# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当大模型应用进入深水区,决定一个 Agent 体验上限的,早已不只是 "答得对不对", 而是 "能不能持续记住同一个人"。
近日,华为 openJiuwen 社区开源了专为智能体设计的自主生长记忆引擎 AutoGenetic Memory—— 让记忆从 "存下来" 变成 "长出来"。
它的核心思想是:在 AutoGenetic 记忆引擎里,每一条记忆都像一段「基因片段」:
据了解,在公开基准 LoCoMo 测评集上,JiuwenMemory 以插件形式接入 OpenClaw,相较其原生记忆,准确率在提升 15% 的同时,记忆问答与添加环节的 Token 消耗大幅度降低超 60%。记忆内容更精炼,每次读取的 Token 更少、模型反复确认的次数更少,质量与性能在这里是同一枚硬币的两面。
AutoGenetic Memory 把 AI 记忆从被动的信息存储,自主生长为可治理、可跨平台共享、可自我演化的核心数据资产。让 Agent 真正具备 "记住用户、理解用户、服务用户" 的能力。
设想一个场景:你让 Agent 帮忙发一封项目结项邮件,对话里随口提到收件人邮箱、自己的身份、对方 "爱看数据"—— 都是闲聊带出来的,没刻意叮嘱它记下。过段时间你回来,让它给同一个人发一封新项目的邮件,你自然不想把这些再说一遍。可现实是,多数 Agent 跨会话后都 "从零开始", 仿佛之前的对话从未发生。
传统对话系统依赖有限的上下文窗口,一旦超出 Token 限制或跨会话重启,信息便丢失殆尽。团队把这种 "失忆" 归纳为四个老问题:用户被迫重复提问、个性化能力缺失、跨会话决策前后矛盾、经验始终停留在零点无法积累。
能回答问题,是 Agent 的基础能力;能记住用户,才是它的长期价值。
OpenClaw 的记忆结构相对扁平,以时间维度划分,Agent 自主决定 "写什么、写哪里", 缺少明确分类约束 —— 灵活性的代价是不确定性:偏好与技术细节可能混在一处,身份画像也容易被淹没在流水账里。
分层记忆体系:信息逐级升华,各归其位
不同于扁平的时间轴记录,JiuwenMemory 设计了 L0–L3 四层记忆,让信息从原始对话逐级抽象为结构化知识。
