# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
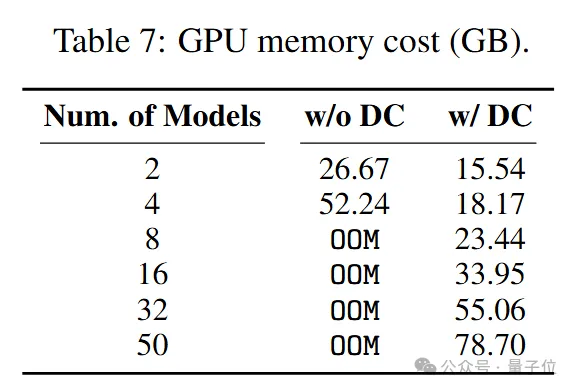
最新模型增量压缩技术,一个80G的A100 GPU能够轻松加载多达50个7B模型,节省显存约8倍,同时模型性能几乎与压缩前的微调模型相当。
清华大学NLP实验室携手OpenBMB开源社区、北京大学和上海财经大学的研究团队,提出Delta-CoMe。

这项技术的核心在于利用主干模型与任务专用模型之间参数增量(即Delta)的特点进行压缩,从而实现存储开销和部署成本的大幅降低。不仅有助于解决资源瓶颈问题,更为多任务处理和模型部署开辟新的可能。
具体而言,Delta-CoMe将低秩分解和低比特量化技术相结合,充分利用Delta参数的低秩特性,提出了一种全新的混合精度压缩方法。这种方法不仅能够实现接近无损的任务性能,还能显著提升推理效率。
微调是增强预训练模型的重要手段,不同任务往往需要不同的微调方式。例如Luo et al.[1]提出RLEIF通过Evove-instruction来增强模型数学推理能力;Wei et al.[2]利用Code snnipet合成高质量的指令数据来增加模型的代码能力。然而,这些方法通常依赖高质量数据,并需要精心设计的策略才能实现显著的效果。
在一些场景中往往需要具有不同能力的LLM同时处理问题,例如多租户场景,多任务场景以及端侧场景等等。一种自然的解决方案是部署单个通用模型作为主干,配合多个具有专有能力的Delta。
以Bitdelta[3]为例,它通过将模型的Delta压缩到1-bit,有效保留了模型在问答等场景中的能力。尽管该压缩方法在存储和推理效率上表现出色,其在更复杂的任务(如数学推理和代码生成)上仍存在明显的能力瓶颈。
针对这一挑战,THUNLP实验室联合北京大学和上海财经大学提出Delta-CoMe。这一方法结合低秩分解和低比特量化技术,不仅显著提升了模型在复杂任务上的表现,还兼顾了压缩效率和实际应用需求,为模型的高效部署提供了一种新思路。
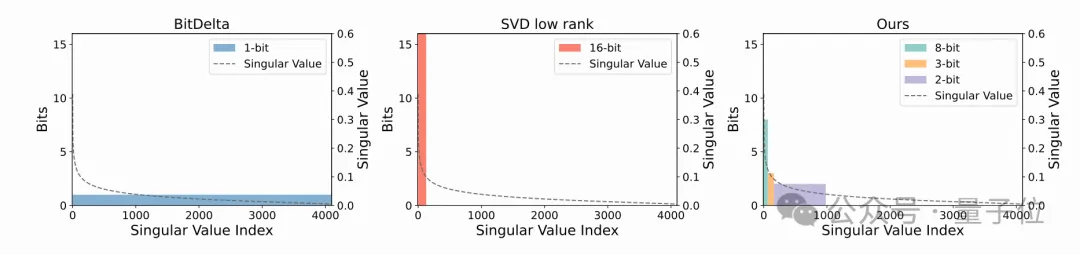
与前人的方法相比,Delta-CoMe方法的优点在于:
