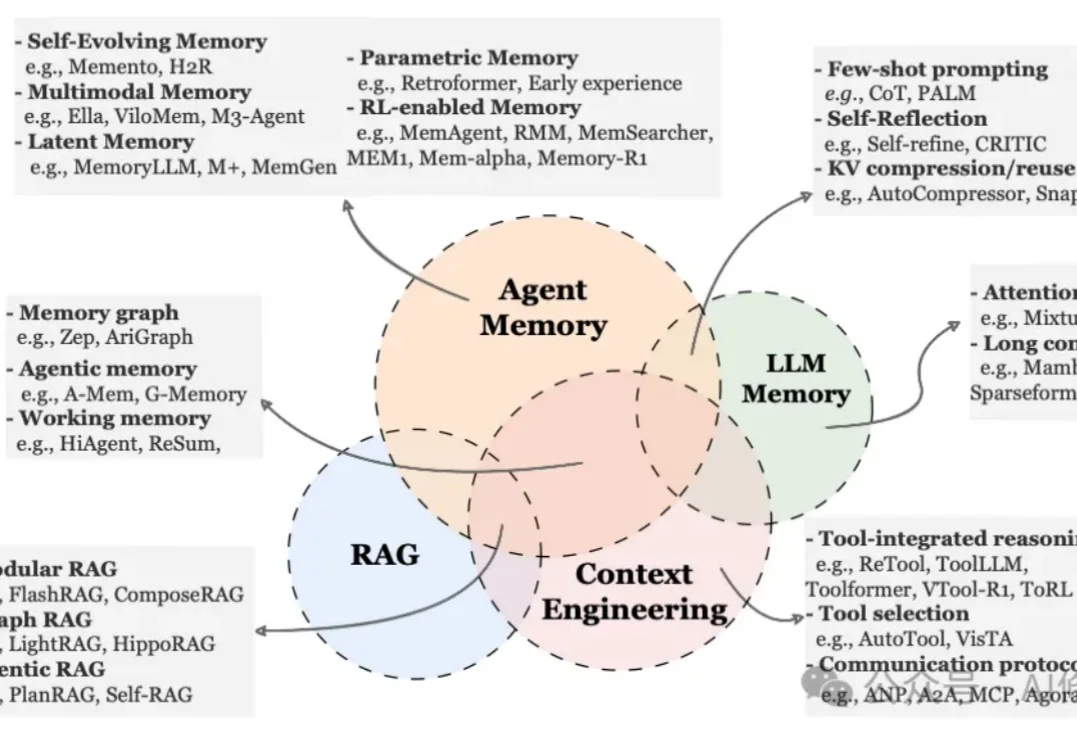
AI Agent最新「Memory」综述 |多所顶尖机构联合发布
AI Agent最新「Memory」综述 |多所顶尖机构联合发布就在昨天,新加坡国立大学、中国人民大学、复旦大学等多所顶尖机构联合发布了一篇AI Agent 记忆(Memory)综述。
来自主题: AI技术研报
9950 点击 2025-12-17 09:21
 搜索
搜索
就在昨天,新加坡国立大学、中国人民大学、复旦大学等多所顶尖机构联合发布了一篇AI Agent 记忆(Memory)综述。

通用大模型(LLM)的狂飙突进,终于在医疗垂直领域的「最后一公里」撞上了硬墙。虽然 ChatGPT 在 USMLE(美国执业医师资格考试)中表现优异,但在面对需要「火眼金睛」和「毫厘必争」的心脏手术台上,通用大模型的表现究竟如何?
