# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现阶段大多数人形机器人的运动控制还局限于 “有参考才能动” 的被动跟踪模式。
机器人只能机械重复提前录入的动作轨迹,无法自主生成全新的动作,很难适配日常灵活的人机交互场景。
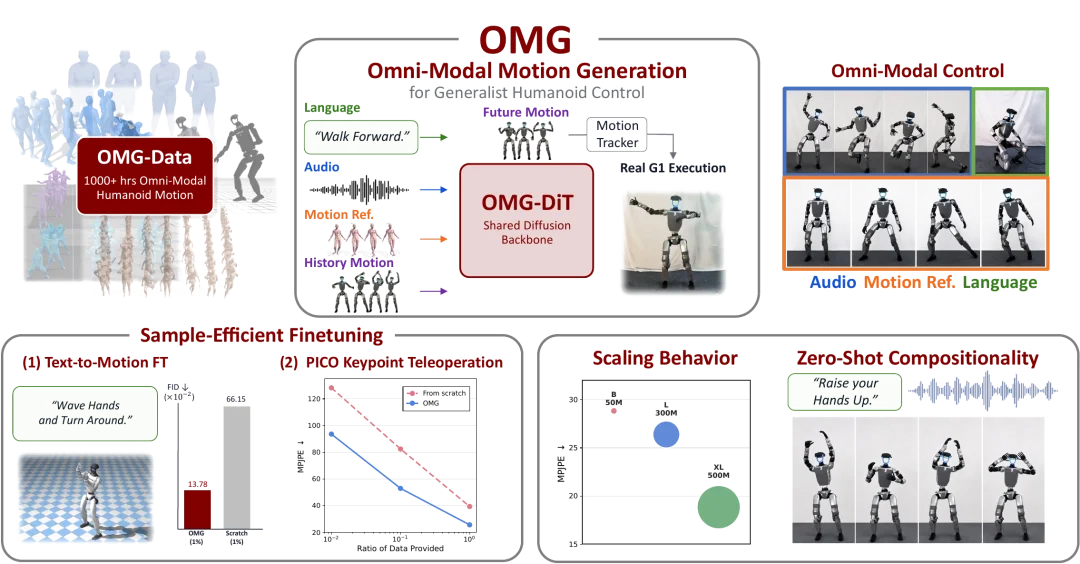
针对这一行业痛点,清华大学 MARS 实验室推出 OMG 全模态人形运动生成框架,创新打造 “生成大脑 + 跟踪小脑” 的分层控制方案。
团队搭建千小时级专属多模态机器人数据集,依托扩散模型构建通用运动生成网络,让机器人可实时响应文本、音频、人体动作及组合指令,自主生成稳定可执行的全身运动轨迹。
实测结果显示,OMG 不仅多项性能指标领跑主流模型,还具备大模型专属的规模缩放、小样本泛化、零样本模态组合能力,为人形机器人通用智能控制落地提供了全套开源方案。


目前主流人形机器人的运动跟踪技术,高度依赖外部预设的参考动作,不能理解人类多样化的交互意图,无法根据文字、音乐、人体姿态自主创作新动作,只能被动执行既定程序,彻底限制了人形机器人的智能化与通用性,难以适配生活化、开放式的交互场景。
为破解这一行业难题,研究团队量身打造 OMG 全模态运动生成体系。整套方案依托两大核心模块,千小时级多模态机器人数据集 OMG-Data 提供高质量训练素材,自研 OMG-DiT 生成网络负责多模态动作创作,搭配成熟的 HoloMotion 全身跟踪器,形成从意图理解、动作生成到落地执行的完整闭环,真正实现人形机器人的多模态智能自主控制。
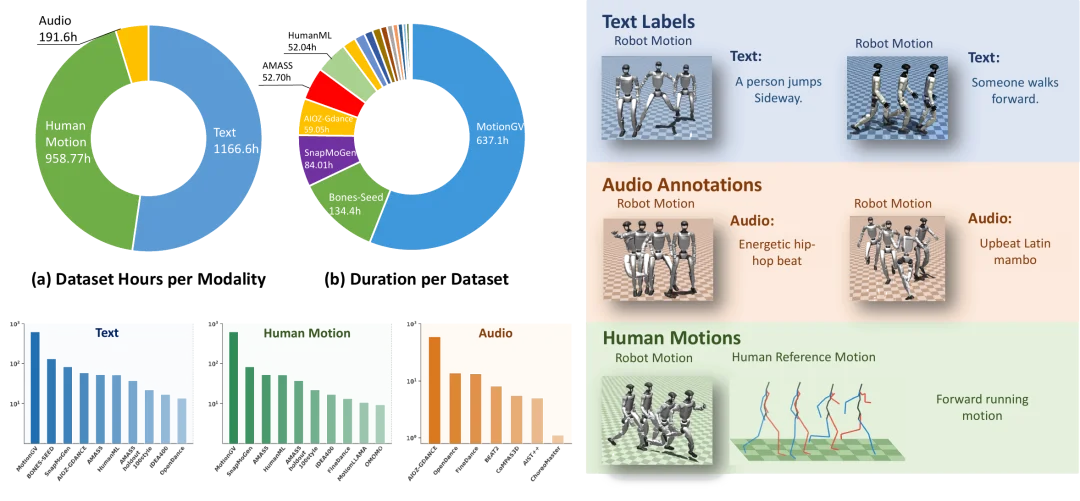
高质量、符合物理约束的标准化动作数据,是支撑人形机器人通用能力的核心底座。现阶段人类公开动作数据来源杂乱、骨架规范不统一,绝大多数人体动作无法直接迁移至实体机器人,存在严重的落地断层。