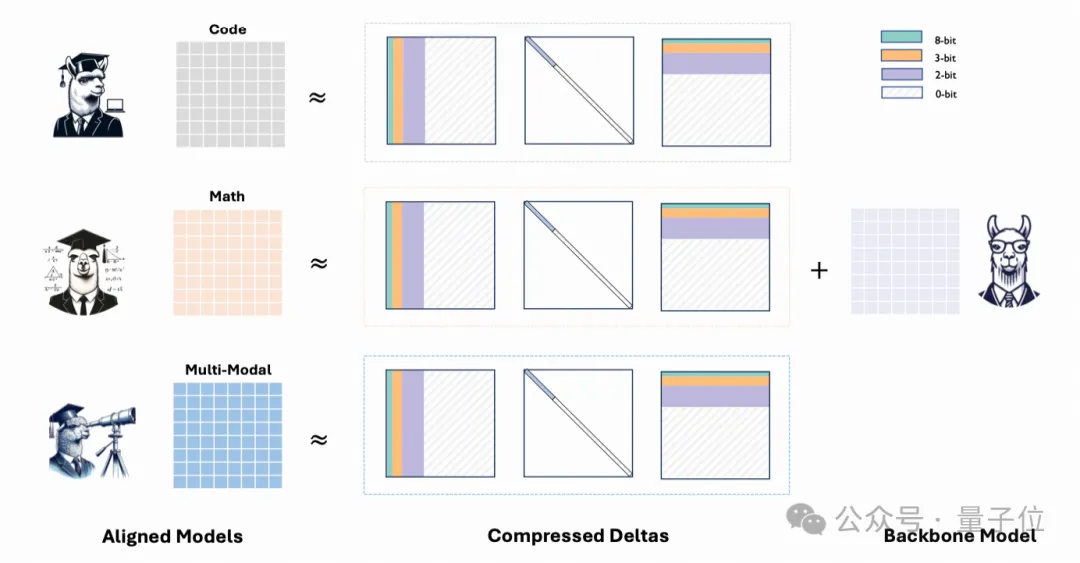
具体而言,Delta-CoMe首先采用SVD进行低秩分解,Delta 具有低秩性,经过低秩分解之后,其特征值呈现出长尾分布的规律,仅有少数较大奇异值对应的奇异向量对最终的结果贡献较大。
一个自然的想法,我们可以根据奇异值的大小进行混合精度量化,将较大的奇异值对应的奇异向量用较高精度表示,而较小的奇异值对应的奇异向量用较低精度表示。
多个开源模型和 Benchmark 的实验验证了该方法的有效性。
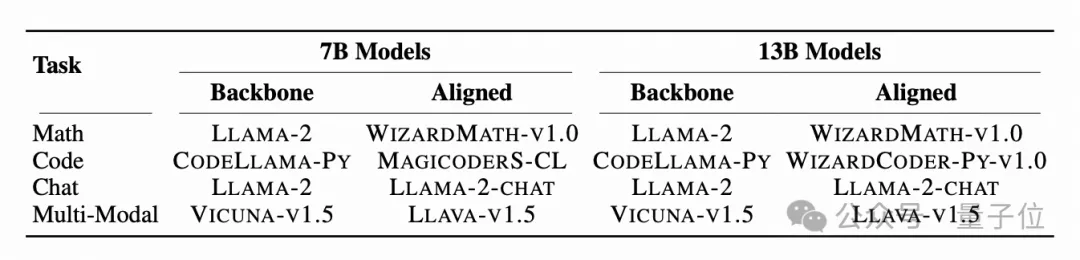
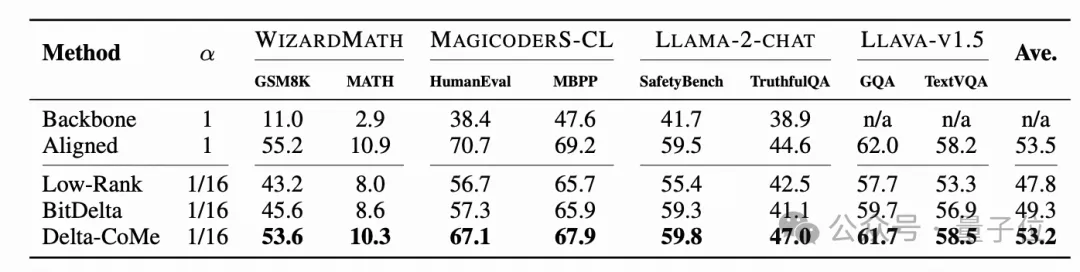
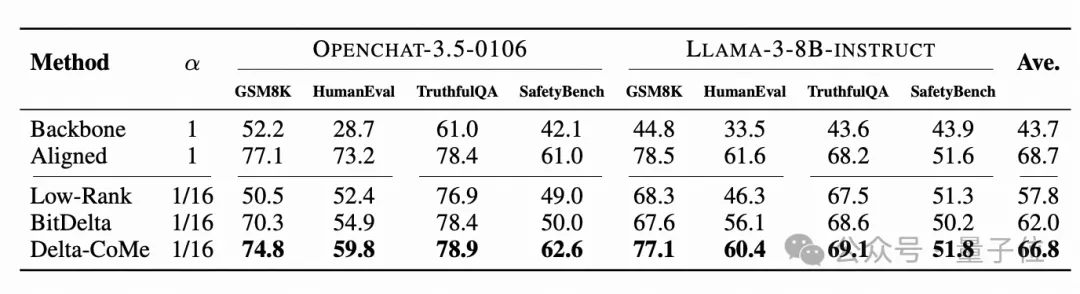
使用Llama-2作为主干模型,在数学、代码、对话、多模态等多个任务中进行实验,Delta-CoMe展现出平均几乎无损的性能。下面分别是7B模型和13B模型的实验效果。
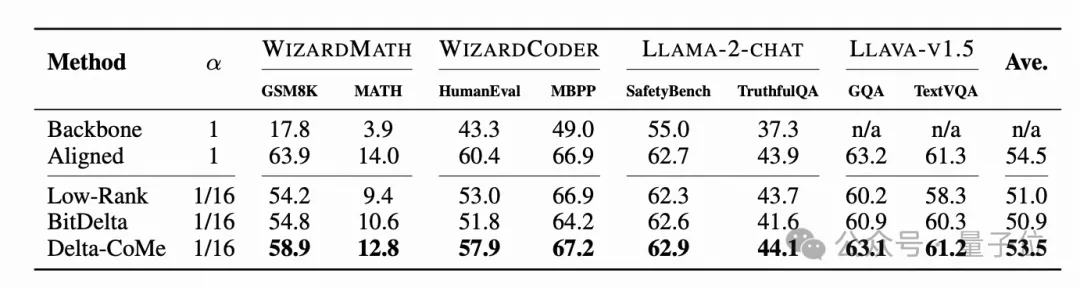
此外,还在Mistral、Llama-3等其它主干模型上对不同的压缩方法进行了验证。
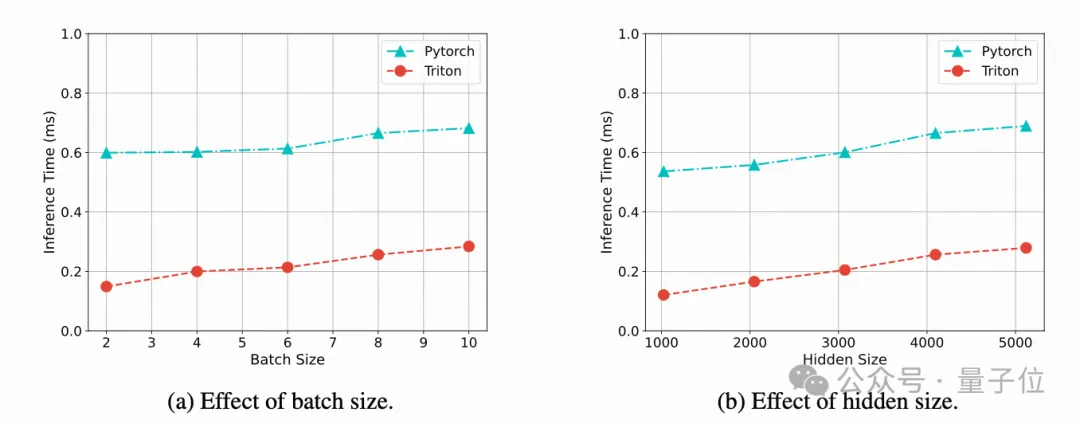
为了提升混合精度量化的计算效率,实现一个Triton Kernel,相比于Pytorch的实现方式,推理速度提升了约3倍。
实验结果表明,使用一块80G的A100 GPU可以加载50个7B模型。
最后,还比较了Delta-Tuning和Delta-Compression的效果差异(Delta-Tuning指的是通过训练部分参数进行微调,Delta-Compression指的是先进行全参数微调,再将微调带来的模型参数增量进行压缩)。其中Delta-Tuning采用的是LoRA。Delta-CoMe对比LoRA在相同的存储开销下,性能显著提升。
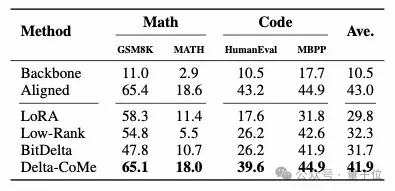