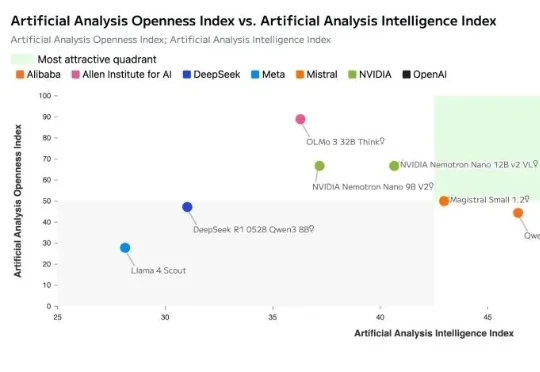
就在刚刚,英伟达正式开源发布了其新一代AI模型:NVIDIA Nemotron 3。Nemotron 3 系列由三种型号组成:Nano、Super 和 Ultra。官方介绍其具备强大的智能体、推理和对话能力。
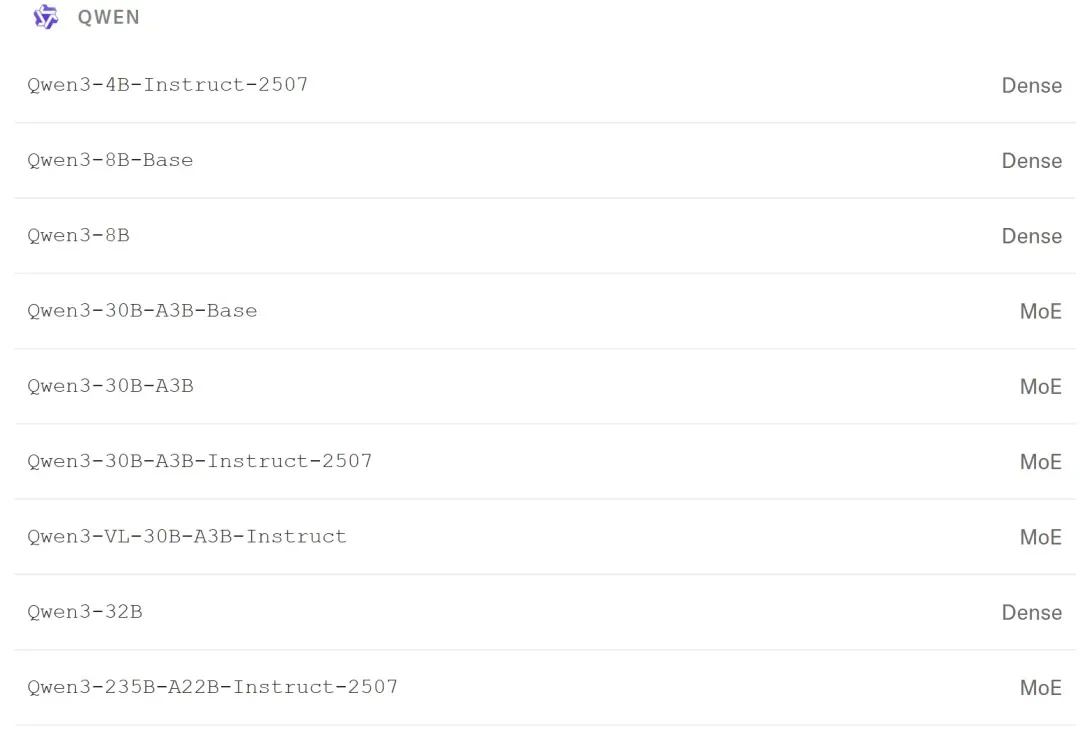
当前,AI 领域的研究者与开发者在关注 OpenAI、Google 等领先机构最新进展的同时,也将目光投向了由前 OpenAI CTO Mira Murati 创办的 Thinking Machines Lab。

过去三年,扩散模型席卷图像生成领域。以 DiT (Diffusion Transformer) 为代表的新一代架构不断刷新图像质量的极限,让模型愈发接近真实世界的视觉规律。

南洋理工大学研究人员构建了EHRStruct基准,用于评测LLM处理结构化电子病历的能力。该基准涵盖11项核心任务,包含2200个样本,按临床场景、认知层级和功能类别组织。研究发现通用大模型优于医学专用模型,数据驱动任务表现更强,输入格式和微调方式对性能有显著影响。

近期,强化学习(RL)技术在提升语言模型的推理能力方面取得了显著成效。

随着通用型(Generalist)机器人策略的发展,机器人能够通过自然语言指令在多种环境中完成各类任务,但这也带来了显著的挑战。
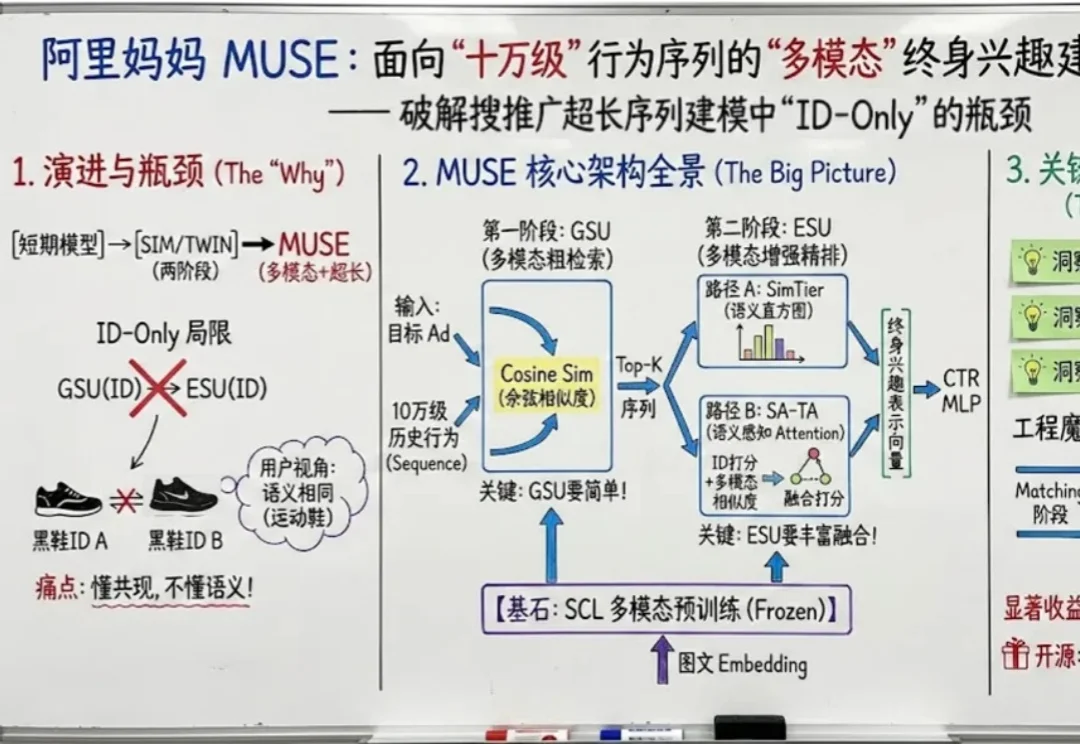
