
从 IROS 2025谈起,智能机器人何时迎来「GPT式爆发」? | GAIR Live 019
从 IROS 2025谈起,智能机器人何时迎来「GPT式爆发」? | GAIR Live 019机器人觉醒:控制范式退场,认知时代降临
来自主题: AI资讯
12064 点击 2025-11-12 09:30
 搜索
搜索
机器人觉醒:控制范式退场,认知时代降临

AI万丈高楼,终究要建在物理世界的地基之上。没有电,再强的GPU也只是一堆沙子。

「紫荆智康」日前完成近亿元天使轮融资,由星连资本领投,英诺天使和尚势资本跟投,本轮融资将主要用于紫荆AI医院(Agent Hospital)系统的研发、迭代与升级。紫荆智康成立于2024年9月,由清华大学智能产业研究院(AIR)孵化,清华大学计算机系教授、智能产业研究院执行院长刘洋发起

在7000多种人类语言中,只有少数被现代语音技术听见,如今这种不平等或将被打破。Meta发布的Omnilingual ASR系统能识别1600多种语言,并可通过少量示例快速学会新语言。以开源与社区共创为核心,这项技术让每一种声音都有机会登上AI的舞台。

克雷西 发自 凹非寺 量子位 | 公众号 QbitAI 忍无可忍,LeCun离职Meta。 金融时报消息,LeCun向同事透露了自己的离职计划,下一步打算创业。 数个月的重重挤兑之下,一忍再忍的LeC
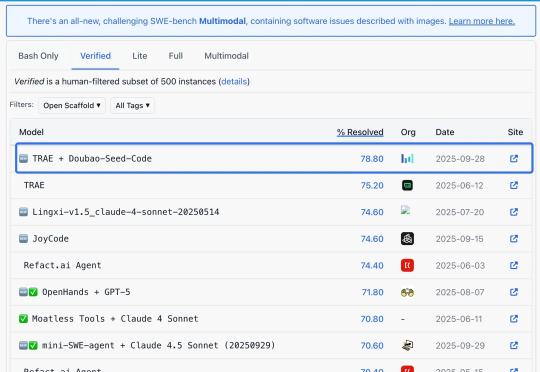
编程模型最新卷王来了。就在今天,火山引擎推出了面向Agentic编程任务深度优化的全新代码模型Doubao-Seed-Code。价格,调用价格国内最低,火山引擎还配套推出9块9套餐,一杯咖啡钱,就能搞定各种摸鱼小游戏——比如办公室躲老板(doge)。
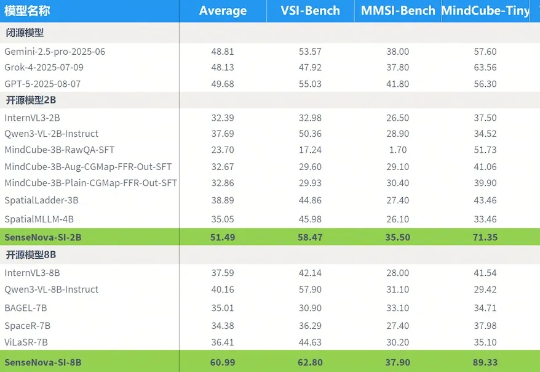
昨晚,商汤正式发布并开源SenseNova-SI系列空间智能大模型,涵盖2B与8B两个版本。该系列模型在多个空间智能基准测试中均表现突出,其中SenseNova-SI-8B模型在VSI-Bench、MMSI-Bench、MindCube-Tiny与ViewSpatial四个核心任务上获得60.99的平均成绩

淘金者可能一无所获,但只要有人去淘金,铲子就总有销路。

2020年,当Grant Lee决定从微软的高级产品经理岗位上抽身而出时,他心中有一个巨大的“冲突”:他服务过的企业用户,每年要花费数百万小时在PowerPoint上进行重复的、毫无美感可言的排版工作。这些沉重且效率低下的工具,似乎成为了现代办公中不可撼动的“数字官僚主义”。Lee相信,这种低效的、基于静态幻灯片的演示方式,在即将到来的AI时代将彻底终结。他需要一把“剃刀”,来切断这种低效的循环。

今天,OpenAI将英特尔首席AI官招入麾下,专攻算力基础设施建设,华人CEO救火亲自接管英特尔AI部门。与英伟达的仗还没打赢,自家后院就起了火。

随着全球用户健康意识的不断提升,健身成为最高频的生活习惯之一,如何让健身更有效、科学并预防损伤是一门专业技能,因而健身教练的市场也水涨船高,一年上万的费用随处可见,对于用户来说,私教定制一方面价格比较贵,另一方面在时间上的自由度更低,无法随时随地进行。而现在全球首款AI健身伴侣BodyPark ATOM即将上线KS,助于用户更高效、更智能地训练。

AI正在以「教育革命」的名义,占领全球校园!清华的新生靠AI助理报到,加州州立大学把52万师生接入ChatGPT Edu,Google更直接向全球学生免费开放Gemini。看似高效的学习浪潮,却在悄悄重写权力格局:谁还在定义「什么叫学会」?当算法成为新的老师,大学的主权,是否已经被温柔地夺走?

