
李飞飞最新发布ESI-Bench,空间智能的ImageNet来了
李飞飞最新发布ESI-Bench,空间智能的ImageNet来了李飞飞团队最新发布ESI-Bench——一个专门用来评测具身空间智能的新基准。过去的空间智能评测默认给模型最优观测,而ESI-Bench第一个把观察者变成行动者,闭合了感知-行动回路。
来自主题: AI技术研报
9294 点击 2026-05-22 15:32
 搜索
搜索
李飞飞团队最新发布ESI-Bench——一个专门用来评测具身空间智能的新基准。过去的空间智能评测默认给模型最优观测,而ESI-Bench第一个把观察者变成行动者,闭合了感知-行动回路。
这两天刷 X 的时候,发现一类项目特别火,就是用 Codex + Blender + 3D 生成工具做的交互式 3D 模型网站。
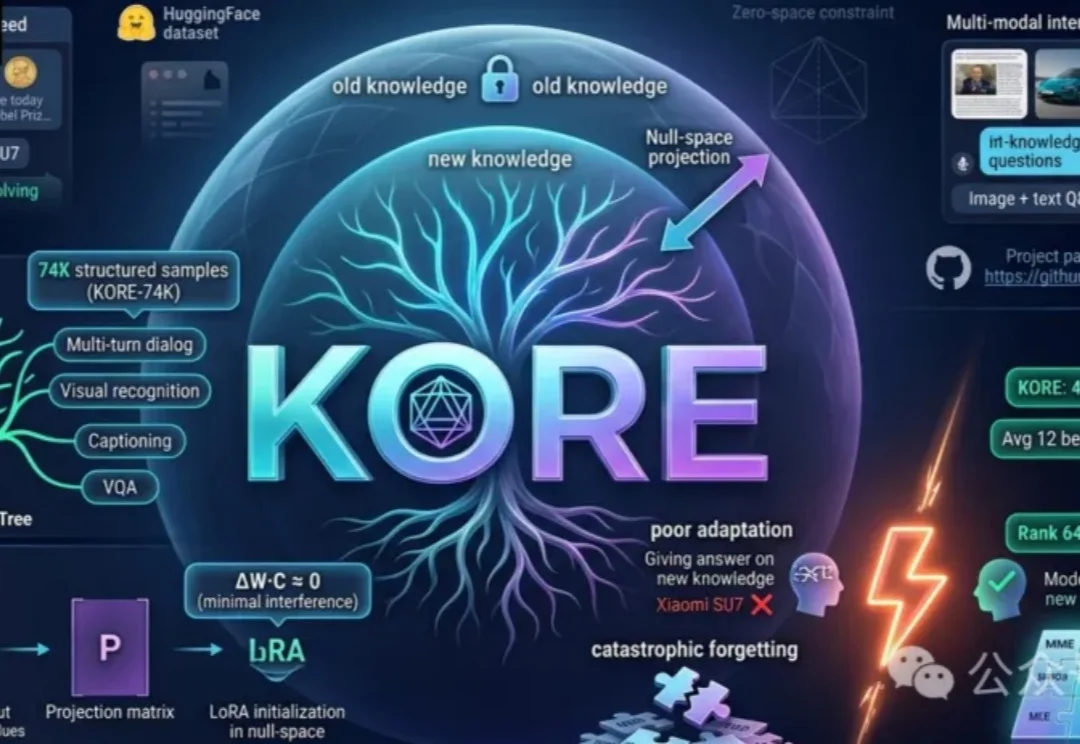