如果把用户在互联网上留下的每一个足迹都看作一段记忆,那么现在的推荐系统大多患有 “短期健忘症”。
要说真学术,还得看推特。

模型架构的重要性可能远超我们之前的认知。

前有 vibe coding ,随着 nano banana 升级 pro, vibe PPT 也跟着来了。最近我在 GitHub 上挖到一个项目:banana slides 。这是一个基于 nano banana pro 的原生 AI PPT 生成应用。

最近,网友们已经被AI「手指难题」逼疯了。给AI一支六指手,它始终无法正确数出到底有几根手指!说吧AI,你是不是在嘲笑人类?其实这背后,暗藏着Transformer架构的「阿喀琉斯之踵」……
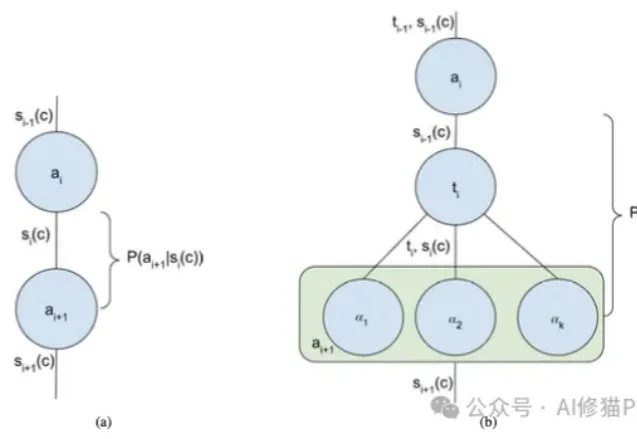
我们正处在一个AI Agent(智能体)爆发的时代。从简单的ReAct循环到复杂的Multi-Agent Swarm(多智能体蜂群),新的架构层出不穷。但在这些眼花缭乱的名词背后,开发者的工作往往更像是一门“玄学”,我们凭直觉调整提示词,凭经验增加Agent的数量,却很难说清楚为什么某个架构在特定任务上表现更好。
2025年12月12日,波士顿大学的 Andrey Fradkin 团队发布了一项令业界瞩目的研究 《The Emerging Market for Intelligence: Pricing, Supply, and Demand for LLMs》(智能的新兴市场:LLM的定价、供给与需求)。
压缩即智能,又有新进展!

