
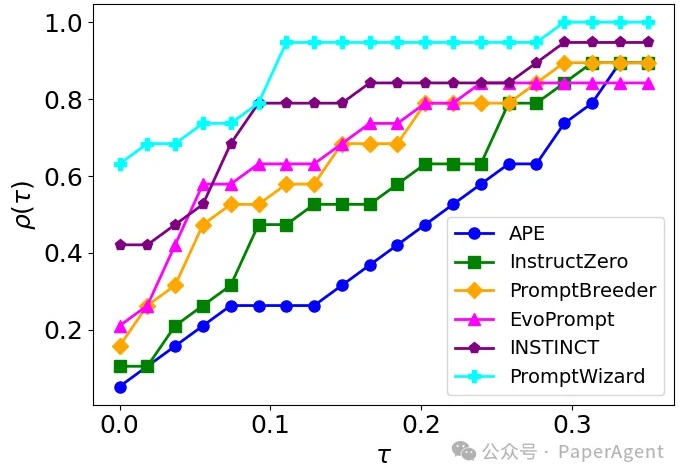
微软开源PromptWizard,摔碎了提示工程师的饭碗~
微软开源PromptWizard,摔碎了提示工程师的饭碗~PromptWizard (PW) 旨在自动化和简化提示优化。它将 LLM 的迭代反馈与高效的探索和改进技术相结合,在几分钟内创建高效的prompts。
来自主题: AI技术研报
8508 点击 2024-12-25 09:09
PromptWizard (PW) 旨在自动化和简化提示优化。它将 LLM 的迭代反馈与高效的探索和改进技术相结合,在几分钟内创建高效的prompts。
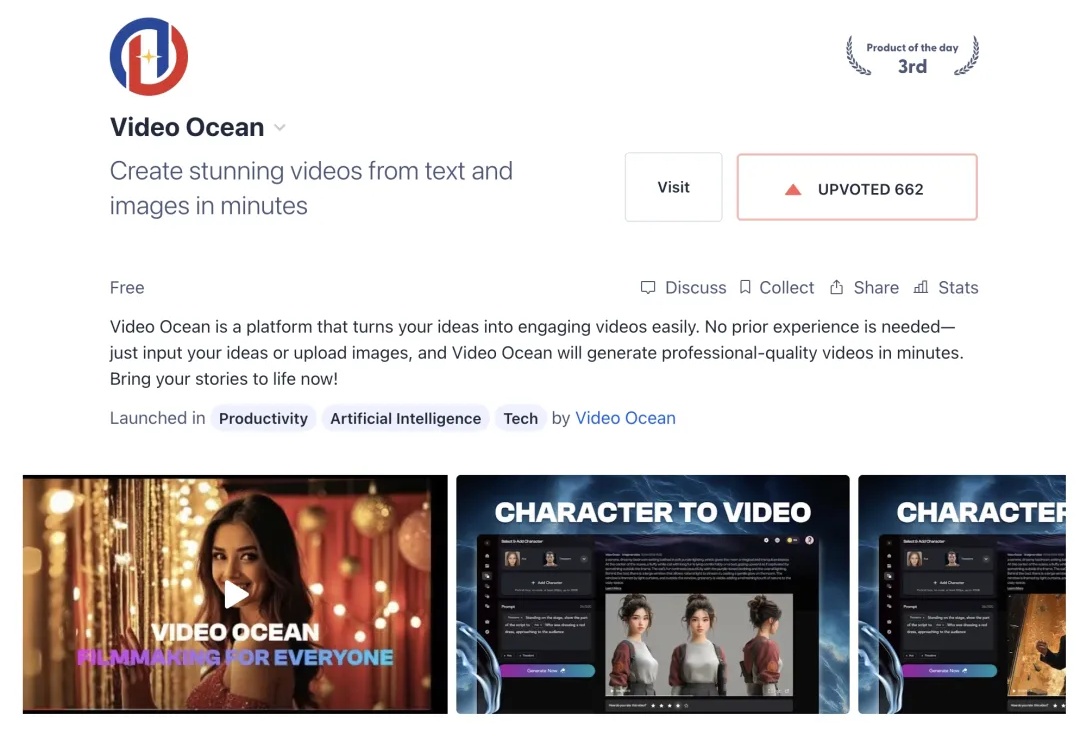