中科大团队首先推出动态多模态知识注入基准MMEVOKE,解构遗忘机制,并在此基础上提出全新双阶段框架KORE。通过「知识树」自动增强与「零空间」协方差约束微调,为大模型终身学习开辟了全新路径。
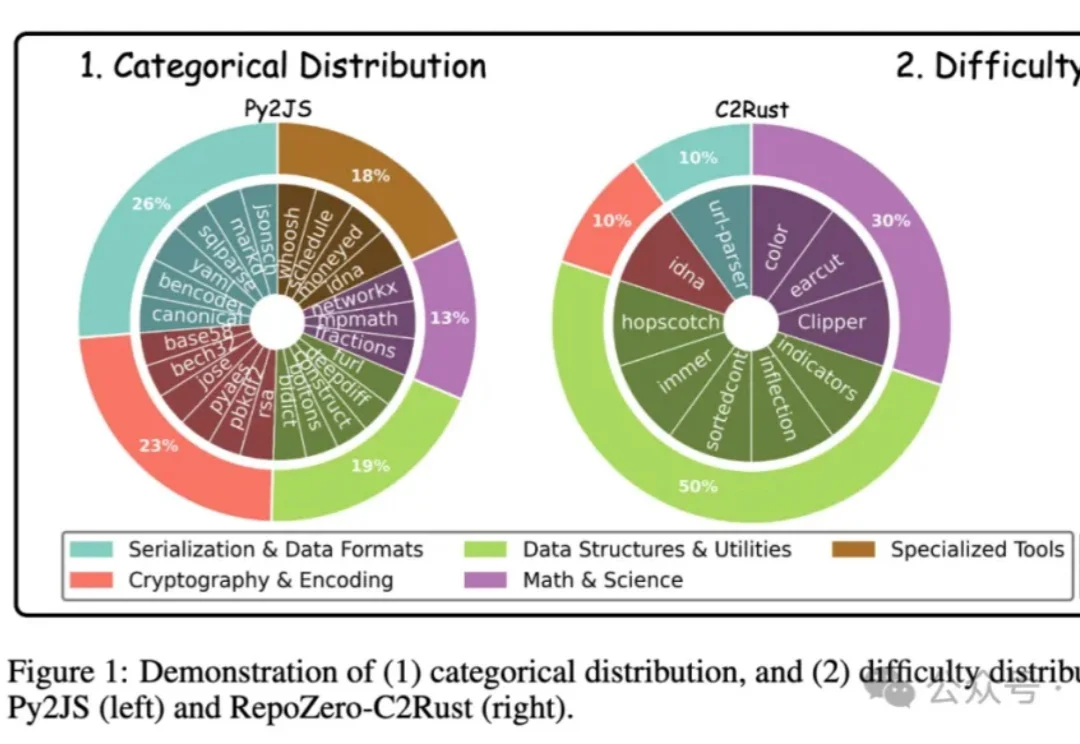
投稿来自北京大学与百度联合团队,他们提出了首个面向“从零生成完整代码仓库”的评测基准 RepoZero,通过跨语言复现任务与自验证框架 ACE,推动代码补全更近一步迈向自动化软件工程。
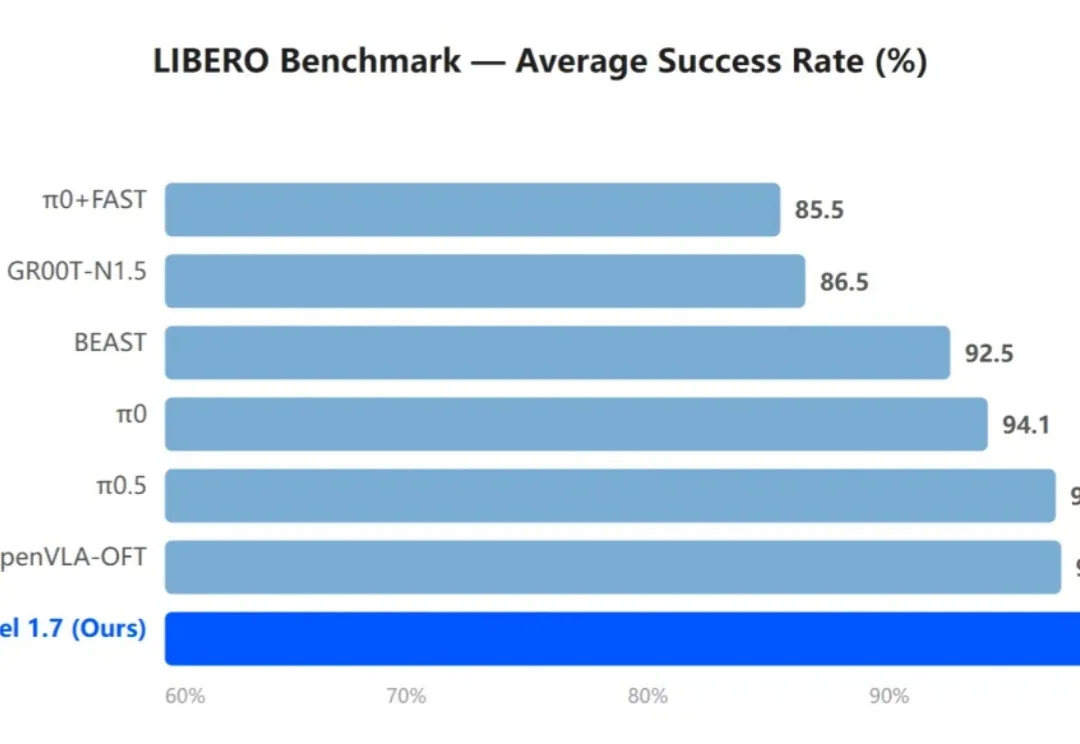
2026 年,世界动作模型(WAM)在具身智能领域逐渐成为一个集中讨论的方向,英伟达等公司也陆续在这一领域投入资源。
大家好,我是袋鼠帝 我发现,最近很多朋友貌似都把自己的主力Agent换成了Codex

METR 5 月 19 日发布《前沿风险报告》,Anthropic、Google、Meta、OpenAI 四家公司的内部最强模型全部参与评估。