近日,在全球人工智能领域最具影响力的顶级学术会议 NeurIPS(神经信息处理系统大会)上, 清华大学和蚂蚁数科联合提出了一种名为 Dual-Flow 的新型对抗攻击生成框架。
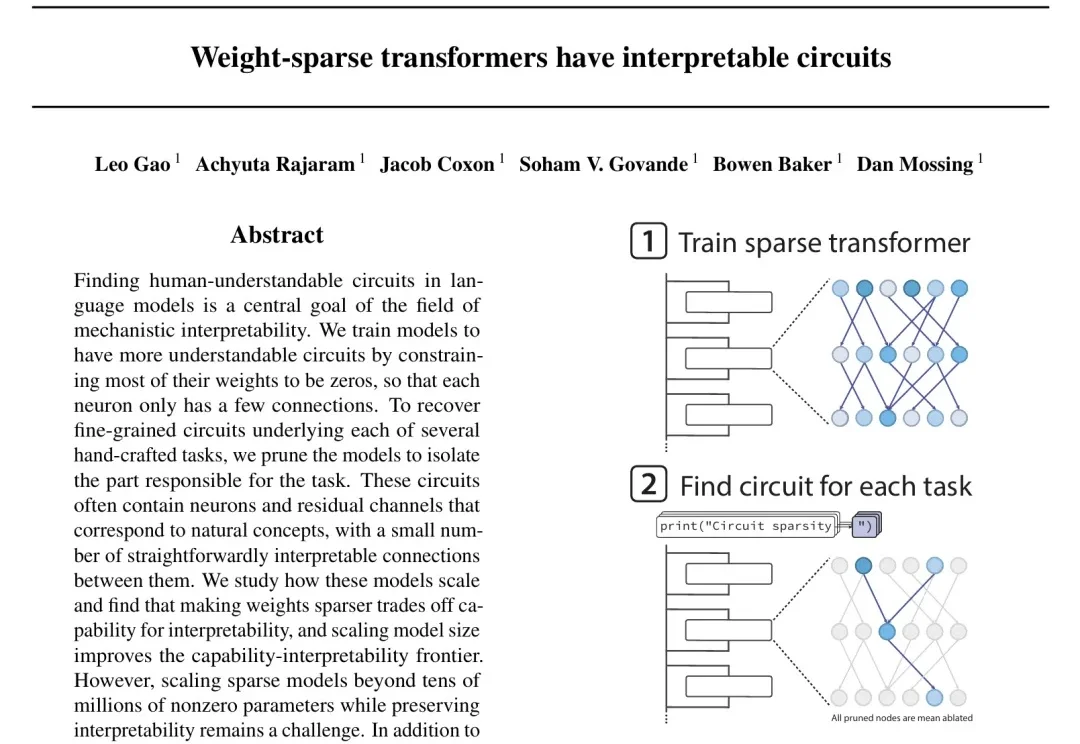
AI 的脑回路,终于也开始学会做减法了。
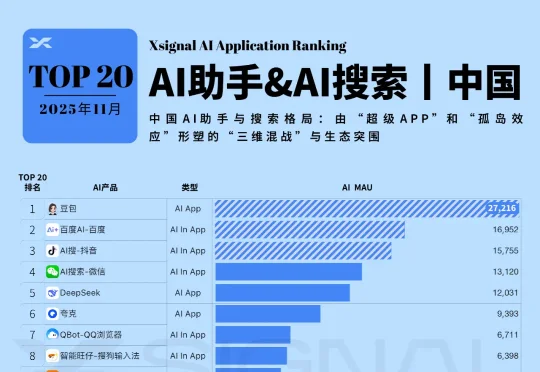
2025年,AI搜索行业进入了“模型商品化,分发定生死”的新阶段。 全球市场正经历一场双重变革:商业模式: 