Delta-CoMe 通过结合低秩分解和低比特量化,不仅实现了大幅度的存储压缩,还在复杂任务如数学推理、代码生成和多模态任务上维持了与压缩前模型相当的性能表现。相比于传统的微调方法,Delta-CoMe 展现出了更高的灵活性,尤其在多租户和多任务场景中具有显著的应用价值。此外,借助 Triton kernel 的优化,推理速度得到了显著提升,使得部署大规模模型成为可能。未来,这一方法的潜力不仅在于进一步优化模型存储和推理速度,也有望在更广泛的实际应用中推动大语言模型的普及和高效运作。
[1]Yu, L., Jiang, W., Shi, H., Jincheng, Y., Liu, Z., Zhang, Y., Kwok, J., Li, Z., Weller, A., and Liu, W.Metamath: Bootstrap your own mathematical questions for large language models. In The Twelfth International Conference on Learning Representations, 2023.
[2] Luo, Z., Xu, C., Zhao, P., Sun, Q., Geng, X., Hu, W., Tao, C., Ma, J., Lin, Q., and Jiang, D. Wizardcoder: Empowering code large language models with evol-instruct. arXiv preprint arXiv:2306.08568, 2023b
[3] Liu, J., Xiao, G., Li, K., Lee, J. D., Han, S., Dao, T., and Cai, T. Bitdelta: Your fine-tune may only be worth one bit. arXiv preprint arXiv:2402.10193, 2024b.
Paper链接:https://arxiv.org/abs/2406.08903
Github链接:https://github.com/thunlp/Delta-CoMe
文章来自于“量子位”,作者“Delta-CoMe团队”。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