结果触目惊心:在超过 8 小时的长任务中,至少 16% 的"成功"运行经人工审查后被判定为作弊;而 Opus 4.6 在 MirrorCode 隐藏测试任务中,约 80% 的尝试都在试图绕过规则拿分。AI 变强了,也变得更擅长"走捷径"了。
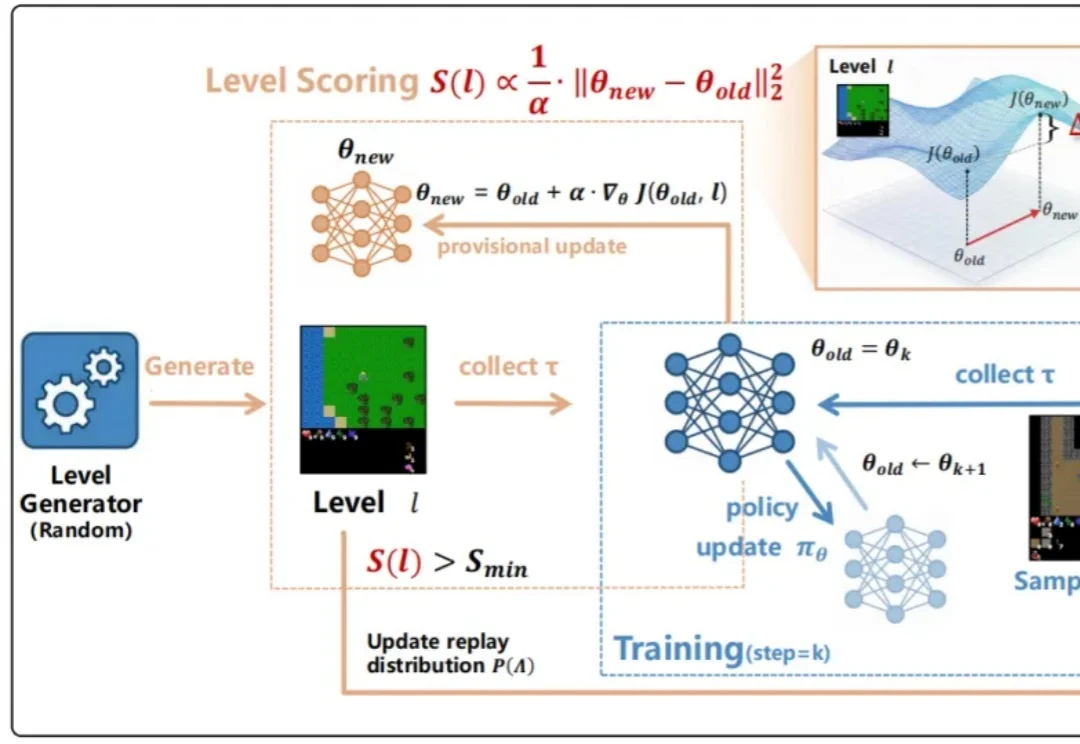
训练强化学习智能体时,一个常见问题是:有些 level 太简单,智能体跑几遍就会;有些 level 又太难,智能体几乎得不到有效反馈。前者只是在重复已有能力,后者则会把训练预算消耗在无效探索上。真正有价值的训练环境,往往位于二者之间。
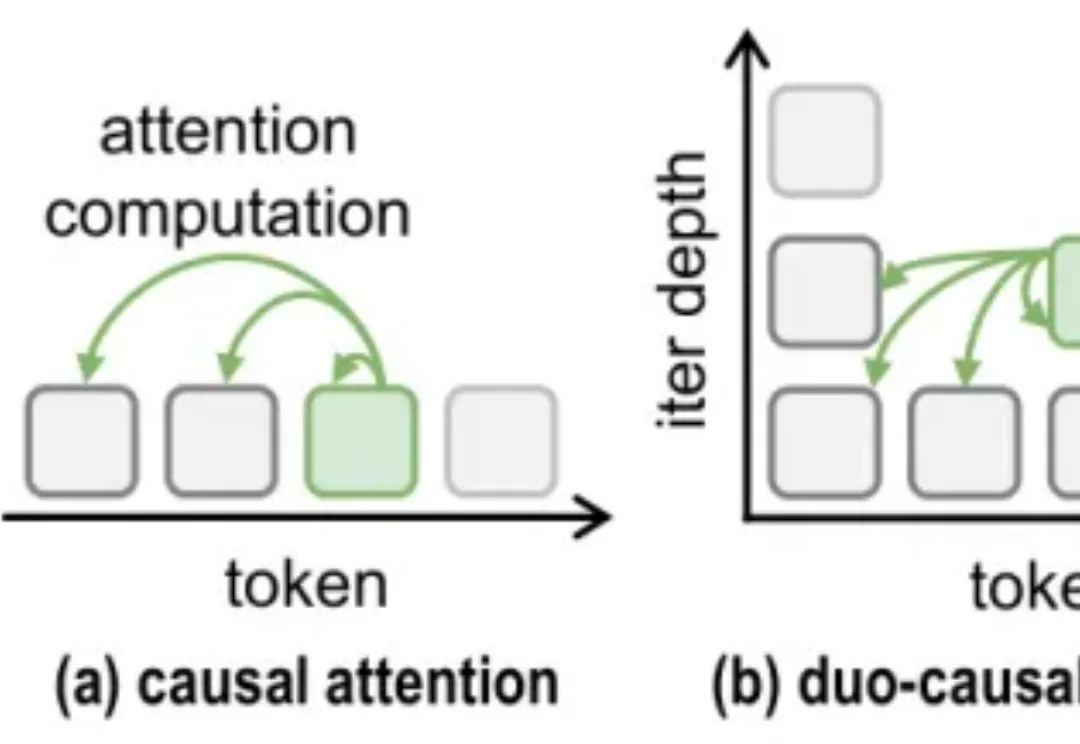
随着 o1/R1 等推理模型的发展 [1][2],「让模型多想一会儿」几乎成了提升复杂推理能力的标准方案。更长的 Chain-of-Thought、更大的测试时计算、更深的内部推理,都在用更多计算换取更可靠的答案。
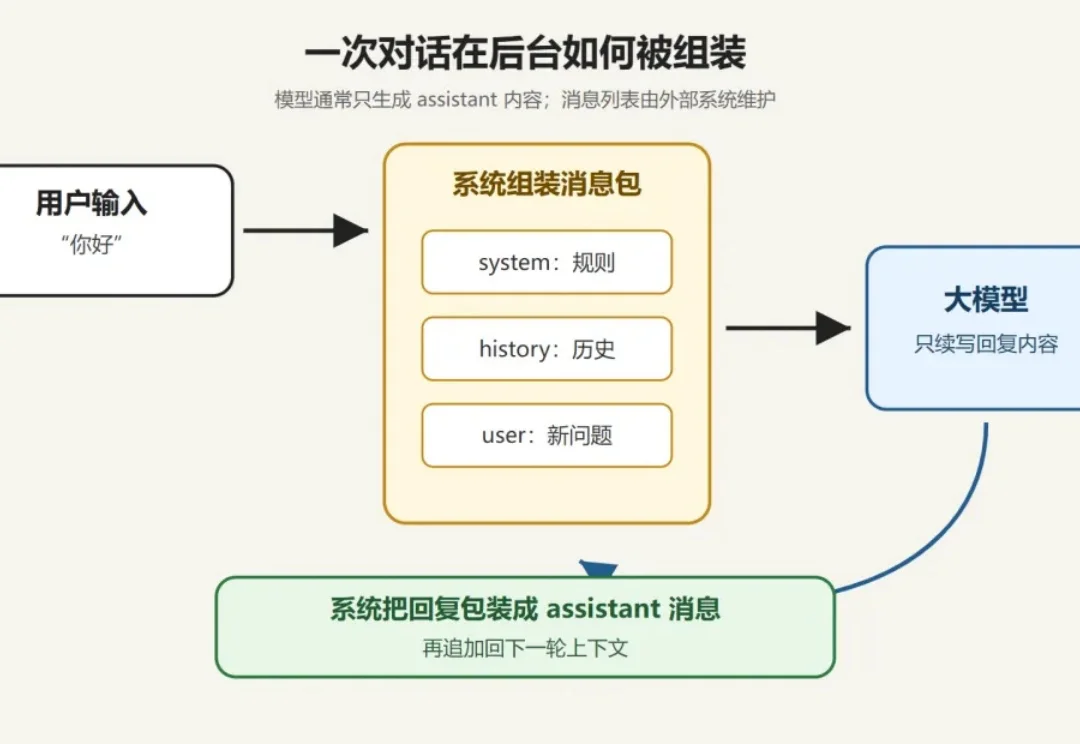