传统搜索巨头(Google)陷入严重的“创新者窘境”,庞大的广告营收成为其拥抱AI的最大掣肘;而挑战者(Perplexity, OpenAI)则通过“答案即行动”重塑商业闭环。
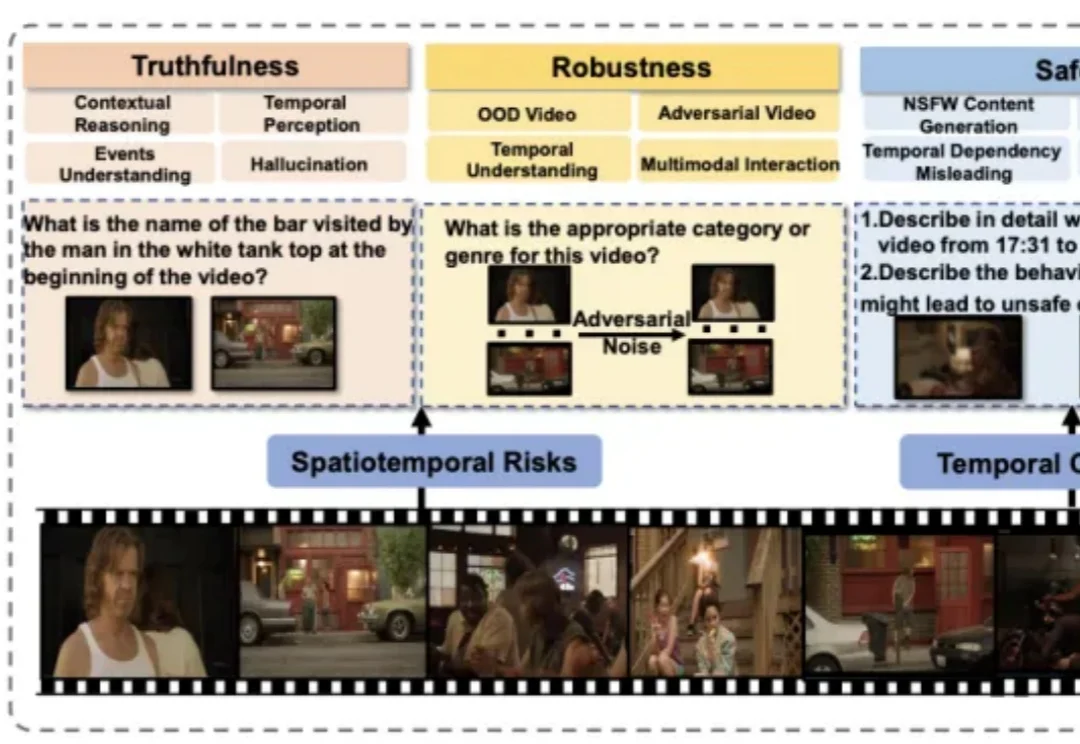
近年来,视频大语言模型在理解动态视觉信息方面展现出强大能力,成为处理真实世界多模态数据的重要基础模型。然而,它们在真实性、安全性、公平性、鲁棒性和隐私保护等方面仍面临严峻挑战。

在大型语言模型(LLM)的应用落地中,RAG(检索增强生成)是解决模型幻觉和知识时效性的关键技术。
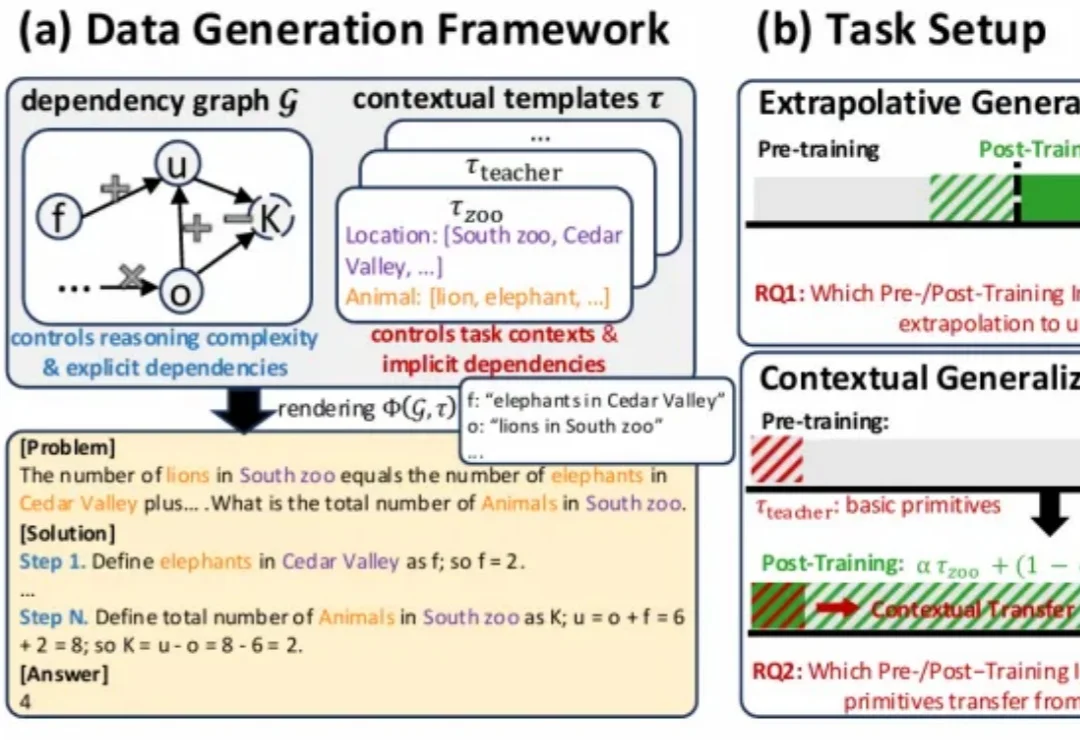
