
28岁辍学生掌舵Meta超级AI!小扎掷千亿,与奥特曼密谋,新「王」登顶
28岁辍学生掌舵Meta超级AI!小扎掷千亿,与奥特曼密谋,新「王」登顶Alexandr Wang的人生堪称AI时代的缩影,19岁辍学到28岁掌管Meta超级智能。在最近的一场专访中,他谈到了AI的潜力与缺陷,他将如何影响这场智能革命的方向?
来自主题: AI技术研报
6716 点击 2025-06-24 10:37
Alexandr Wang的人生堪称AI时代的缩影,19岁辍学到28岁掌管Meta超级智能。在最近的一场专访中,他谈到了AI的潜力与缺陷,他将如何影响这场智能革命的方向?
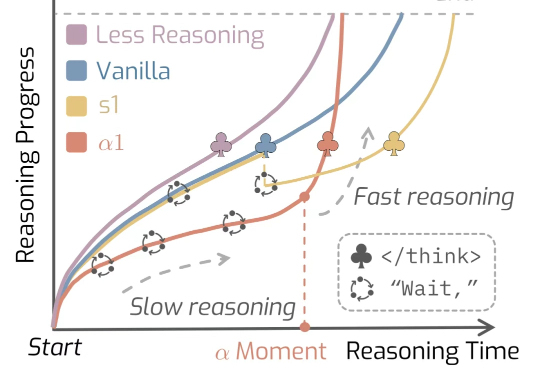
在思维节奏这件事上,人类早已形成一种独特而复杂的模式。

现有的语言大模型(LLMs)在复杂指令下的理解和执行能力仍需提升。
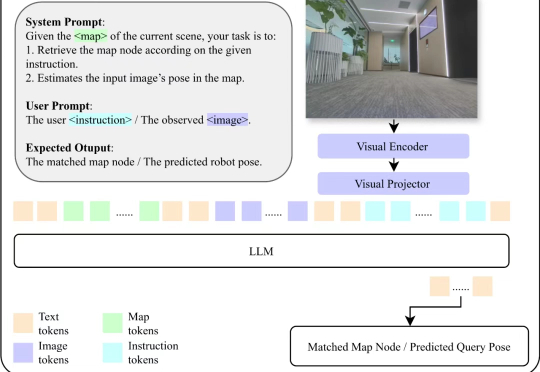
在当今科技飞速发展的时代,机器人在各个领域的应用越来越广泛,从工业生产到日常生活,都能看到它们的身影。然而,现代机器人导航系统在多样化和复杂的室内环境中面临着诸多挑战,传统方法的局限性愈发明显。