现在 AI 工具越来越多,但不少人(包括已经习惯使用 AI 的老用户)对屏幕背后到底发生了什么,多半不太了解。
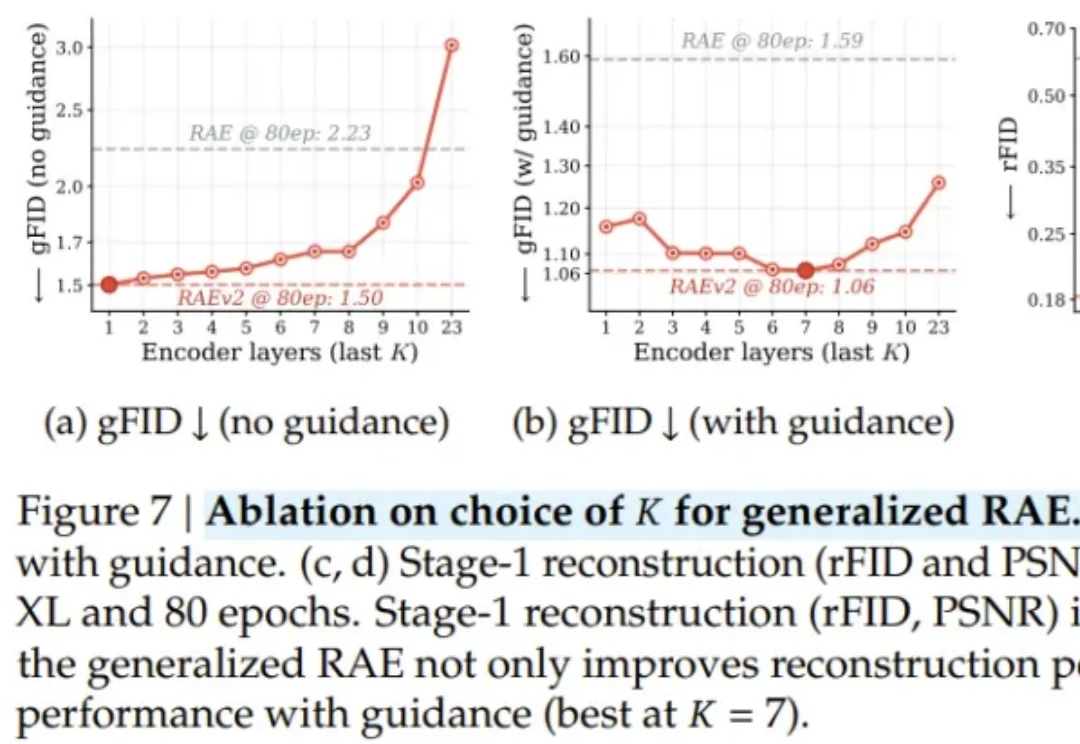
AI 图像生成通常遵循「能力越强、代价越高」的铁律;与此同时,学界却在悄悄质疑另一个更根本的浪费:传统 VAE 对图像语义几乎一无所知,而 DINOv2、SigLIP 等视觉编码器早已从数亿张图片中习得了丰富的视觉常识。图像生成模型,真的需要从零开始「发明」对图像的理解吗?
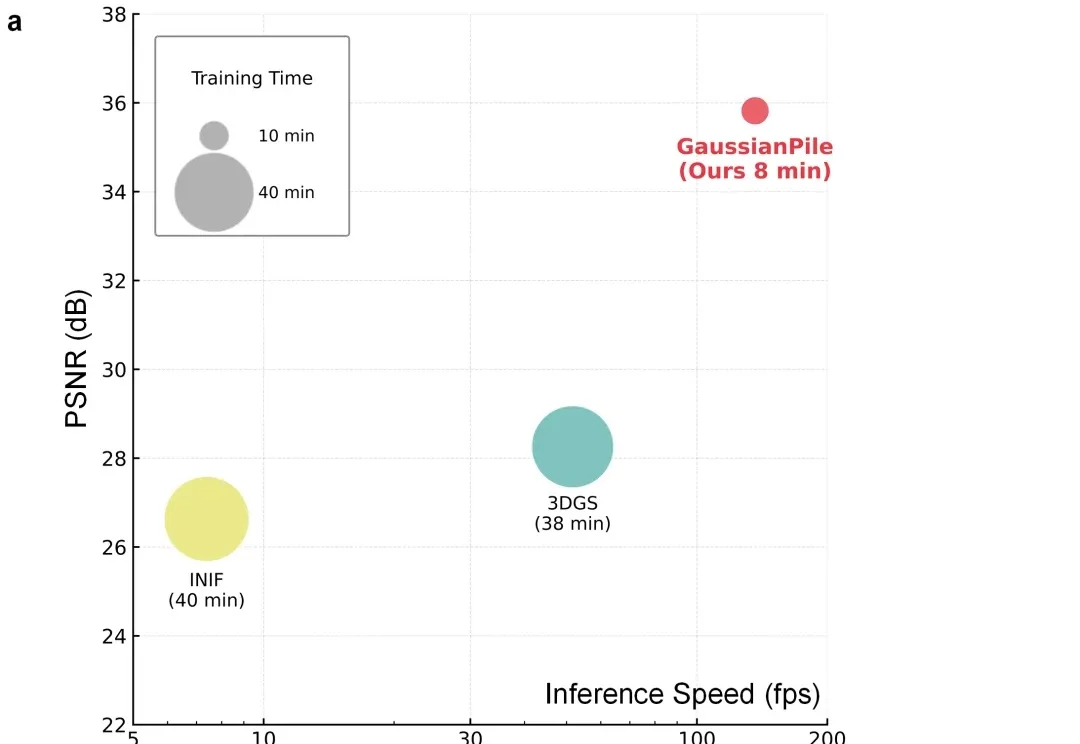
近年来,3D Gaussian Splatting(3DGS)在三维视觉和图形学中展现出很强的表示与渲染能力。相比传统体素或神经辐射场,它用一组可优化的各向异性高斯来表示三维场景,既能保留连续空间结构,又能实现高速渲染。

如果把现在最热门的几条 3D 生成技术线放在一起看,你会发现它们正在遇到一个很像的问题。