随着Sora震撼发布,视频生成技术成为了AI领域新风口。不过,高昂的开发成本是一大瓶颈。国产平台Video Ocean不仅成功登上全球热榜第三,还将视频生成模型开发成本降低50%。而且,模型构建和性能优化方案现已开源,还能免费获得500元GPU算力。

近日,Anthropic开发者关系主管发推表示:万事俱备,2025年将是智能体系统之年!在年终总结的博文中,Anthropic分享了一年来与客户合作构建智能体系统的最佳实践。
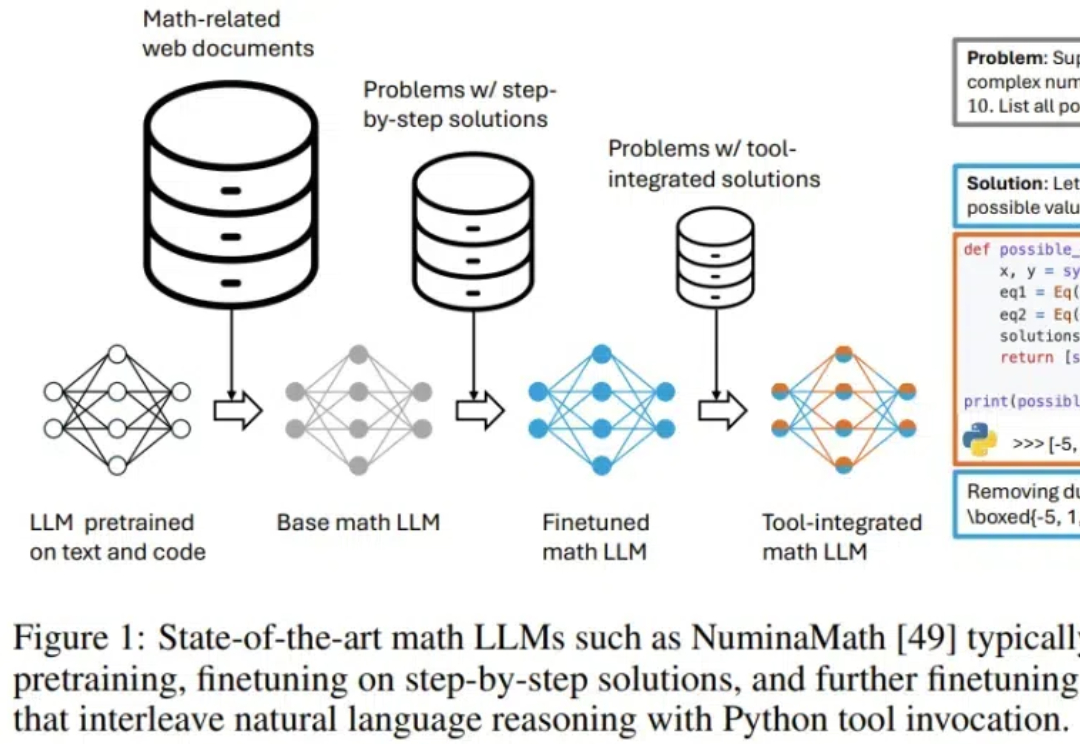
对 AI 研究者来说,数学既是一类难题,也是一个标杆,能够成为衡量 AI 技术的发展重要尺度。近段时间,随着 AI 推理能力的提升,使用 AI 来证明数学问题已经成为一个重要的研究探索方向。