L0 原始信息层完整保留对话历史与时间戳等元数据,作为提取的源头,支持回溯与全量分析;L1 摘要记忆层由 LLM 压缩单次会话的关键结论、单独提炼,降低 Token 消耗、避免上下文溢出;L2 结构化记忆层拆分为情景记忆(按时间轴记录用户经历的具体事件、决策,可追溯)与语义记忆(沉淀背景知识、技术细节,不被日常流水账覆盖);L3 用户画像层刻画核心特征,含用户画像(偏好、习惯、角色定位)与结构化变量(姓名、时区、语言偏好等),始终处于最易访问的顶层。
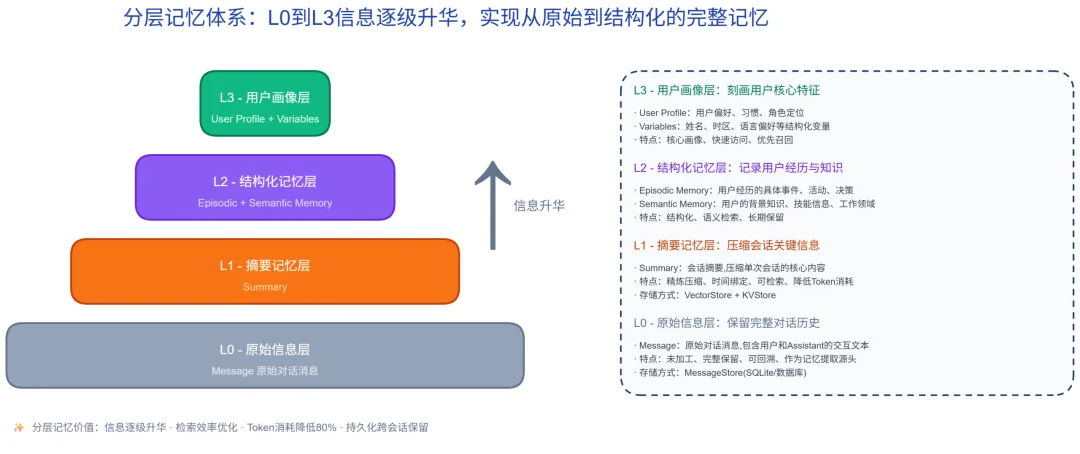
这套分层的价值有三:信息密度逐级放大、偏好与技术细节不再互相覆盖;通过摘要与结构化的精准压缩,避免全量历史加载、显著降低问答端到端 Token 成本;各层独立存储,确保记忆跨会话持久保留。
正是这种分层,让杂乱的原始对话被整理成各归其位的 "记忆基因"—— 按需调取、无需全量加载,基因构建因此更高效。
Auto Dreaming:把高成本记忆加工 "挪到后台睡眠时段"
认知神经科学早已揭示,人类在睡眠中通过 "记忆固化" 将白天的零散经历重放、提炼为长期记忆。JiuwenMemory 把这一范式工程化 —— 将记忆提取这类高成本计算从在线对话路径剥离,放到后台定时离线异步完成 —— 这正是 "做梦" 命名的由来。
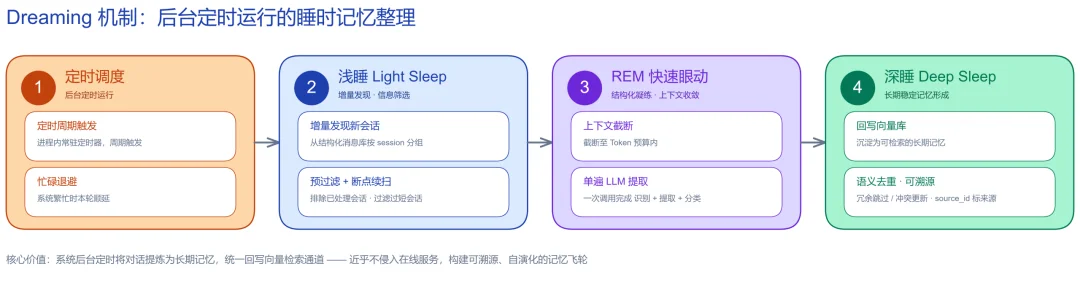
一次整理像经历一次睡眠:浅睡做增量筛选,REM 阶段由 LLM 单遍完成提取与归类,深睡经语义去重、冲突消解后写入长期记忆。
整个过程无需人工标注、可溯源至原始会话。为了能规模化常驻,团队叠加了多重控本手段:后台守护进程定时触发,系统繁忙时"忙碌退避"顺延、断点续扫只消费新增会话,叠加压缩截断、批次封顶等手段,使 Token 开销线性可控。全自动从对话中蒸馏经验并归入分层体系,且全程可溯源至原始会话——记忆由此从"存下来"升级为"自主生长"。当前的Dreaming方案不止于记录,更擅长总结归纳,以整段会话为视野做隐式提炼,把分散线索沉淀为更稳定广义的画像与经验,并向跨会话、跨用户的深层记忆沉淀持续演进。
这一步的去重与冲突消解,恰如基因的 "复制校对与自然选择"—— 淘汰无效、矛盾的片段,留下被验证过的优质基因;与 GraphMemory 的关系化组织相配合,让每一条记忆基因更准、更可信。
MemoryTurbo:把用户感知时延降到最低
