9%;在进一步的人机对照实验中,MIRA 在完全相同的信息条件下取得了 87.8% 的平均诊断准确率,显著高于持证医师 78.1%、基层轮转医师 71.1%。其中胰腺炎、阑尾炎识别优势最突出,仅胰腺癌诊断水平与专科医师持平,即便肺炎、尿路感染这类易混淆病症,其识别表现也不弱于人类医师。
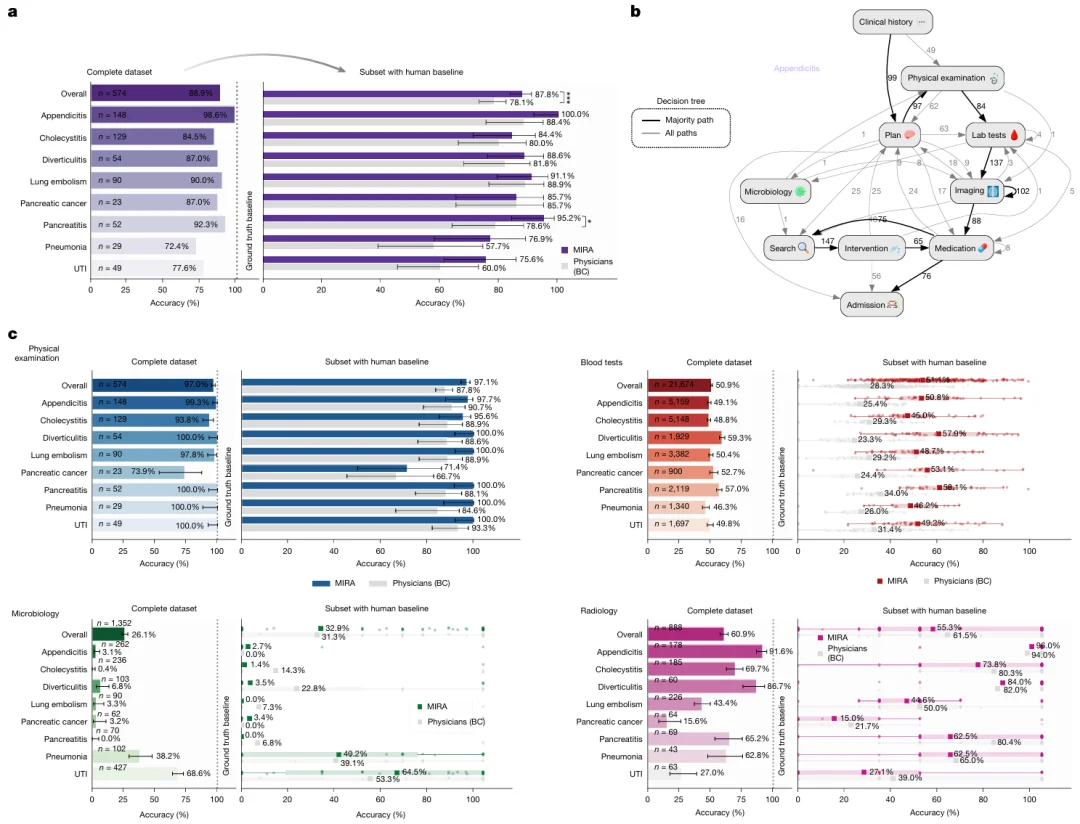
图3:a.左图显示基于MIMIC-IV真实数据(n=574)的总体准确率,MIRA对阑尾炎等明确疾病表现优异(148例漏诊2例);右图为匹配子集(n=311)中MIRA与医师的对比,MIRA准确率显著更高(双侧McNemar检验,P=0.000287),误差线为95%置信区间。b.以阑尾炎为例展示从病史到入院的推理轨迹,粗箭头为主要转换路径,数字为转换次数,循环为重复调用工具(全部轨迹见扩展数据图2)。c.检查选择方面,左图为相对MIMIC-IV基线(100%,n=574)的对比,右图为与医师(n=311)的对比。体格检查以柱状图显示检出比例(误差线为95%置信区间);微生物、血液及影像检查以点图显示召回率(含中位数、四分位距及须线)。显著性经McNemar检验和Wilcoxon检验评估,多重比较经Holm和Benjamini-Hochberg法校正。
进一步分析MIRA 的决策轨迹发现,其检查开具顺序与真实临床工作流高度一致,整体遵循由无创检查逐步过渡到有创干预的诊疗逻辑。相比人类医师,MIRA 体格检查覆盖更全面,血液检验指标也更丰富。值得注意的是,尽管 MIRA 增加了一部分低成本常规化验项目,但并未表现出通过大量开单来换取更高诊断准确率的倾向。研究并未观察到其过度使用 CT、MRI 等高成本影像检查的现象,这意味着自主医疗智能体未表现出明显的过度医疗风险。此外,MIRA 在患者居家长期用药核对任务中的准确率也非常高,能够快速完成药物信息的结构化整理。
在治疗决策环节,研究重点评估了 MIRA 推荐的手术和药物方案与真实临床实践之间的匹配程度。结果显示,MIRA 的整体治疗方案与标准临床路径的贴合度显著高于人类医师。例如,在阑尾炎病例中,MIRA对腹腔镜阑尾切除术的推荐匹配率达到 100%;总体来看,其外科操作推荐的召回率明显高于医师群体。药物处方层面,MIRA 的整体诊疗规范依从性比医师高出 35 个百分点,尤其在补液、镇痛等标准化治疗场景中表现突出。
不过,MIRA 并非完美。与人类医师类似,其抗生素处方仍未达到完全符合指南的水平。这也表明,即便自主医疗智能体具备较高能力,关键治疗决策仍需要保留人工复核机制。
医疗 AI 的最终落地,安全始终是底线。为此,研究团队从药物相互作用、肾功能剂量调整、药物过敏、QT 间期延长风险、阿片类药物管控、入院分流多维度,对 MIRA 开展系统性安全评估。:
结果显示,在56 份完整病例中,研究未观察到任何高危用药错误,近 500 条处方信息准确率接近满分;在入院决策方面,MIRA 对肺炎、肺栓塞等高风险患者未出现漏收治情况,仅少量肺栓塞病例存在偏保守收治倾向。此外,研究还进一步测试了性别差异、患者焦虑情绪以及语言障碍等潜在偏倚因素对模型表现的影响。结果显示,在不同干扰条件下,MIRA 的诊断性能波动极小,整体表现出较好的鲁棒性和稳定性。