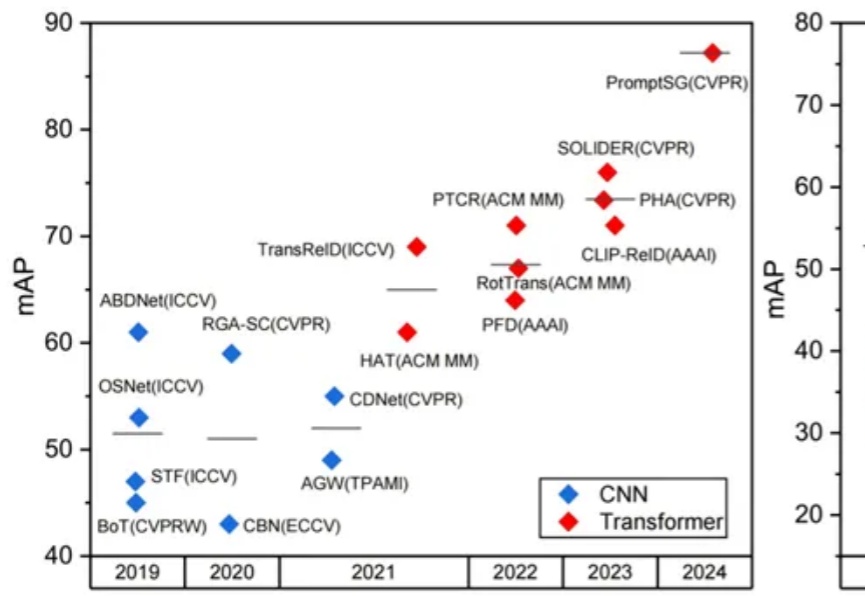
研究人员对基于Transformer的Re-ID研究进行了全面回顾和深入分析,将现有工作分类为图像/视频Re-ID、数据/标注受限的Re-ID、跨模态Re-ID以及特殊Re-ID场景,提出了Transformer基线UntransReID,设计动物Re-ID的标准化基准测试,为未来Re-ID研究提供新手册。

上周发出《AI时代写Prompt应该用APPL:为Prompt工程打造的编程语言,来自清华姚班的博士》之后,文章中实现了一个Google DeepMind的OPRO简单版本的优化方法,这让很多读者非常着迷。