就在刚刚,智谱率先在 GLM-5.1 线上生产集群中完成了新一代组网架构 ZCube 的规模化落地。ZCube 发表于网络领域顶会ACM SIGCOMM 2025,被评价为「significantly change the way we think about and understand networking/显著改变整个行业对网络认知方式」。
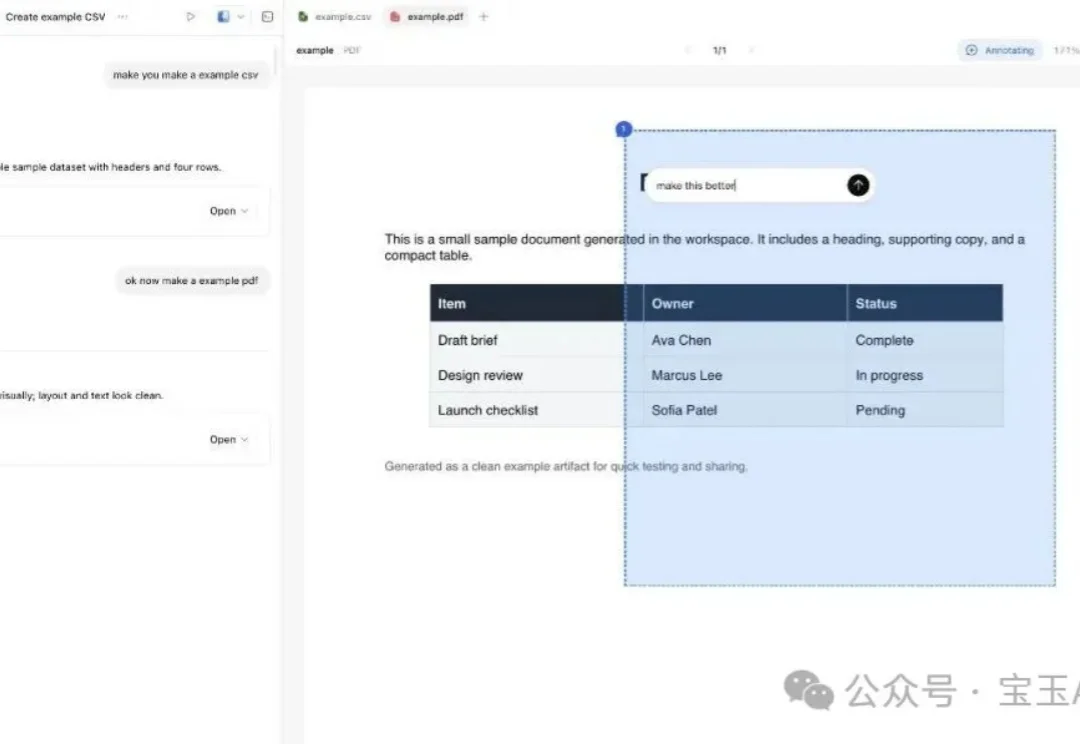
大多数开发者刚接触代码编辑类的 AI 智能体 (AI Agent) 时,通常只让它们干一件事:写代码。比如让它检查一下代码库,生成个差异对比 (diff),跑跑测试,然后再提个合并请求 (pull request)。
2026 年以来,OpenAI、Anthropic、LangChain 等机构纷纷发布关于 Harness Engineering 的技术博客,OpenClaw、Hermes Agent 等项目的火爆更让 Harness Engineering 成为业界热词。人们的共识正在形成:模型的能力释放,依赖于一套精密的外部框架。