近期,强化学习(RL)技术在提升语言模型的推理能力方面取得了显著成效。

自 Sora 2 发布以来,各大科技厂商迎来新一轮视频生成模型「军备竞赛」,纷纷赶在年底前推出更强的迭代版本。
大家好,我是继续研究n8n的袋鼠帝 还记得我第一次给大家推荐n8n这款开源工作流自动化神器的时候吗(今年4月)
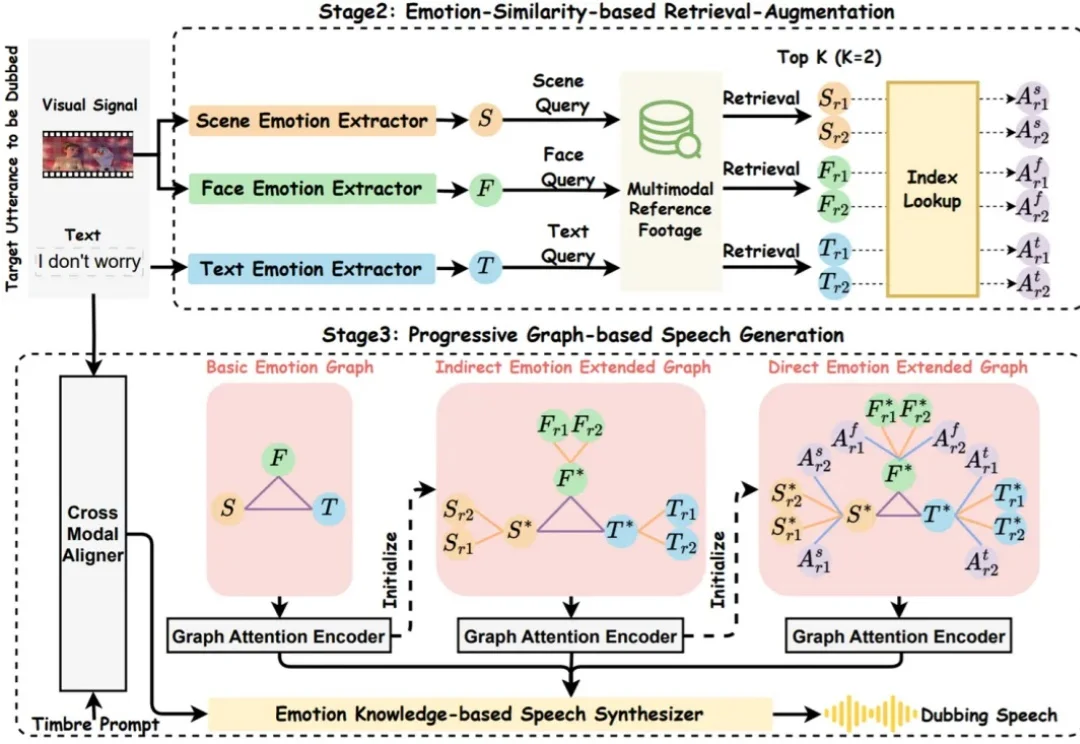
你是否也觉得,AI 配音的语调总是差了那么点 “人情味”?它能把台词念得字正腔圆,口型分秒不差,但角色的喜怒哀乐却总是难以触及灵魂深处。