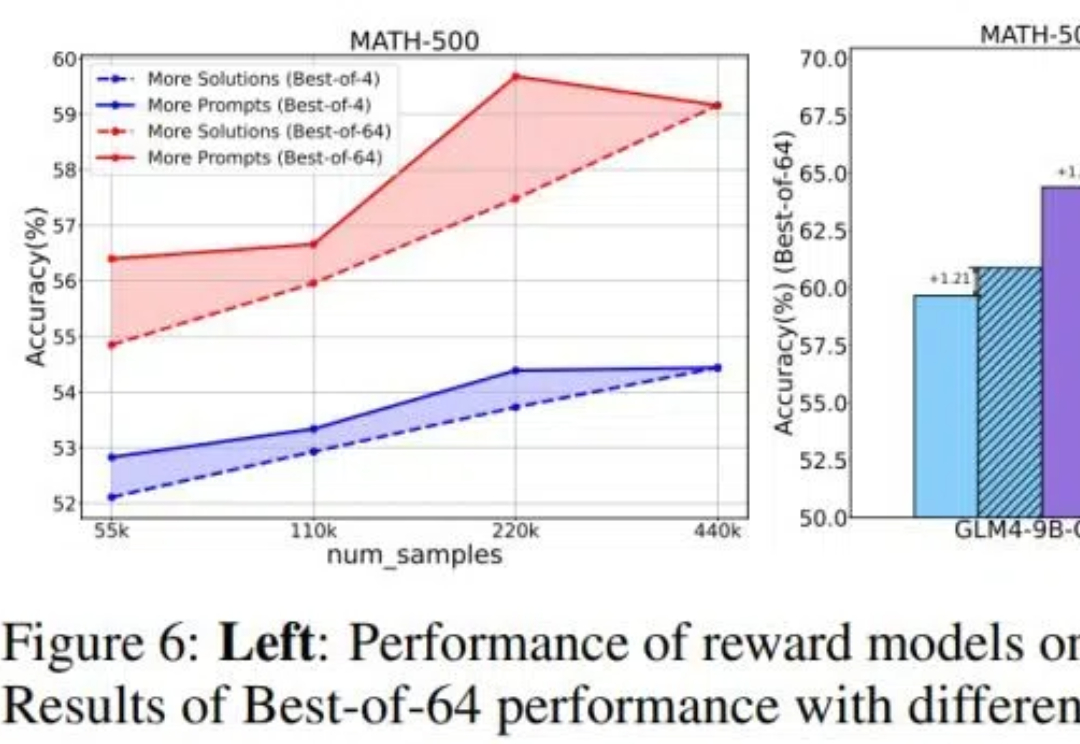
目前关于 RLHF 的 scaling(扩展)潜力研究仍然相对缺乏,尤其是在模型大小、数据组成和推理预算等关键因素上的影响尚未被系统性探索。 针对这一问题,来自清华大学与智谱的研究团队对 RLHF 在 LLM 中的 scaling 性能进行了全面研究,并提出了优化策略。
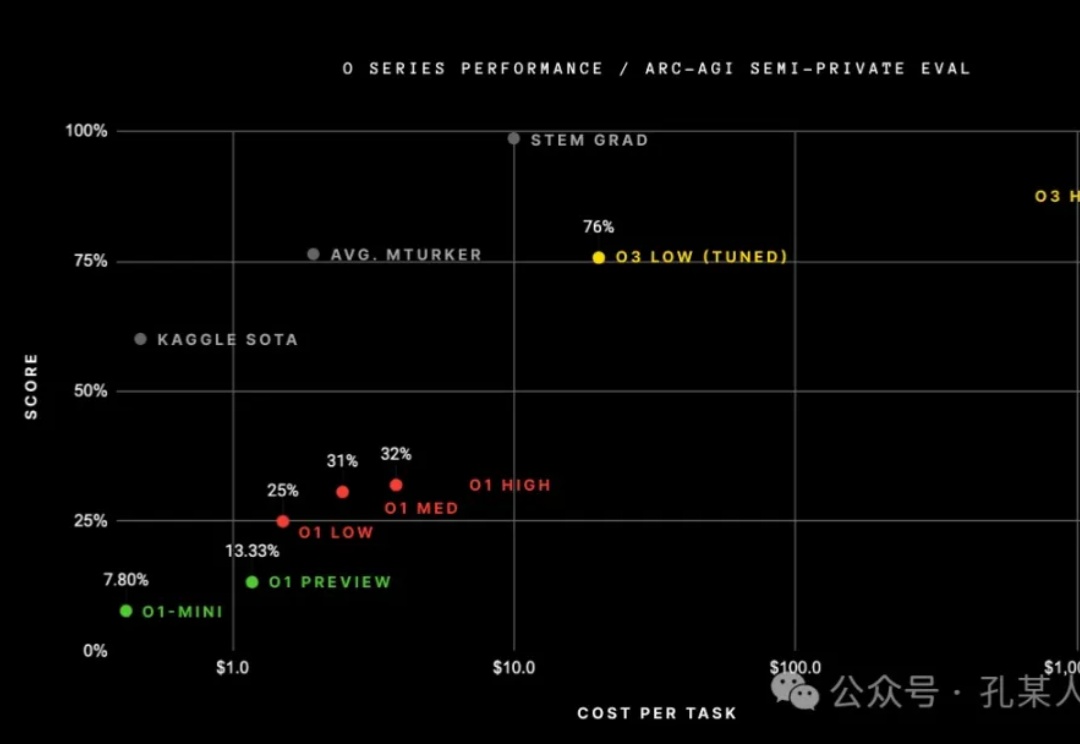
目前o3放出的信息还不多,但还是有一些内容可以做技术分析的。以及o3的重要性值得做一个专篇讨论。

在大语言模型(LLM)的发展历程中,思维链(Chain of Thought,CoT)推理无疑是一个重要的里程碑。