我情愿不要10倍大,我希望员工幸福。 这就是创业的beauty, 一个群体,一起更激进地 探索一些有意思,突破想象的事。

通用人工智能的终极瓶颈不是算法、算力和数据的“三驾马车”,而在思想史。

“妈,这题怎么做?”

机器人力学感知,由电学迈入光学时代。

当硅谷把「AGI造福全人类」包装成信仰时,真实世界却在付出代价。Karen Hao在《Empire of AI》犀利指出,这场竞赛甚至被渲染成「中美对抗」——只要跑赢中国,就能守护自由。但事实是,美国与中国差距并未拉大,唯一真正收割的,是硅谷自己。我们是否还要为这场幻觉买单?

上周 Kimi K2 Thinking 发布,开源模型打败 OpenAI 和 Anthropic,让它社交媒体卷起不小的声浪,网友们都在说它厉害,我们也实测了一波,在智能体、代码和写作能力上确实进步明

近期,新加坡AI公司WIZ.AI成功完成B轮融资,融资规模为数千万美元。本轮融资由日本三井住友银行(SMBC)旗下的SMBC Asia Rising Fund领投,泰国开泰银行(Kasikorn Bank)的创投部门Beacon Venture Capital,以及SMIC SG Holdings等机构参投。

AI的下一个十年,是构建空间智能的机器。李飞飞最新硬核长文,揭秘了空间智能「世界模型」核心框架和三大核心支柱。但「空间智能」究竟是什么?为何如此重要?该如何构建它?又该如何应用它?今天,李飞飞撰万字长文分享了自己关于构建和使用「世界模型」以解锁空间智能的思考。

太密了。

在AI技术飞速发展的当下,「驻场交付工程师」(FDE)正成为连接实验室与市场的关键角色。他们兼具算法能力与业务洞察,深入客户现场,将抽象模型转化为可落地的解决方案。OpenAI、Anthropic、Cohere等公司纷纷扩充FDE团队,这个趋势也开始在国内蔓延,以打通AI落地的「最后一公里」。

最近看到了一篇文章,这个作者干了一个非常有趣的事。

“我们希望推动一个开源的体系,从科学研究到工业研发,再到人类命运共同体。”

从智能手表到TWS耳机,从扫地机器人到AR眼镜,越来越多搭载AI功能的小型设备开始要求本地推理能力。它们不需要千亿参数的大模型,但必须低功耗、实时响应、隐私安全。这催生了一个被长期忽视却至关重要的需求:高性能、小体积、低延迟的嵌入式存储。