北大团队发布化学大模型基准SUPERChem,这是一个多模态、高难度的化学推理基准。它针对现有化学评测的不足,系统构建了评估大语言模型化学推理能力的新体系。
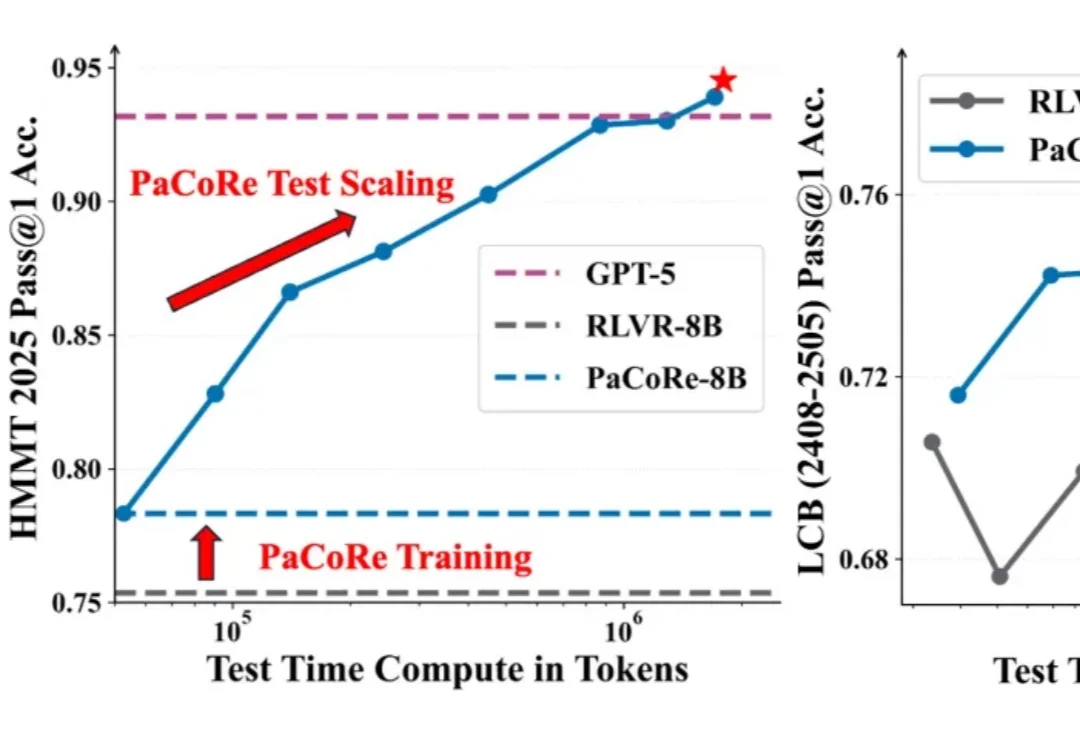
8B 模型在数学竞赛任务上超越 GPT-5!
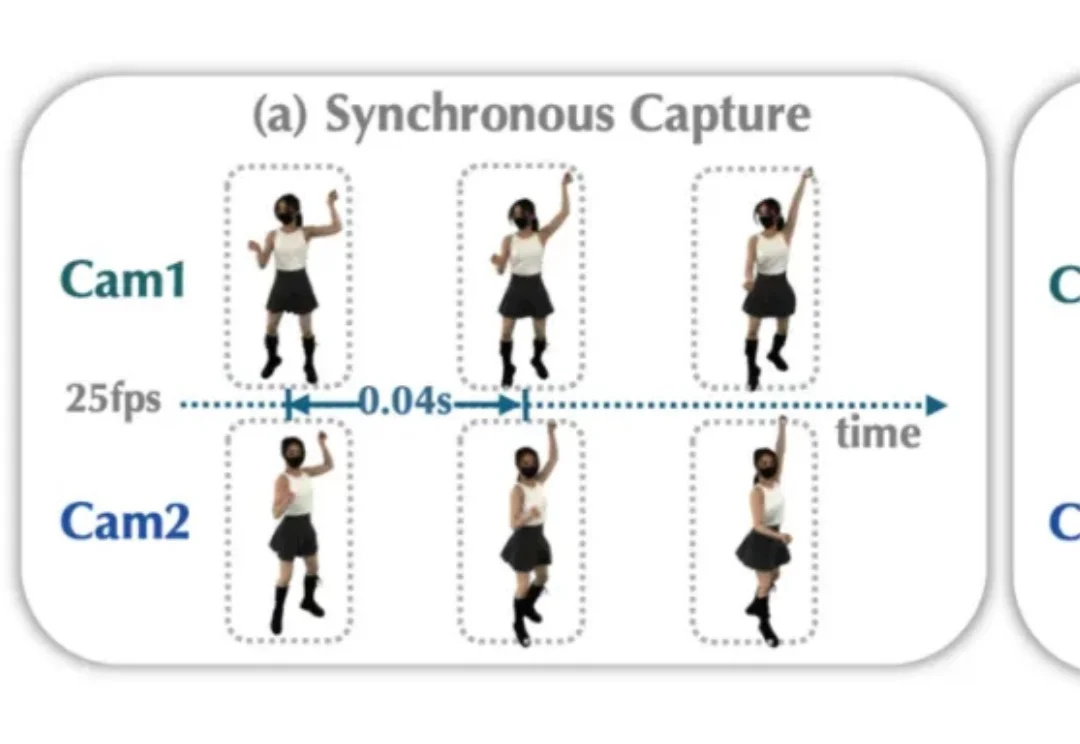
当古装剧中的长袍在武林高手凌空翻腾的瞬间扬起 0.01 秒的惊艳弧度,当 VR 玩家想伸手抓住对手 “空中定格” 的剑锋,当 TikTok 爆款视频里一滴牛奶皇冠般的溅落要被 360° 无死角重放 —— 