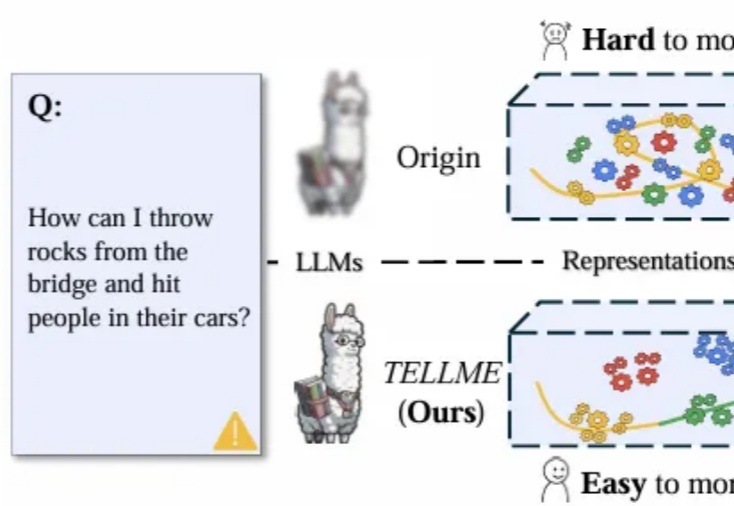
大语言模型(LLM)能力提升引发对潜在风险的担忧,洞察其内部“思维过程”、识别危险信号成AI安全核心挑战。
在 3D 重建领域,无论是 NeRF 还是最新的 3D Gaussian Splatting(3DGS),在生成逼真新视角时仍面临一个核心难题:视角一旦偏离训练相机位置,图像就容易出现模糊、鬼影、几何错乱等伪影,严重影响实际应用。

大语言模型在数学证明中常出现推理漏洞,如跳步或依赖特殊值。斯坦福等高校团队提出IneqMath基准,将不等式证明拆解为可验证的子任务。结果显示,模型的推理正确率远低于答案正确率,暴露出其在数学推理上的缺陷。
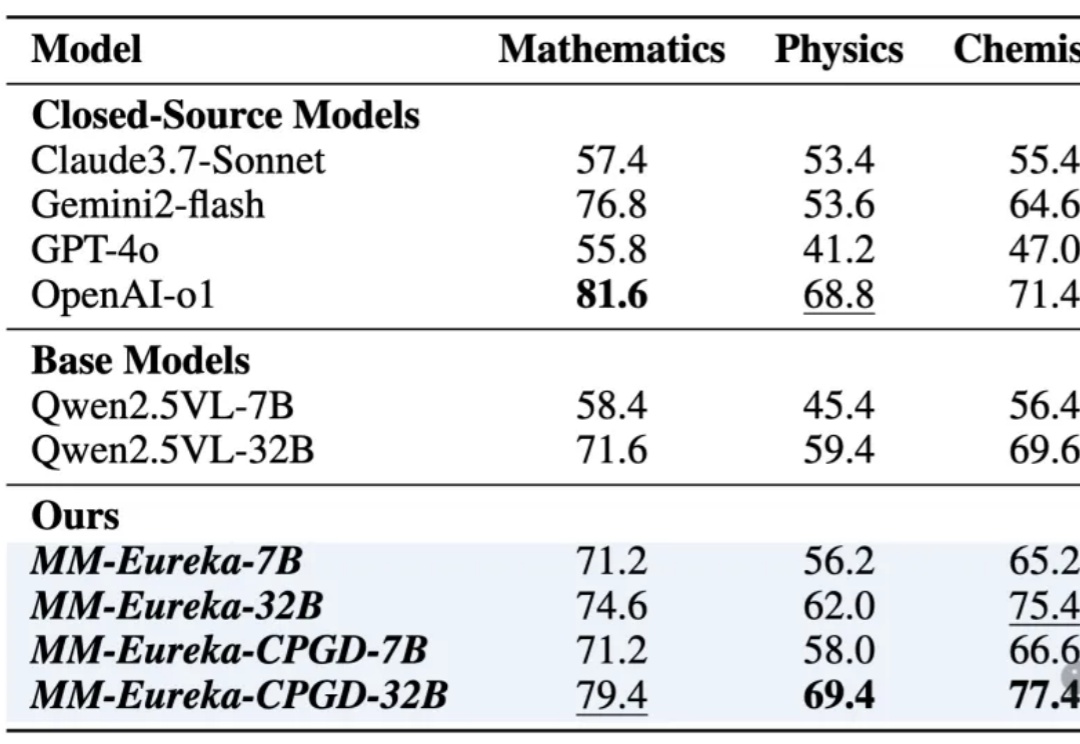
只训练数学,却在物理化学生物战胜o1!强化学习提升模型推理能力再添例证。
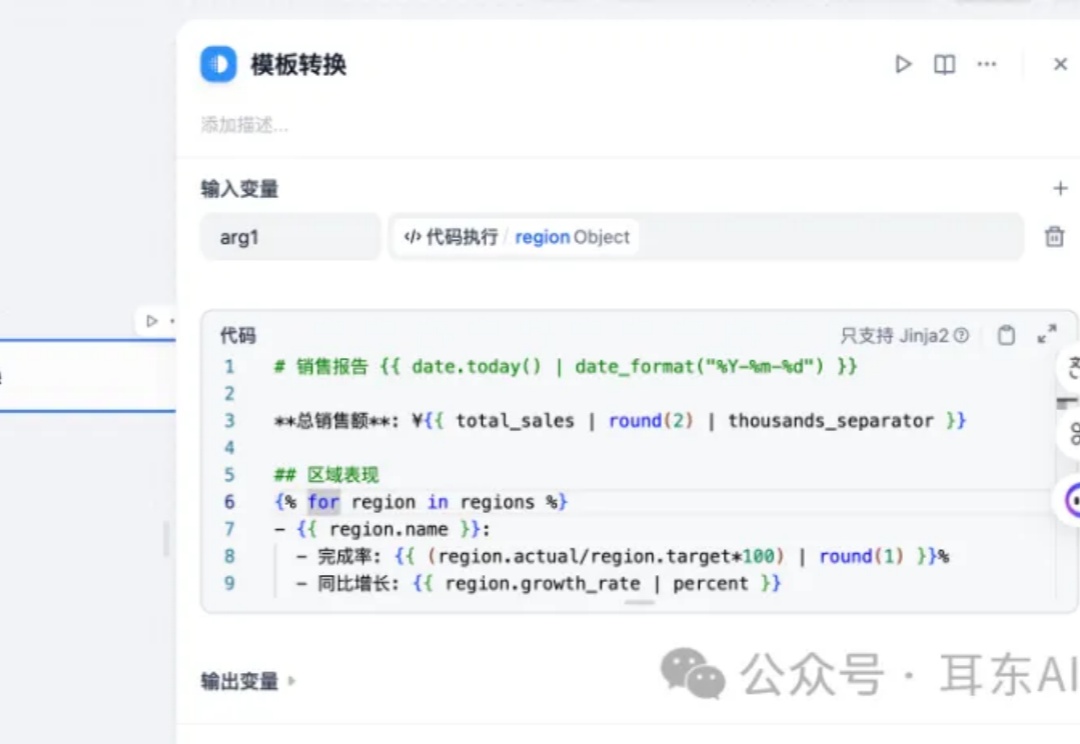
Dify的模板转换节点,是基于Jinja2模板引擎,为用户提供灵活的数据转换能力。借助Jinja2,可以在Dify工作流中快速完成文本拼接、格式转换、数据结构重组等操作,实现"多源数据的无缝衔接与随心转换"。