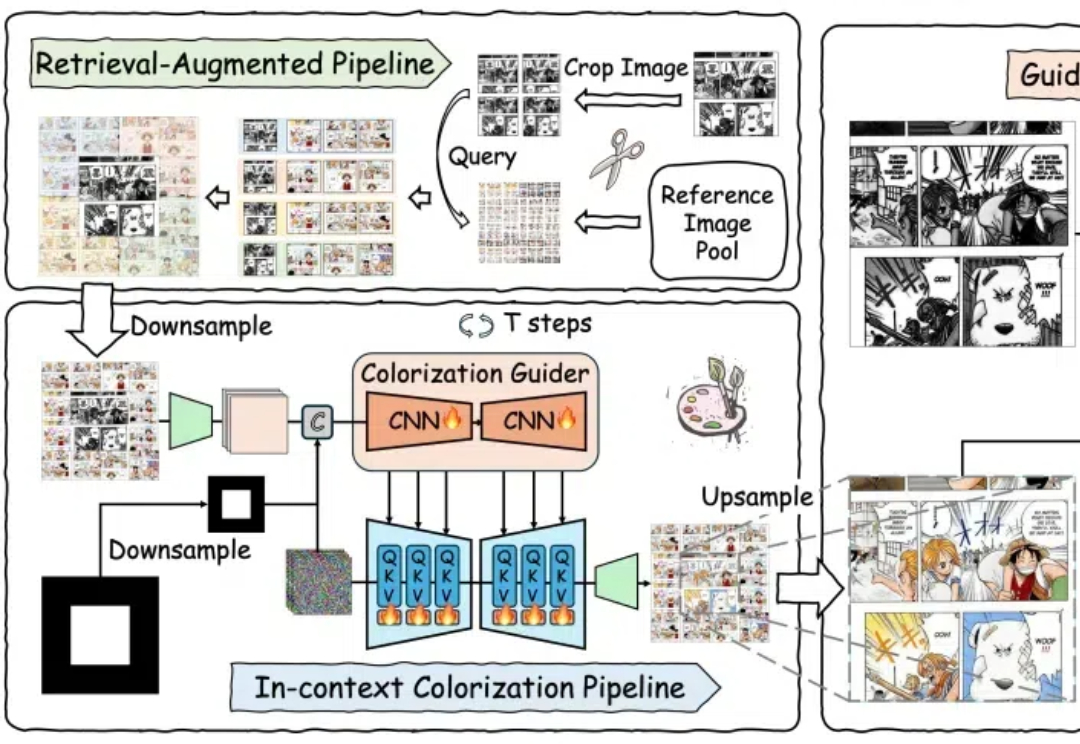
扩散模型在可控图像生成方面取得了空前进展,包括图像修补 ,图像着色和图像编辑。基于扩散模型的生成方案可以显著降低劳动力成本,尤其是在基于参考图像序列着色任务上,它可用于漫画创作,动画制作和黑白电影着色。

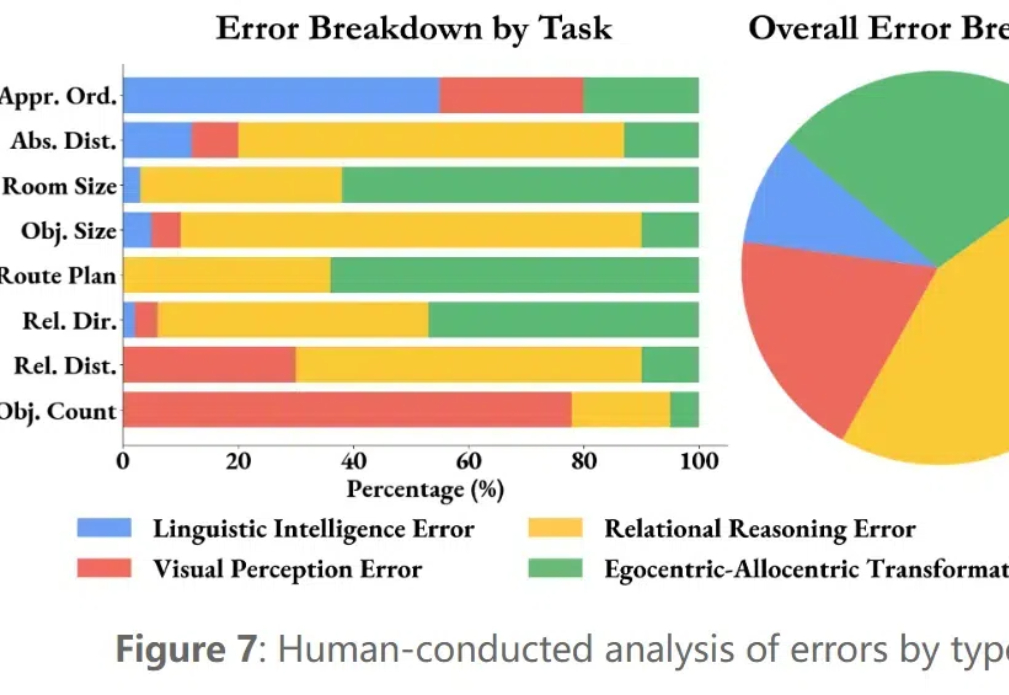
李飞飞、谢赛宁团队又有重磅发现了:多模态LLM能够记住和回忆空间,甚至内部已经形成了局部世界模型,表现了空间意识!李飞飞兴奋表示,在2025年,空间智能的界限很可能会再次突破。
o1-preview在医疗诊断中远超人类,赛博看病指日可待?