为此,研究团队搭建了一套完整、标准化的数据清洗流水线。研究团队首先整合 AMASS、LAFAN、舞蹈、语音手势配对等海量公开动作素材,剔除损坏帧、异常关节角度、时序错位等无效样本。随后通过通用动作重定向技术 GMR,将 SMPL 人体模型、视频重建人体、FBX 动画等异构动作数据,统一映射至宇树 G1 机器人专属动作空间。针对无文本标注的动作片段,研究团队在 MuJoCo 仿真环境渲染多视角动作画面,利用 VLM 完成细粒度时序语义标注,并根据文本边界、音乐乐句与滑动窗口完成长序列切分,适配模型短时预测的训练方式。
为保证数据的物理可行性,所有候选动作均进入仿真环境完成完整轨迹推演,由跟踪器实时执行并校验机身高度、倾斜角度、连续跌倒帧数、关节极限等关键指标,筛除违背动力学规则、跟踪失效的样本。最终构建的 OMG-Data 数据集总时长达 1174.66 小时,包含 1166.6 小时文本标注动作、958.77 小时人体参考动作、191.6 小时音频配对动作。所有数据无需二次修正,可直接用于实体机器人训练,补齐了人形运动生成领域 “数据规模不足、机器人可执行性差” 的两大核心短板。
OMG-DiT 是整套框架的核心创新,采用「共享主干网络 + 轻量化模态适配器」的解耦设计。模型将通用人形运动先验与多模态条件输入相互分离,无需对主干网络重新预训练,仅通过新增少量适配模块即可快速接入全新控制模态,极大降低了通用人形机器人的拓展与迭代成本。
整套系统采用生成 - 跟踪分层架构,分工清晰且高效协同。上层 OMG-DiT 作为运动生成大脑,基于历史运动状态、文本、音频、人体参考动作等条件,实时预测未来 60 帧宇树 G1 的全身参考轨迹;底层 HoloMotion 跟踪器负责将生成的轨迹转化为关节控制指令,完成机身平衡维持、抗扰与跟踪等物理执行任务。
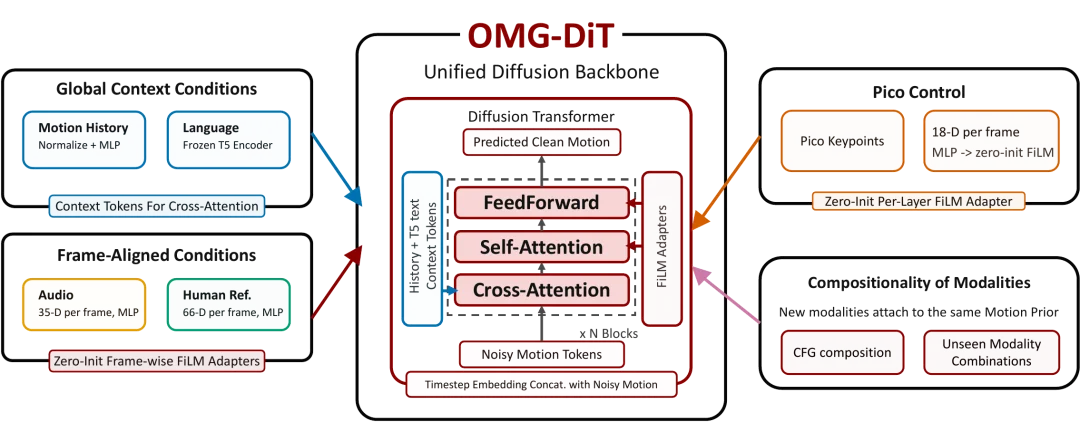