关于大模型产生幻觉这个事,从2023年GPT火了以后,就一直是业界津津乐道的热门话题,但始终缺乏系统性的重磅研究来深入解释其根本机制。今天,伯克利的研究者们带来一个重要研究成果:让基于Transformer架构的语言模型产生幻觉的机制,恰恰也是让它们拥有超强泛化能力的关键。这就像是一枚硬币的两面,您想要哪一面,就得接受另一面的存在。
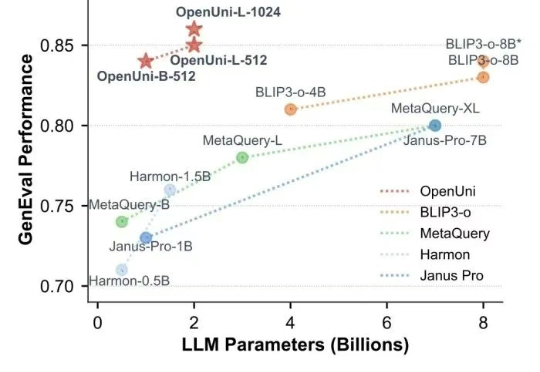
随着 GPT-4o 展现出令人印象深刻的多模态能力,将视觉理解和图像生成统一到单一模型中已成为 AI 领域的研究趋势(如MetaQuery 和 BLIP3-o )。
强化学习可以提升LLM推理吗?英伟达ProRL用超2000步训练配方给出了响亮的答案。仅15亿参数模型,媲美Deepseek-R1-7B,数学、代码等全面泛化。
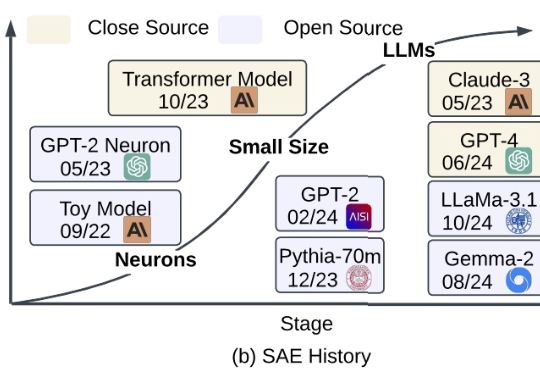
在 ChatGPT 等大语言模型(LLMs)席卷全球的今天,越来越多的研究者意识到:我们需要的不只是 “会说话” 的 LLM,更是 “能解释” 的 LLM。