这项研究最重要的意义,并不只是让医疗 AI 的诊断准确率再次提高,而是第一次证明: AI 不再只能单纯输出文字答疑,而开始具备了在医院工作流中持续采取行动的能力。依托沙盒电子病历搭建的 MIRA,可以独立走完急诊从问诊、判病、开检查到开药安排入院的完整诊疗链条,诊断、治疗、用药安全多项表现整体优于一线医护,补上了过去所有医疗大模型 “只会答题、没法在院内动手操作” 的关键短板。同时 MIRA 主打病历内全流程自动化,如果和擅长实时检索最新医学文献的 AMIE 类工具搭配,二者能够互相补足,进一步缩小 AI 决策和临床标准之间的差距。
但即便试验数据表现亮眼,MIRA 距离真实临床应用仍有相当长的距离。。首先,整套仿真交互场景全部依托历史病历文字搭建,现实里患者说话含糊、信息前后矛盾、遗漏关键病史的复杂情况,仿真环境没法完全复刻;其次,训练所用 MIMIC-IV 数据集有流入大模型训练素材的可能性,试验测出的效果或许存在虚高;最重要的一点,MIRA 全程仅运行在隔离沙盒环境,从未对接医院真实业务系统,真实病房的复杂突发状况没有经过检验。
除此之外,当 AI 被赋予自主开立检查、生成处方乃至安排手术和住院的能力时,医疗系统将面临一系列全新的问题。短期应用层面,自主医疗智能体更适合作为医师的协同助手,而非独立诊疗主体。药物核对、检验套餐组合、会诊文书撰写等标准化、重复性任务,可能成为最先落地的应用场景作,从而帮助临床医生减轻繁重的文书负担。
得注意的是,MIRA 在资源使用上表现出较强的克制性。研究并未发现其通过大量增加 CT、MRI 或手术等高成本项目来提升诊断准确率,而主要增加的是低成本常规血液检查。这意味着,自主医疗智能体未表现出明显的过度医疗倾向。未来,如果进一步引入成本约束和资源优化模块,这类系统甚至有可能成为医院优化资源配置的新工具。
长远来看,自主医疗 AI 的规模化落地,真正的挑战已经不再只是模型能力,而是责任划分与治理体系建设。首先,是人机边界必须被清晰界定:AI 可以承担标准化、重复性的诊疗流程,但所有关键决策——包括最终诊断、用药方案、手术安排,都应保留医师强制复核环节,不应允许智能体独立做出最终医疗决策。
其次,风险管控体系需要与技术能力同步演进,针对高危药物、高价值影像检查等关键环节,医院需要建立人工复核、全流程审计和异常预警机制,确保 AI 的每一次诊疗行为都能够被记录、追踪和解释。与此同时,行业层面也需要逐步建立统一的准入规范、数据安全标准和应急处置机制,为自主医疗智能体进入临床提供制度保障。
归根结底,当医疗 AI 开始从“知识工具”演变为“行动主体”时,医疗系统需要重新回答一个问题:谁授权 AI 行动,谁监督 AI 行动,又由谁为 AI 的行动负责。只有当人机分工、风险监管和行业标准同步成熟,自主医疗智能体才有可能真正走出实验室,成为缓解医疗资源紧张、缩小区域医疗差距的重要力量。
参考文献
[1] Ferber, D., Hilgers, L., Höper, C. et al. Towards autonomous medical artificial intelligence agents. Nature (2026). https://doi.org/10.1038/s41586-026-10675-5 .
[2] 数据:https://physionet.org/content/mimiciv/2.2/
[3] 代码:https://github.com/Dyke-F/MIRA
文章来自于"集智俱乐部",作者 "魏雲初"。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