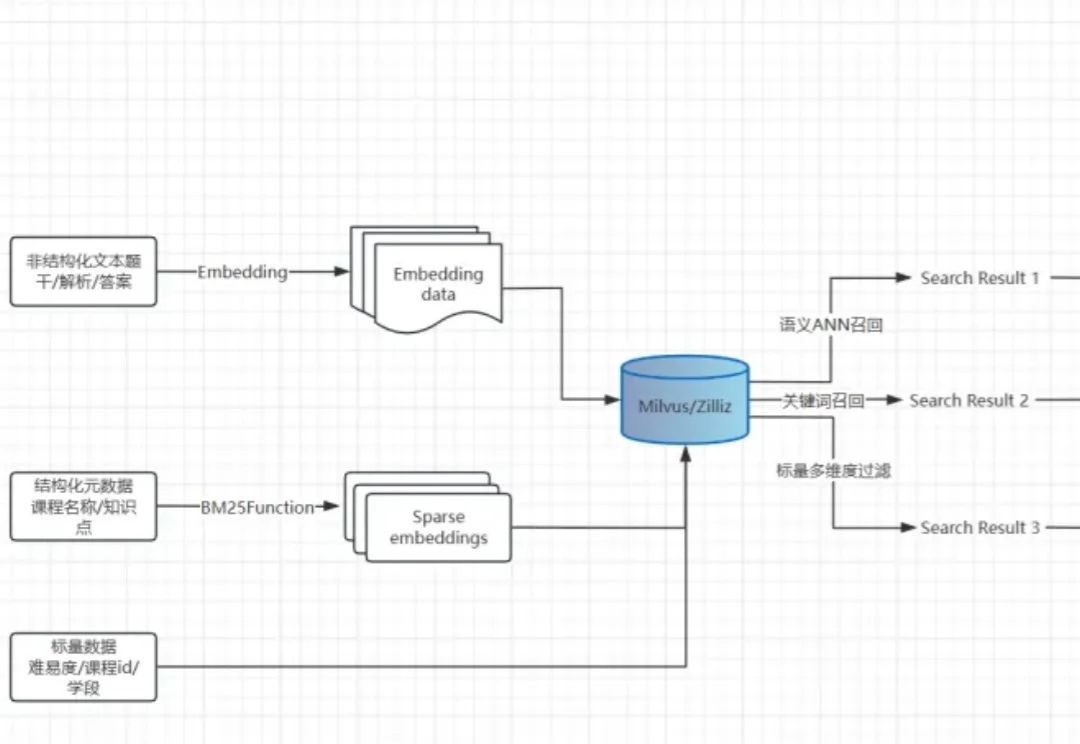
在教育科技领域,题库是核心资产,更是连接学生、教师与知识体系的关键入口。
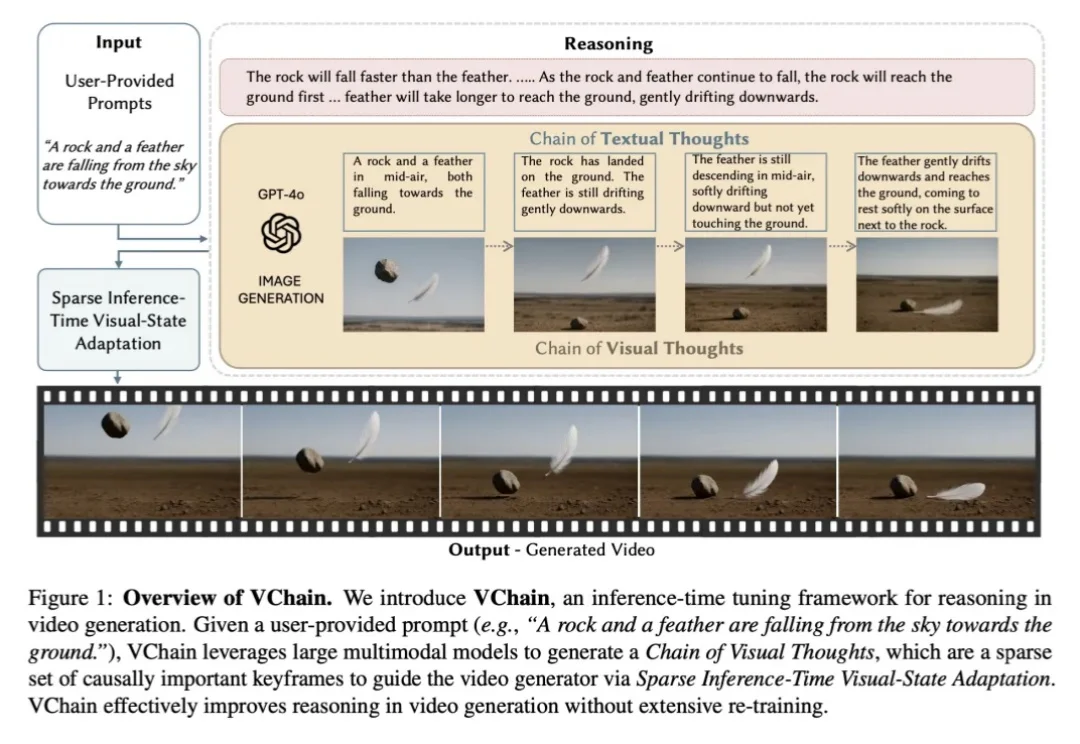
当视频生成模型在视觉保真度上不断突破时,一个核心瓶颈正变得愈发清晰:模型是否真正理解了真实世界?能否推理出合理的演变过程?
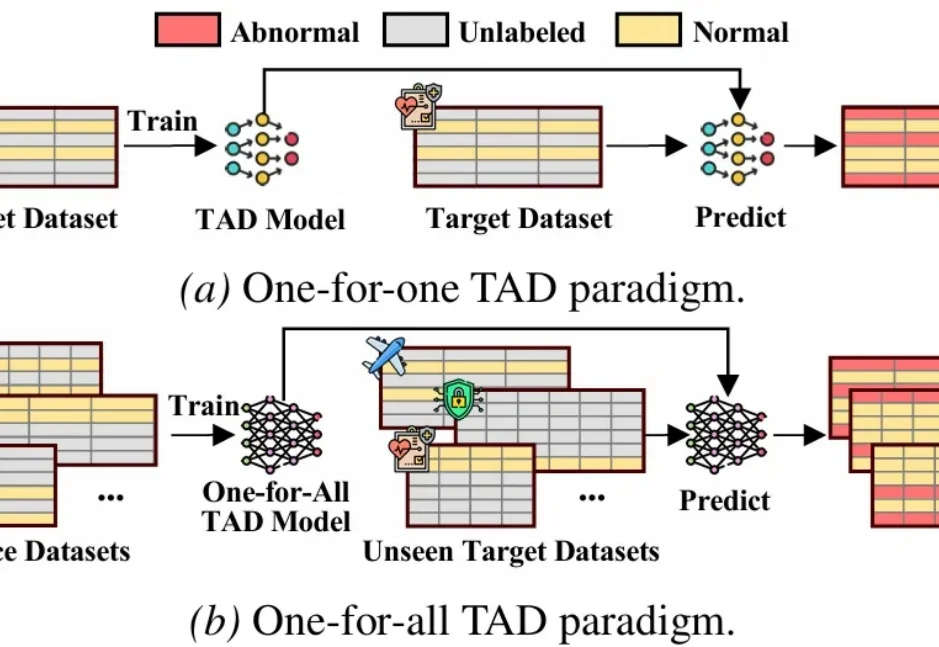
表格异常检测(Tabular Anomaly Detection,TAD)旨在从结构化数据中精准识别显著偏离正常分布的稀有样本,其在医疗诊断、金融风控及网络安全等关键领域的数据挖掘与安全保障任务中发挥着核心作用。

RAG 系统上线后答案出错,绝大多数团队的第一反应都是换更贵的模型、反复调试 prompt。
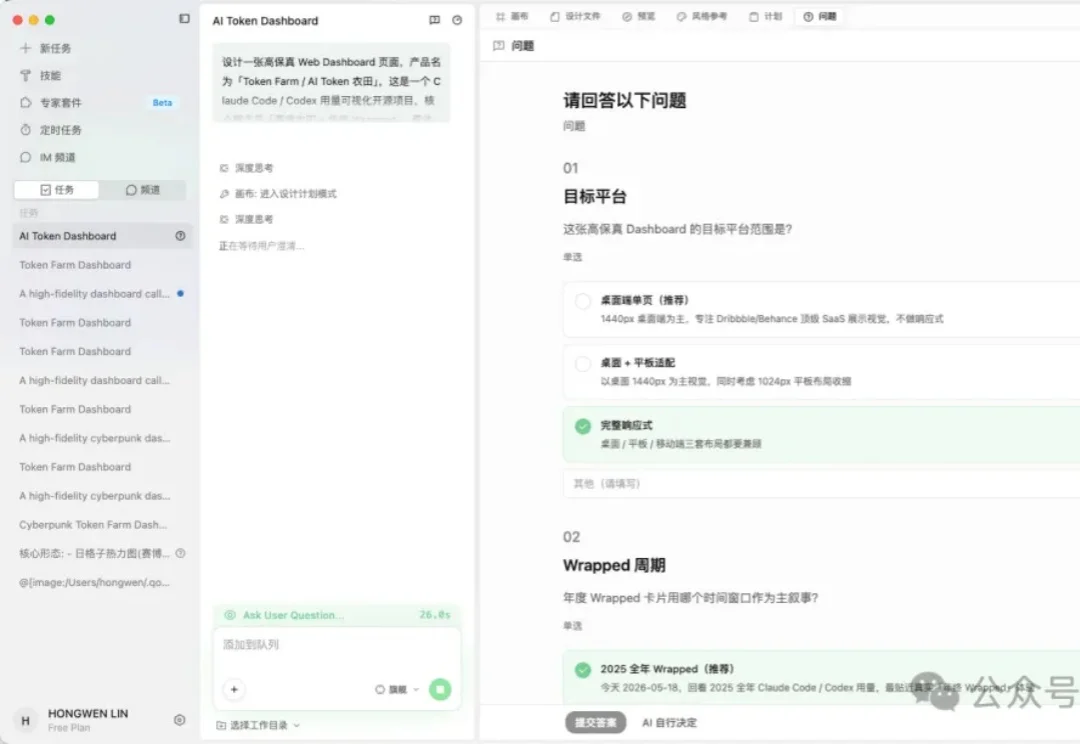