模型直接在宇树 G1 原生 125 维机器人动作空间完成训练与生成,无需额外的人体 - 机器人转换编码器。网络主体基于 DiT 构建去噪主干,结合 RoPE 旋转位置编码与时序自注意力机制,精准建模全身运动的时序关联。训练阶段通过随机模态丢弃策略,配合推理阶段的无分类器引导,实现单模态与多模态组合指令的灵活切换。
针对三类核心原生控制模态,团队设计了差异化的特征注入方案。文本指令通过冻结 T5-Base 编码器提取语义特征,以全局上下文 Token 的形式,经交叉注意力机制逐层注入 DiT 网络;音频、人体参考动作属于帧对齐类信号,经 MLP 特征映射后,通过 FiLM 调制模块逐帧优化运动特征,分别实现音乐节奏精准匹配、人体姿态高效复刻的能力。
该框架具备极强的模态拓展能力,以 Pico VR 关键点遥操作等全新交互场景为例,仅需配置零初始化 FiLM 适配器即可完成接入,主干预训练权重完全保留,依托少量样本微调即可适配全新任务,不会破坏模型已习得的通用运动先验。在推理阶段,用户可自定义多模态引导参数,灵活调节文本语义、音频节奏、人体姿态的权重配比,实现训练数据中从未出现的多指令协同运动生成。
研究团队从横向性能对比、下游小样本迁移、基础模型特性验证三个维度,开展了全面、系统的实验评测。所有模型输出轨迹均在仿真环境中由真实跟踪器执行校验,同步统计运动生成质量、机器人跟踪稳定性、跌倒率等多维指标,全方位验证 OMG 框架的综合性能与泛化优势。
在多模态生成对比实验中,OMG 在各类任务中均取得最优表现。文本驱动任务中,OMG-XL 模型 FID 低至 6.03,R-Precision@1 达 65.43%,机器人跌倒率仅 0.78%,语义匹配精度与物理稳定性显著优于 GENMO、HYMotion、Kimodo 等主流模型;
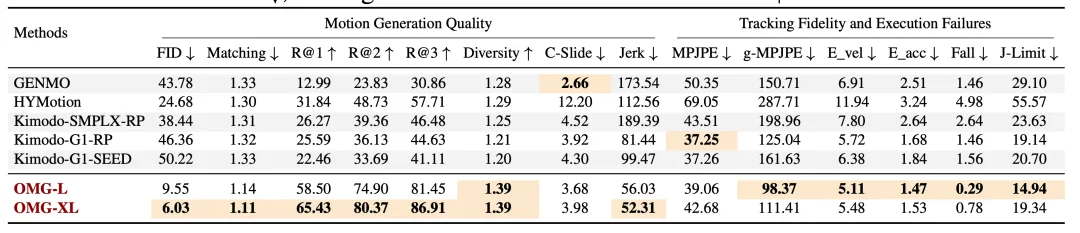