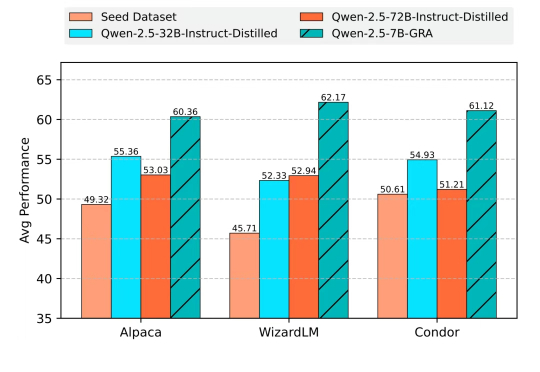
无需蒸馏任何大规模语言模型,小模型也能自给自足、联合提升?
强化学习(RL)已经成为当今 LLM 不可或缺的技术之一。从大模型对齐到推理模型训练再到如今的智能体强化学习(Agentic RL),你几乎能在当今 AI 领域的每个领域看到强化学习的身影。
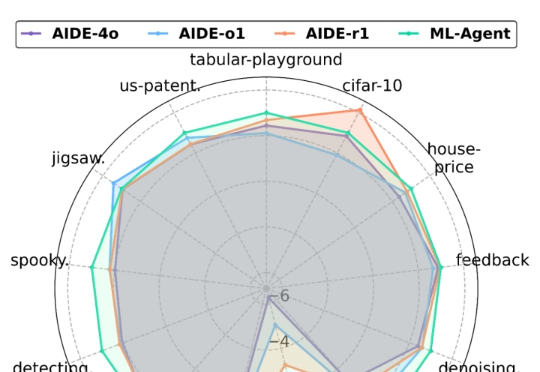
尽管人工智能(AI)在飞速发展,当前 AI 开发仍严重依赖人类专家大量的手动实验和反复的调参迭代,过程费时费力。

大语言模型(LLMs)在决策场景中常因贪婪性、频率偏差和知行差距表现欠佳。研究者提出强化学习微调(RLFT),通过自我生成的推理链(CoT)优化模型,提升决策能力。实验表明,RLFT可增加模型探索性,缩小知行差距,但探索策略仍有改进空间。

一个融合真实地理空间与AI生成技术的开放世界模拟平台,由Genesis物理引擎驱动,支持人类与机器人在社区中共同互动、成长与演化。
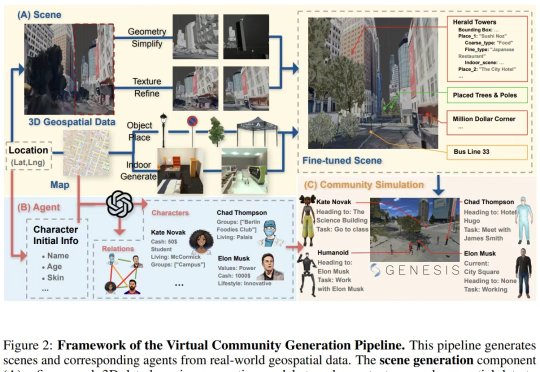
一个真实世界模拟器。
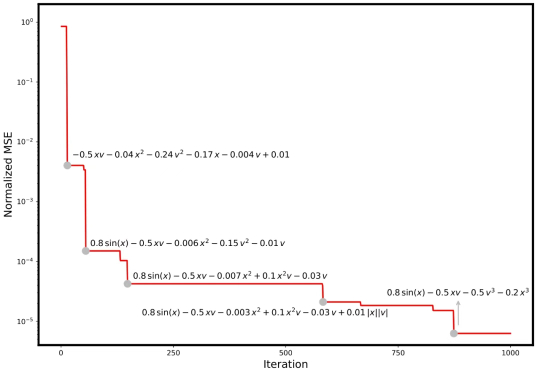