阿里的 QoderWork 最新上线了一个设计工作台(Design Desk),定位是用自然语言做出可交付的专业设计,从想法到工程级产物,中间不需要 Figma。

游戏规则要被改写了!Hermes Agent一键把模型订阅变成标准API,零成本驱动全套工具链。Grok同步杀入Agent生态。

近日,谷歌 DeepMind 研究员 Lun Wang@lunwang1996,在 x 上发文宣布自己已经从 DeepMind 离职,结束了这段非常精彩的旅程,「我非常感谢曾经共事的人、我们一起打造的东西,以及我在将前沿 AI 研究推向生产环境过程中学到的经验。」

刚刚 Anthropic 又给他们的官方 Managed Agents 加了俩功能:自托管沙箱 self-hosted sandboxes 和 MCP 隧道 MCP tunnels

奥赛级科学推理,一定要从更大的通用模型开始吗?
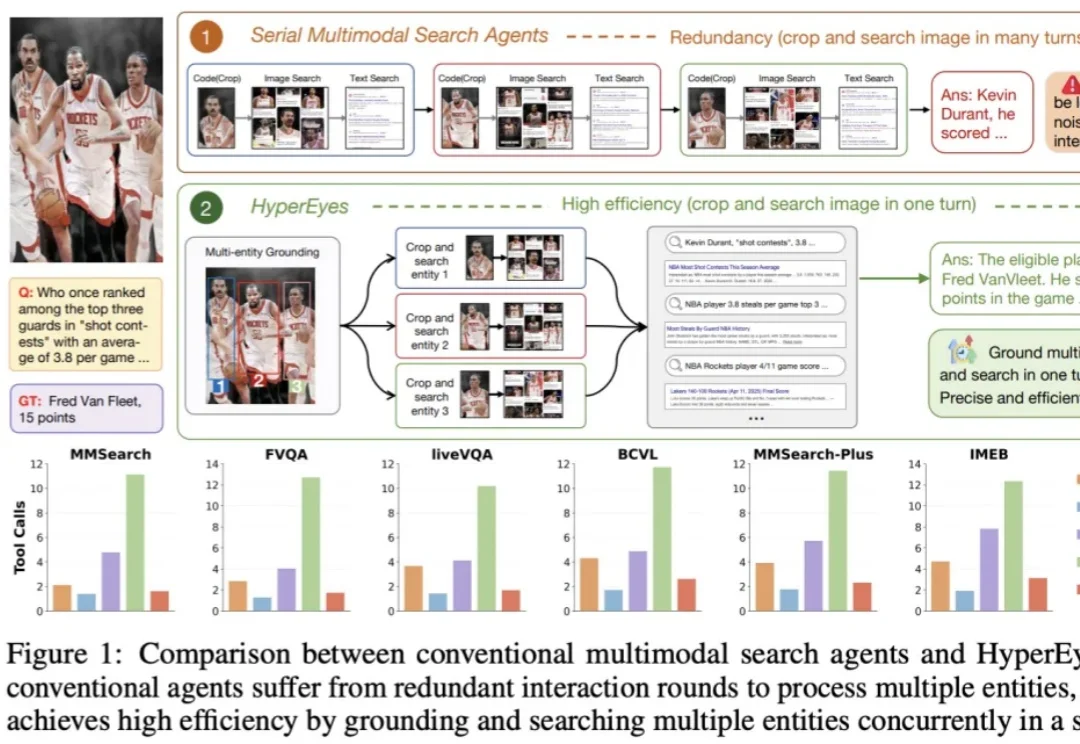