"Turbo" 取自汽车工程涡轮增压,MemoryTurbo 借用这一隐喻:前台对话持续产生 "排气"(新增信息),后台飞轮静默旋转将其转化为 "增压"(结构化记忆),多轮交互推动飞轮越转越快 —— 正如涡轮增压器随转速攀升而输出更猛,记忆提取效率也越用越高。配合分层体系,MemoryTurbo 让记忆基因的提取、聚类与沉淀在后台高速运转、用户无感 —— 基因构建因此既快又省。
其关键在于动能解耦:原始对话瞬间写入缓存层向量库即完成更新,记忆提取在后台按算力负载异步调度。配合离心式语义聚类 —— 由小模型先按话题合并对话、一组一起提取,既保证连贯、避免语义漂移,又大幅摊销大模型调用次数。
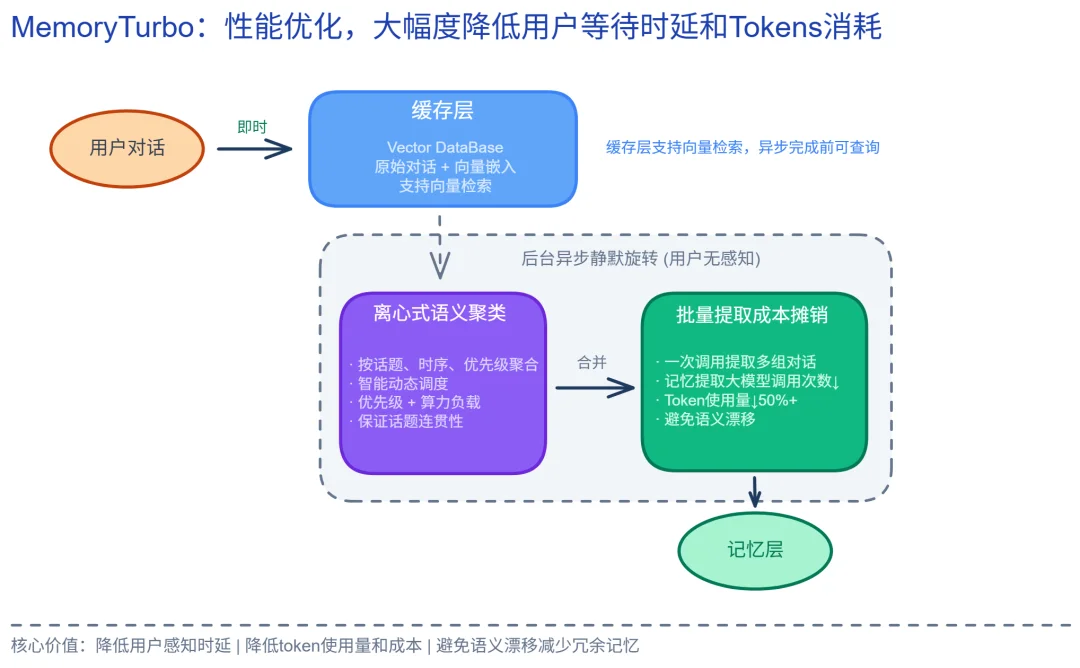
这套方案的核心价值是用户感知时延降低 80%,Token 使用量进一步降低 50% 以上,且提取未完成时缓存层仍可检索,精度不受影响。
Graph Memory:从片段记忆到关系网络,让 Agent 理解 "人、事、物" 的长期关联
在长期交互中,Agent 需要记住的不只是单条事实,还包括事实之间的关系。例如 "用户在做 A 项目""A 项目依赖 B 系统 ""用户上次因为 B 系统延期调整了计划"。如果只把这些信息作为独立文本片段存储,检索时容易只召回局部信息,难以还原完整上下文。Graph Memory 将对话、文档和结构化内容转化为可持续演进的记忆知识图谱,让 Agent 能够沿着实体和关系理解长期记忆。
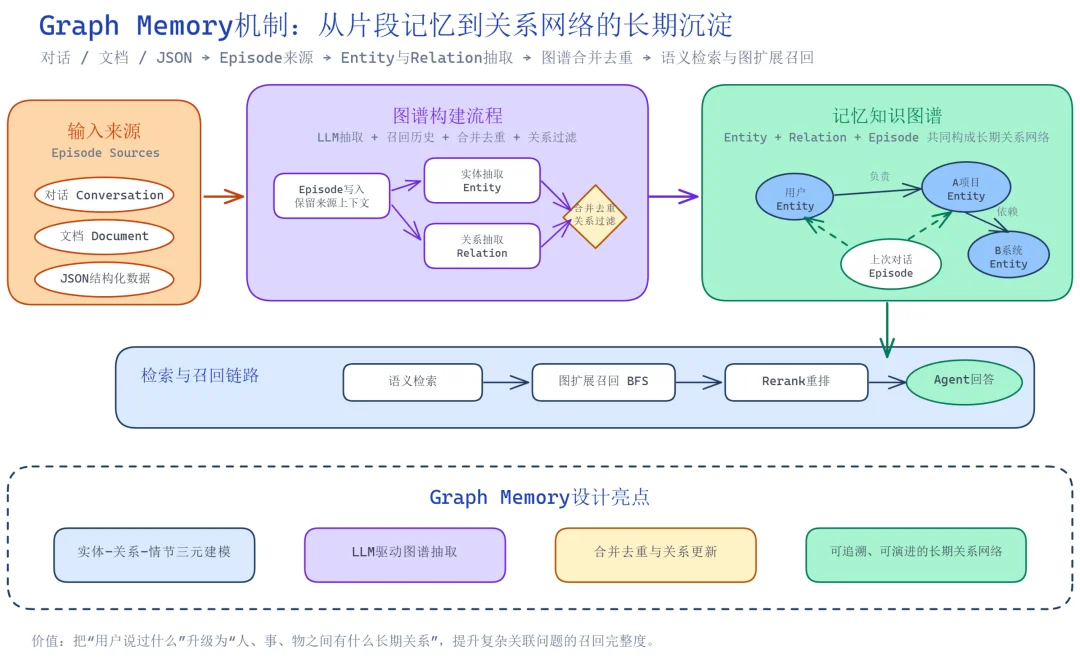
Graph Memory 将记忆从孤立事实升级为动态关系网络,实现四大价值:一是将 "用户说过什么" 进化为 "人、事、偏好间的关联",让 Agent 理解长期交互中变化的关系图谱;二是通过实体与关系链路召回上下文,解决纯语义相似度检索的遗漏问题,更完整地回答复杂问题;三是 Episode 保留来源溯源,Entity 和 Relation 沉淀结构化结果,新对话进入后图谱持续合并更新,让长期记忆从静态记录演进为动态知识网络;四是跨会话、跨文档信息组织成关系网络,帮助 Agent 积累客户、项目、问题、方案之间的长期关联,支撑组织级个性化服务与知识复用。
动态 Adapter 层:一种 "不绑定" 的设计哲学
Agent 生态正在快速裂变:新的 Agent 平台层出不穷,记忆引擎也在持续演进。如果记忆系统与任何一方硬绑定,用户要么被锁死在单一框架里,要么每次迁移都要重写集成逻辑 —— 这正是 JiuwenMemory Adapter 层想要消除的痛点。