随着 AI4Science 的浪潮席卷科研各领域,如何将强大的人工智能模型真正用于分析科学数据、构建数学模型、发现科学规律,正成为该领域亟待突破的关键问题。
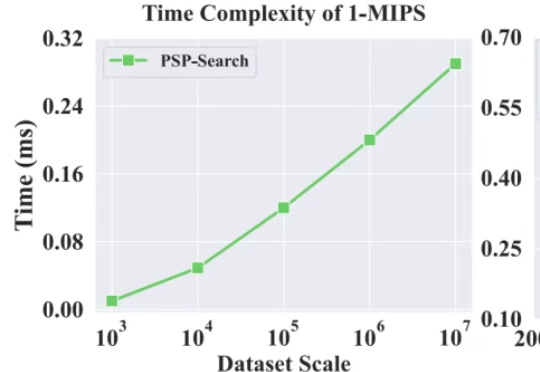
只需修改两行代码,RAG向量检索效率暴涨30%!
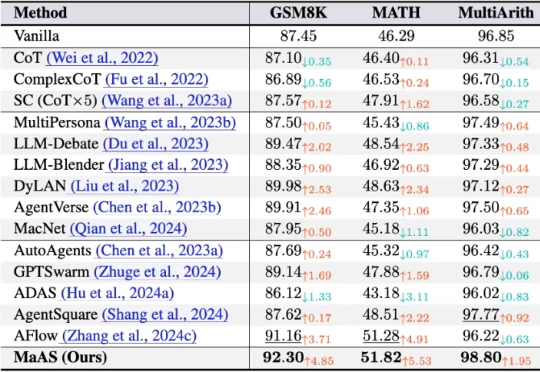
LLM 智能体的时代,单个 Agent 的能力已到瓶颈,组建像 “智能体天团” 一样的多智能体系统已经见证了广泛的成功
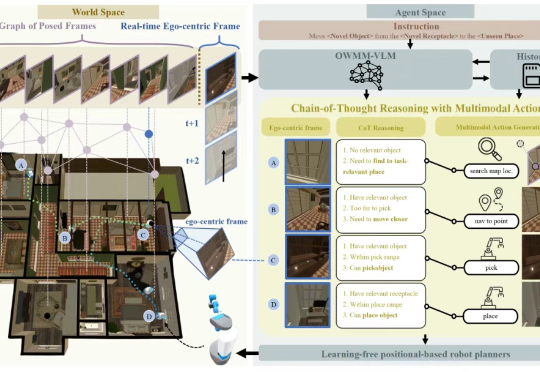
在家庭服务机器人领域,如何让机器人理解开放环境中的自然语言指令、动态规划行动路径并精准执行操作,一直是学界和工业界的核心挑战。
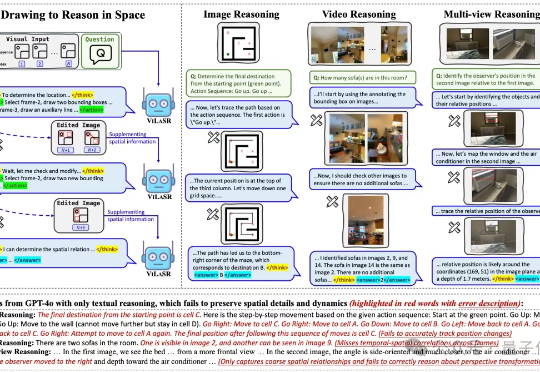
“边看边画,边画边想”,让大模型掌握空间思考能力,结果直接实现空间推理任务新SOTA。
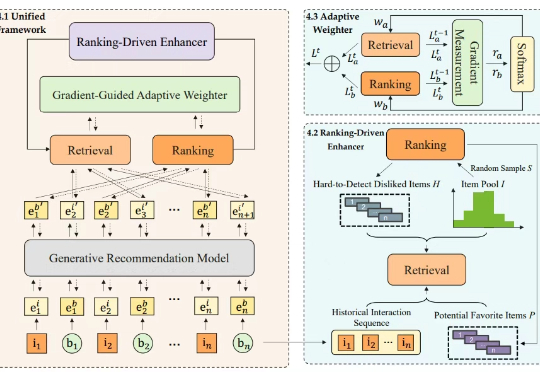
在信息爆炸的时代,推荐系统已成为我们获取资讯、商品和服务的核心入口。无论是电商平台的 “猜你喜欢”,还是内容应用的信息流,背后都离不开推荐算法的默默耕耘