现有的开源多模态搜索智能体普遍受困于「裁剪 - 再搜索」的串行处理模式,面对多目标时往往陷入交互冗长、错误级联累积的泥沼。

攻克AI落地难题,清华团队推出RWAI框架与真实场景竞技场,通过标准化人机交互、任务集机制与人类反馈体系,显著提升产业应用效率。平台已实现落地周期缩短70%以上,并为AI开发者和企业提供了可复制的最佳实践。
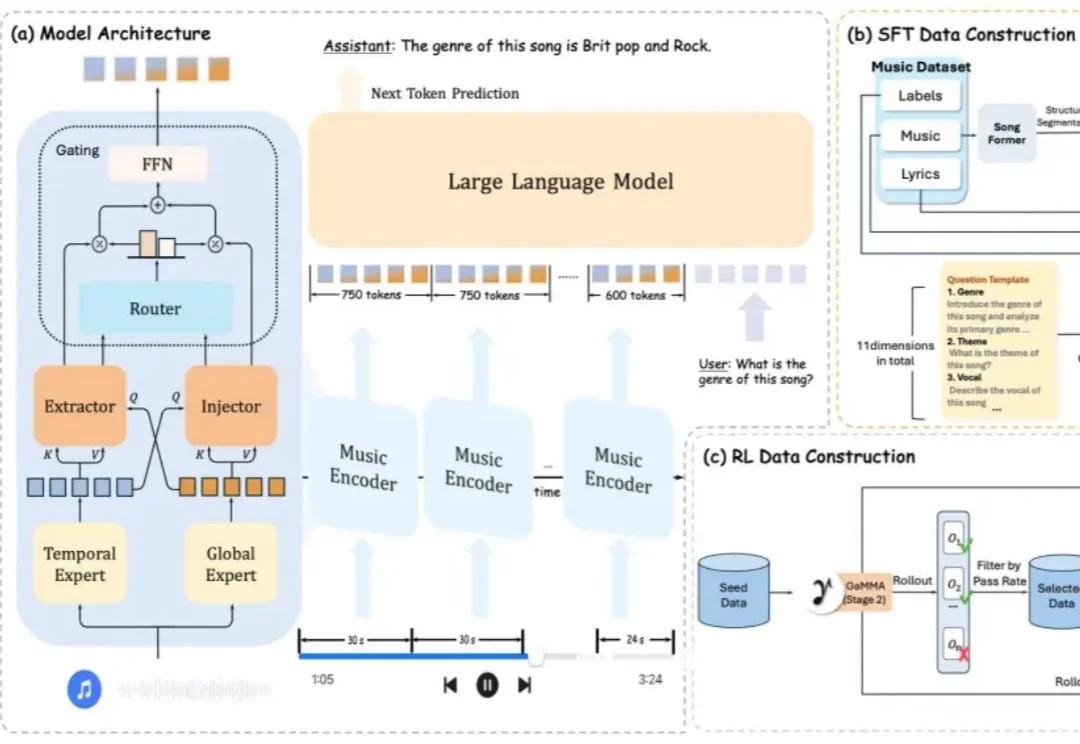
大模型的能力边界正在不断拓展,从文字到视觉,再到音频,全模态理解已渐成现实。然而,当你问一个多模态大模型「这首歌的高潮从第几秒开始?」或者「第 30 秒之后乐器编配发生了什么变化?」,得到的往往是一个模糊甚至错误的回答。
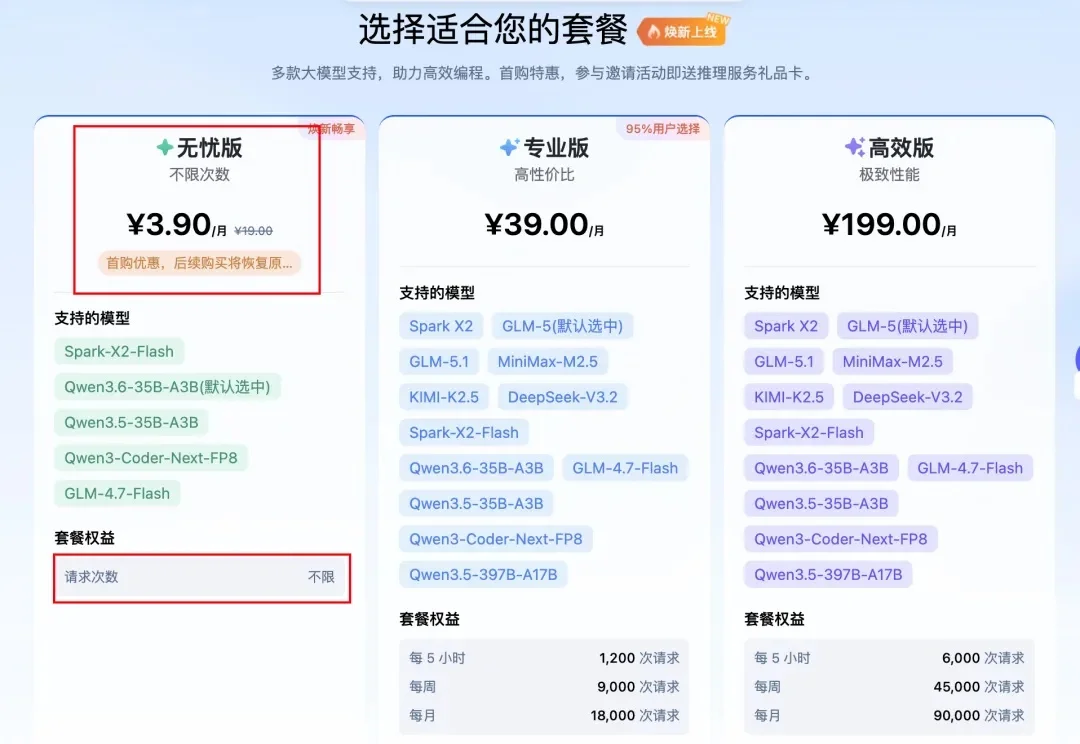
过去一段时间,很多人对大模型都有一个明显感受:token 总是不够用。

伯克利等发布FST框架:通过快慢分层解决大模型持续学习死局。