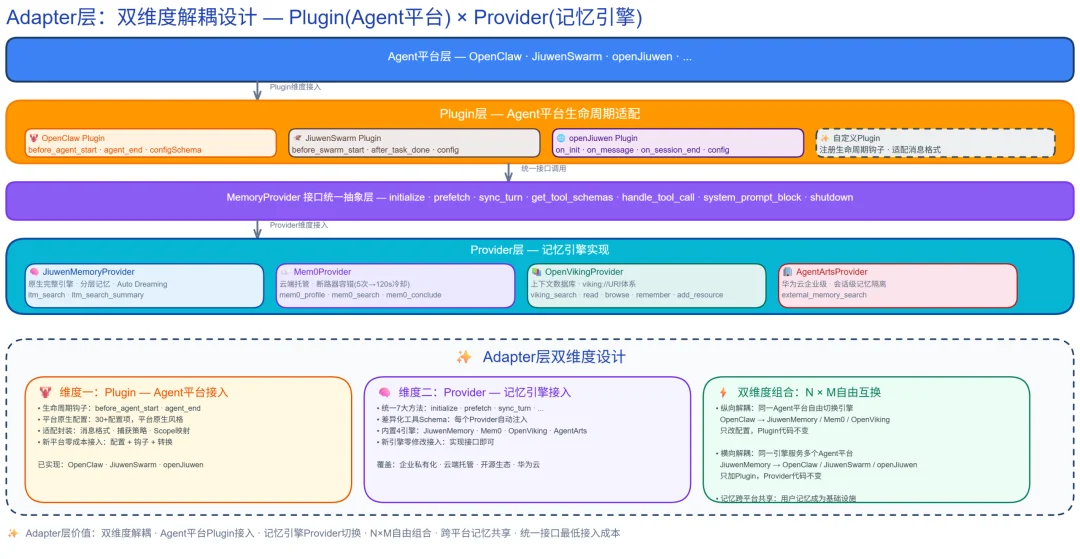
其核心设计理念是双维度解耦:Plugin 维度面向 Agent 平台,Provider 维度面向记忆引擎。记忆不属于任何一个框架,它是跨平台共享的基础设施。比如用户在 OpenClaw 上积累的对话记忆,可以无缝被各类 Agent 平台直接继承 —— 平台变了,记忆不丢。
更重要的是,这套解耦架构天然面向未来开放。目前 Provider 维度已内置 JiuwenMemory 和 Mem0 两种代表性实现,Plugin 维度已支持 OpenClaw 等主流 Agent 平台 / 应用,未来的扩展都只需实现对应的抽象接口,定义了一个可持续扩展的契约边界,让记忆生态从封闭走向开放。正是这条跨平台通路,让记忆基因得以在不同 Agent、不同平台之间复制与继承。
Swarm Memory:从个体记忆到群体记忆,让 AI 记忆在组织之间实现沉淀与共享
同时,AutoGenetic 记忆引擎在构建基于 Swarm 的群体记忆,是蜂群协作范式重要组成部分。单个 Agent 的记忆再强,也只是一棵孤树;当多个 Agent 协同工作,真正的价值在于让各自的记忆汇入同一片知识森林。每个 Agent 在服务用户时独立积累个体记忆,同时将值得共享的经验、知识与关系网络沉淀至组织级记忆池,供群内所有 Agent 按需共享。新加入的 Agent 不再 "从零起步",而是直接继承组织已沉淀的领域知识、客户画像与问题解决路径,实现 "一人经验、全员受益",记忆由此从个体资产升级为组织级数据资产。
快速开始:三步接入 JiuwenMemory
步骤 1:安装
JiuwemMemory 兼容 Windows、Linux、macOS,需要 Python ≥ 3.11 且 < 3.14(建议使用 3.11.4)。
pip install -U JiuwenMemory
按需安装存储后端:
# SQLite 支持
pip install JiuwenMemory [sqlite]
# PostgreSQL 支持
pip install JiuwenMemory [postgres]
# 其他如 MySQL、GaussDB、Redis、ChromaDB 支持
pip install JiuwenMemory [mysql]/[mysql]/[gaussdb]/[redis]/[chromadb]