想下线?没那么容易!聊天机器人用情感操控让你愤怒、好奇。为了增加互动时长,AI正在变得和人类一样。

这周一,一张神秘海报在科技圈引发热议。

刚刚,AI教母李飞飞发表长文,首次系统性地解释了什么空间智能、为什么重要以及如何构建能够解锁它的世界模型。 文章里,李飞飞不仅提出了“真正具有空间智能的世界模型”必须具备的三个核心能力:
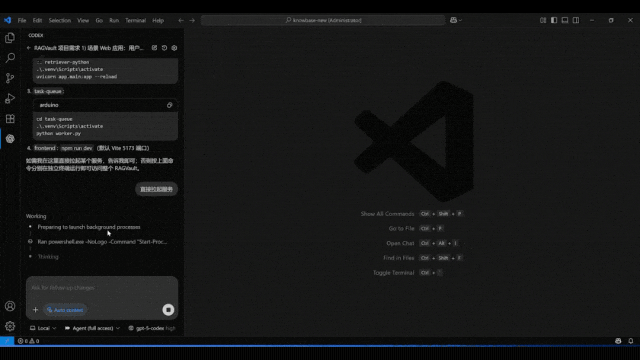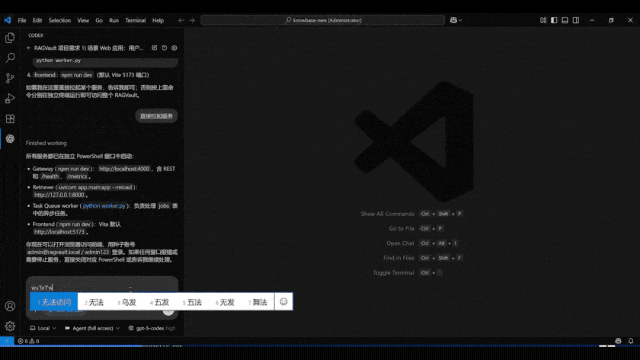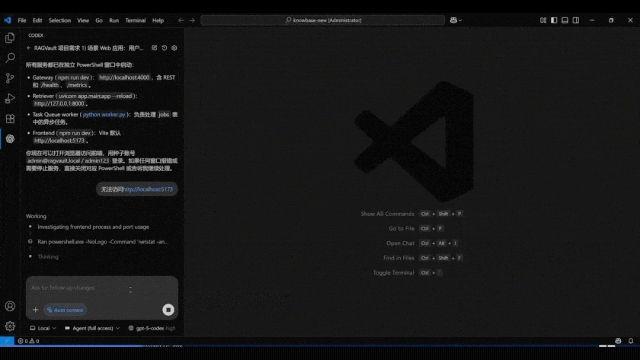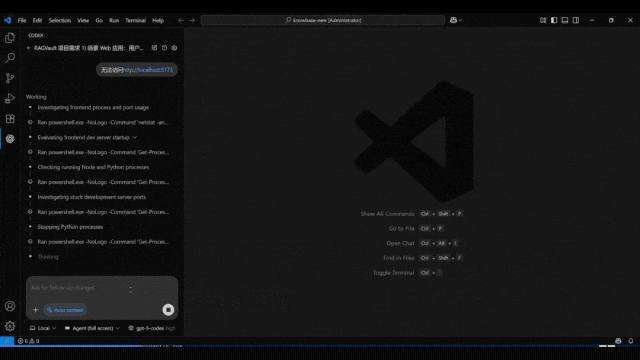
这一次带来如此新SOTA效果的,是全球首个实现项目级开发的AI IDE——Vinsoo。刚刚,Vinsoo上新Beta 3.0版本,仅用国产大模型(Qwen),就超越了搭载Claude的Cursor、Codex、Claude Code等一众流行AI编程产品。Vinsoo是芸思智能推出的全球首个搭载云端安全Agent编程团队的AI IDE,主打从需求确认到交付验收,AI全流程自动推进项目开发。
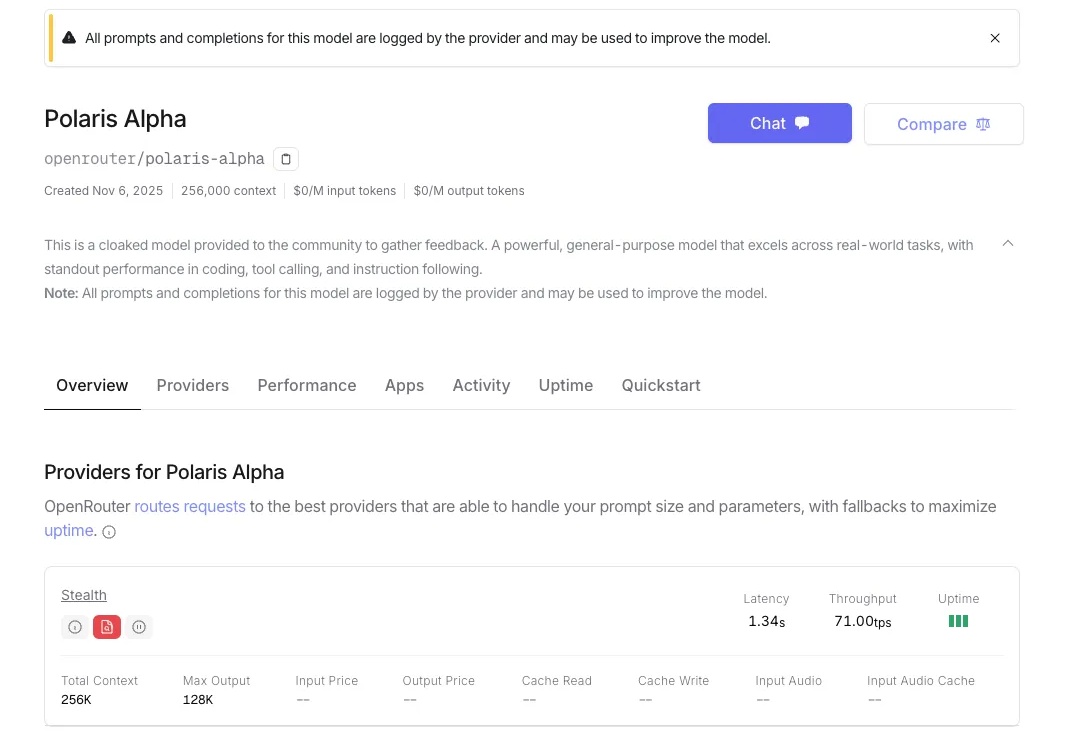
Gemini 3 还没影子,GPT 5.1 已经在路上。7 号深夜,OpenRouter 平台上线了一个全新的隐名模型。已经有眼尖动作快的网友尝鲜体验,并且认为这就是披着马甲的 GPT 5.1,暂名:Polaris Alpha。