音频驱动舞蹈任务中,模型音频匹配 FID_k 为 40.46,全程无跌倒失效,可精准跟随古典、流行等不同风格音乐生成流畅全身动作;
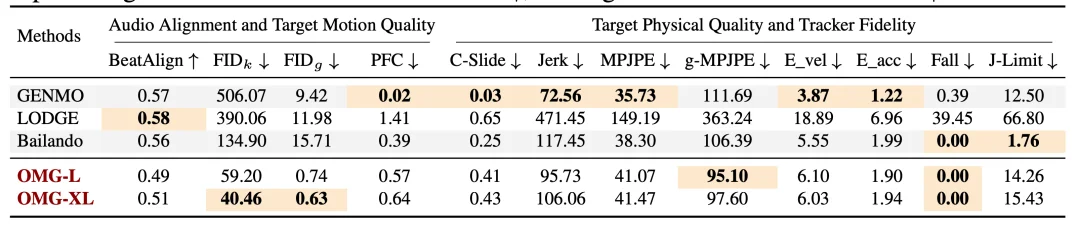
人体姿态重定向任务上,模型 MPJPE 误差仅 18.84,相较 GMR、NMR、OmniRetarget 等传统方案,能够在复刻人体细节姿态的同时,输出高度稳定、机器人可精准跟踪的运动轨迹。

下游微调实验充分验证了模型优异的迁移能力。在全新数据集适配任务中,仅使用 1% 的 AMASS-CMU 数据微调预训练模型,即可媲美全量数据从零训练的效果;在 Pico 关键点遥操作全新模态任务中,基于预训练权重初始化的模型,性能大幅优于随机初始化模型,充分证明主干网络沉淀的通用运动先验,具备极强的跨场景、跨模态泛化能力。
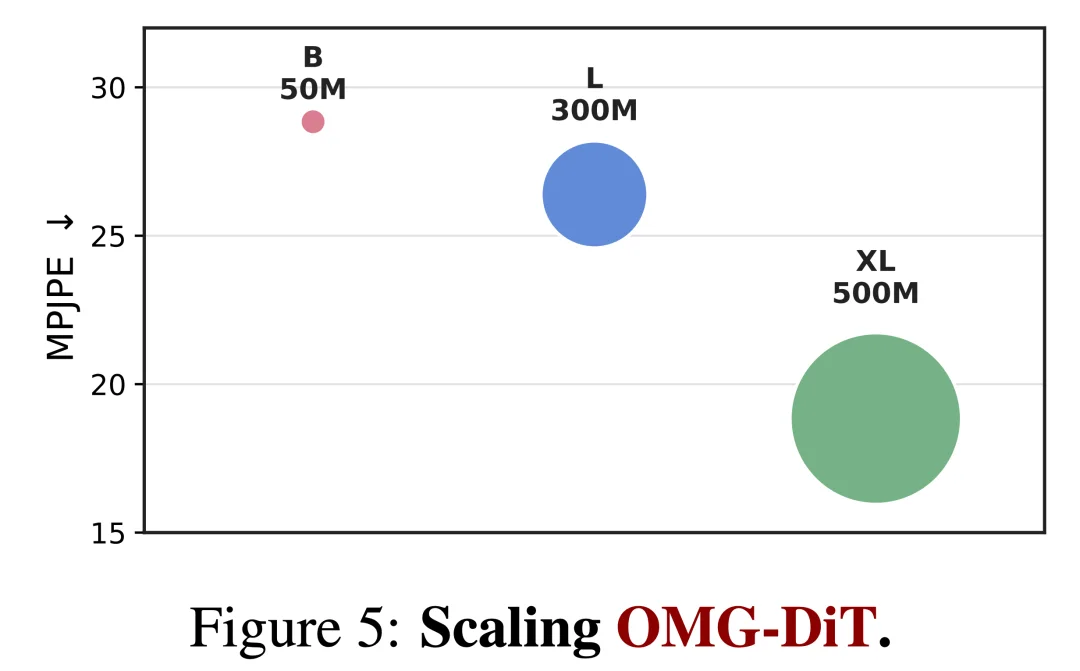
同时,论文验证了该模型具备典型的基础模型特质。其一为模型规模缩放特性(model scaling behavior),在数据与评估条件固定的前提下,模型参数量越大,运动生成综合性能稳步提升,证明人形动作生成可通过模型扩容持续迭代优化。
其二为零样本模态组合能力,模型可在推理阶段融合文本、音频等未见组合指令,兼顾语义逻辑与音乐节奏,生成差异化复合动作。此外,模型支持实时模态动态切换,在连续交互过程中平滑适配不同控制信号,完全满足人机实时交互的应用需求。

清华大学黄思乔、李坤应、乔东铭、贺贯齐为本文共同第一作者;清华大学赵行教授为本文通讯作者。研究团队长期聚焦人形机器人多模态运动生成、大规模动作数据集构建、仿真到现实迁移等前沿方向,持续产出人形机器人方向的系统性研究成果。
文章来自于"机器之心",作者 "黄思乔、李坤应、乔东铭、贺贯齐"。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