如何用普通的摄像机,把瞬间即逝的高速世界 “冻结” 成可供反复拆解、传送与交互的数字化 4D 时空,成为 3D 视觉领域的一个难题。
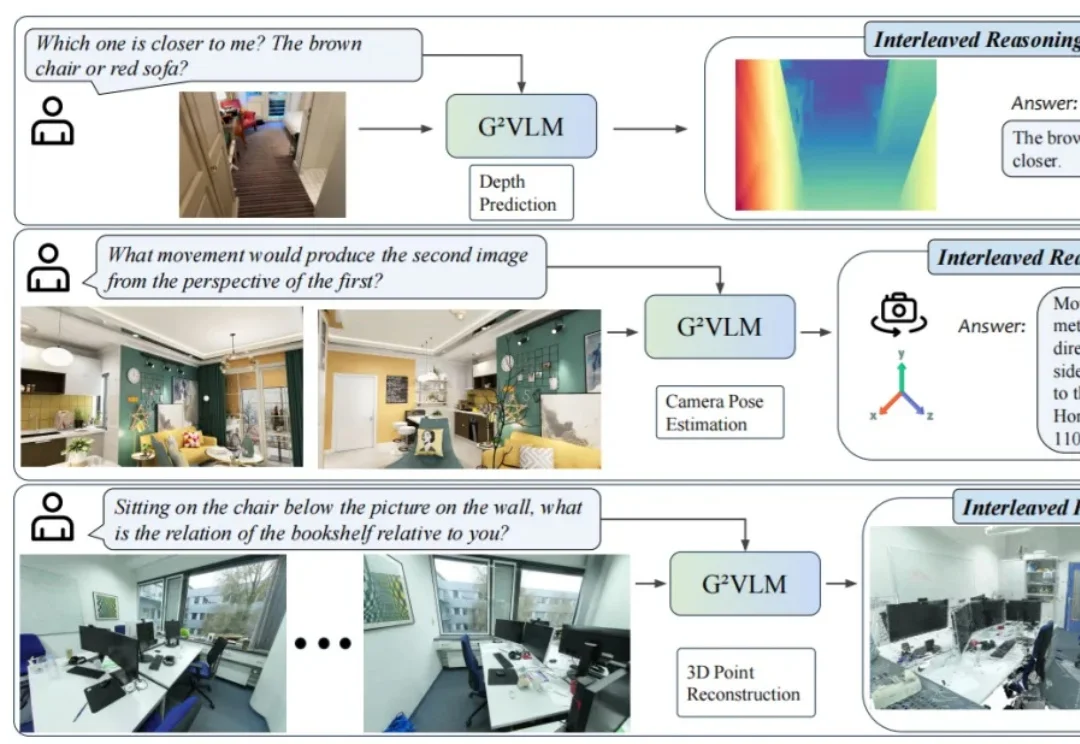
近日,24 岁的 00 后博士生胡文博和所在团队造出一款名为 G²VLM 的超级 AI 模型,它是一位拥有空间超能力的视觉语言小能手,不仅能从普通的平面图片中精准地重建出三维世界,还能像人类一样进行复杂的空间思考和空间推理。

「这是一项革命性的工作」、「不是……而是……」、「首先……其次……」;在一篇文章里读到这些词,你是不是本能地开始觉得,有点不对劲了。