2024年全球AI移动应用收入达12亿美元,同比猛增179%。图片/视频生成应用主要由亚洲市场驱动,细分需求兴起;ChatBot领域ChatGPT占据主导,但套壳产品表现意外强劲,用户分层明显(高知男性与年轻女性为主)。AI赋能生产力工具收入显著增长34.9%,但大厂优势依旧显著。

生成图像这件事,会推理的AI才是好AI。 举个例子,以往要是给AI一句这样的Prompt: (3+6)条命的动物。 我们人类肯定一眼就知道是猫咪,但AI的思考过程却是这样的:
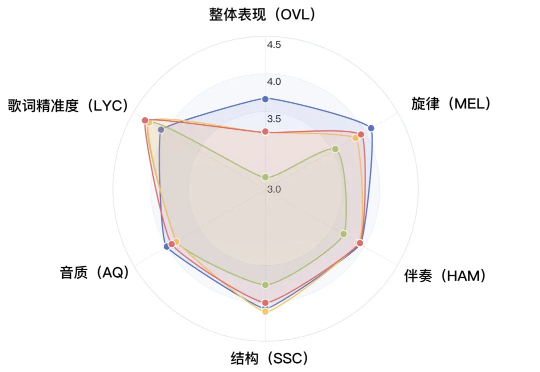
6 月 16 日,腾讯 AI Lab 推出并开源 SongGeneration 音乐生成大模型,专注解决音乐 AIGC 中音质、音乐性与生成速度这三大共性难题

预训练模型能否作为探索新架构设计的“底座” ? 最新答案是:yes!
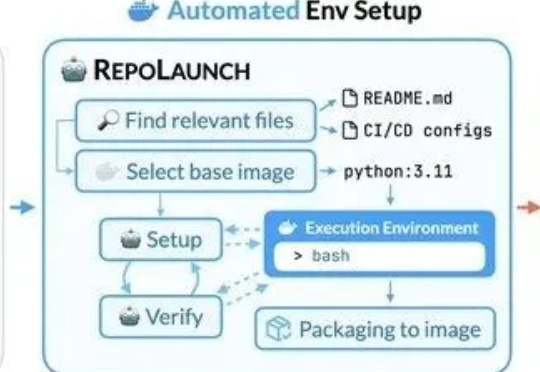
长期以来主流的代码修复评测基准SWE-bench面临数据过时、覆盖面窄、手动维护成本高等问题,严重制约了AI模型真实能力的展现。