# 安装所有存储后端
pip install JiuwenMemory [all]
步骤 2:初始化 Provider,配置存储后端和 Embedding 模型,注册到 Agent 系统。
步骤 3:Agent 自动使用记忆能力 —— 对话开始预检索记忆,对话结束生成记忆,用户查询可主动检索记忆,无需修改 Agent 核心逻辑。
场景 1:以下发邮件的记忆场景,其实就是 JiuwenSwarm 搭载 JiuwenMemory 后的实测结果。在没有任何显式指令的情况下,Agent 主动从对话中提取了联系人信息、用户身份、收件人偏好、项目关键数据,并按类型分层写入;跨会话后正确调用了收件人邮箱、以用户身份落款,并保留了符合对方偏好的表达,全程无需用户重复提供任何信息。
场景 2: 搭载 Dreaming 记忆能力后的真实实测演示。在全程无任何显式指令要求的前提下,用户与 Agent 自由聊天沟通,交流内容围绕个人困惑、个人兴趣两大核心展开。对话过程中,Agent 自动触发 Dreaming 记忆提取、归纳与合并能力,全程无需用户手动标注、总结信息。
Agent 自主梳理完整聊天记录,智能甄别对话中的有效个人信息,精准提炼用户真实困惑、兴趣偏好、个人特质等核心内容,对碎片化、口语化的对话内容进行规整整合、去重合并,形成结构化的用户专属记忆。整个过程全自动完成,无需用户重复阐述个人情况,实现自然对话场景下的智能记忆沉淀与信息归档。
Agent 记忆的上一轮竞赛围绕 "能不能记住" 展开,如今各团队在底层存储与召回上已趋于一致;新的焦点正在转移:记下来的是什么、能不能自主生长。
当记忆只是 "存下来", 它就是一堆被动等待检索的原始数据,会膨胀、会矛盾、会淹没关键信息;
只有当它能像基因一样可复制、可共享、可进化,才真正 "活" 了起来
这正是 AutoGenetic Memory 名字里的答案 —— 把每一条记忆都当作一段会自主生长的基因片段来对待:
从被动的 "信息存储" 到 "自主生长",从个人记忆到组织记忆沉淀,AutoGenetic Memory 想做的,是把 Agent 记忆从一项 "功能" 重构为一种 "核心数据资产",助力打造真正认识你、记得你、越用越懂你的智能 Agent。
相关资源
文章来自于"机器之心",作者 "机器之心"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