研究团队在最新时间序列预测基准评测TFB的25个数据集上进行了广泛验证,证明了DUET的卓越性能,为各行业的时间序列预测任务提供了全新的解决方案。

近期,知名研究机构 Appier AI Research 和国立台湾大学,联合发表了一篇论文

图数据学习在过去几年中取得了显著的进展,图神经网络(GNN)在此过程中起到了核心作用。然而,不同的 GNN 方法在概念和实现上的差异,对理解和应用图学习算法构成了挑战。
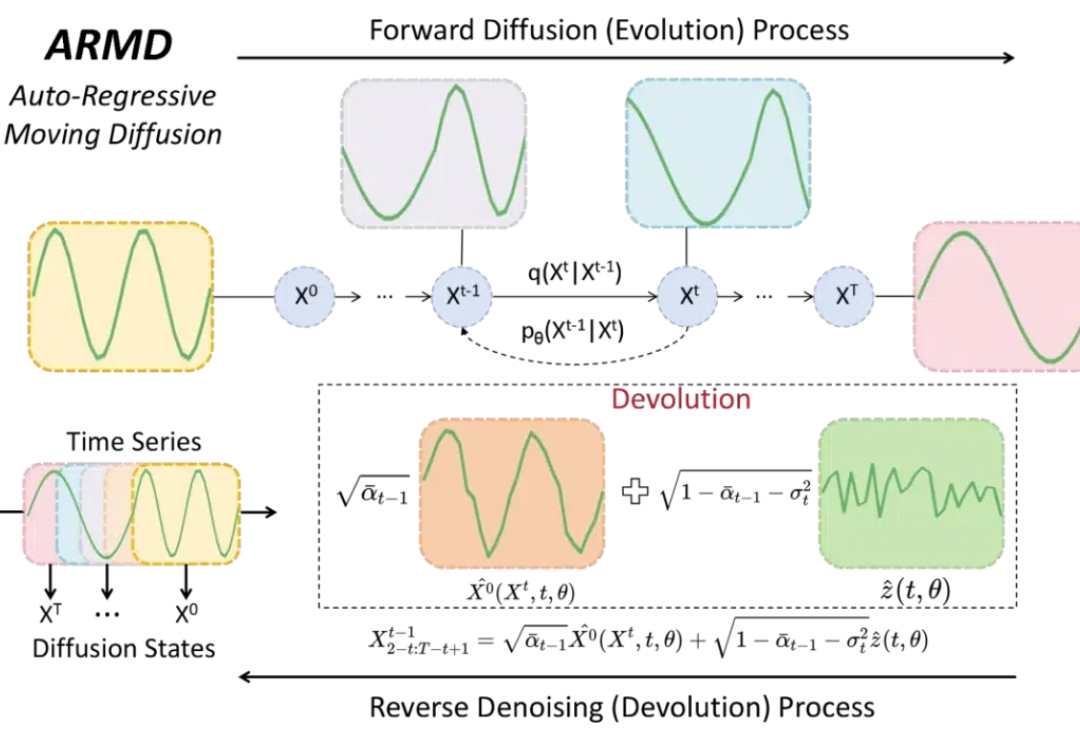
在时间序列预测领域,当前主流的扩散方法还是传统的基于噪声的方法,未能充分利用自回归技术实现时间序列建模。
我们生活在一个感官丰富的 3D 世界中,视觉信号围绕着我们,让我们能够感知、理解和与之互动。

o1/o3带火的推理计算Scaling,原来谷歌早在今年8月就曾探讨过。
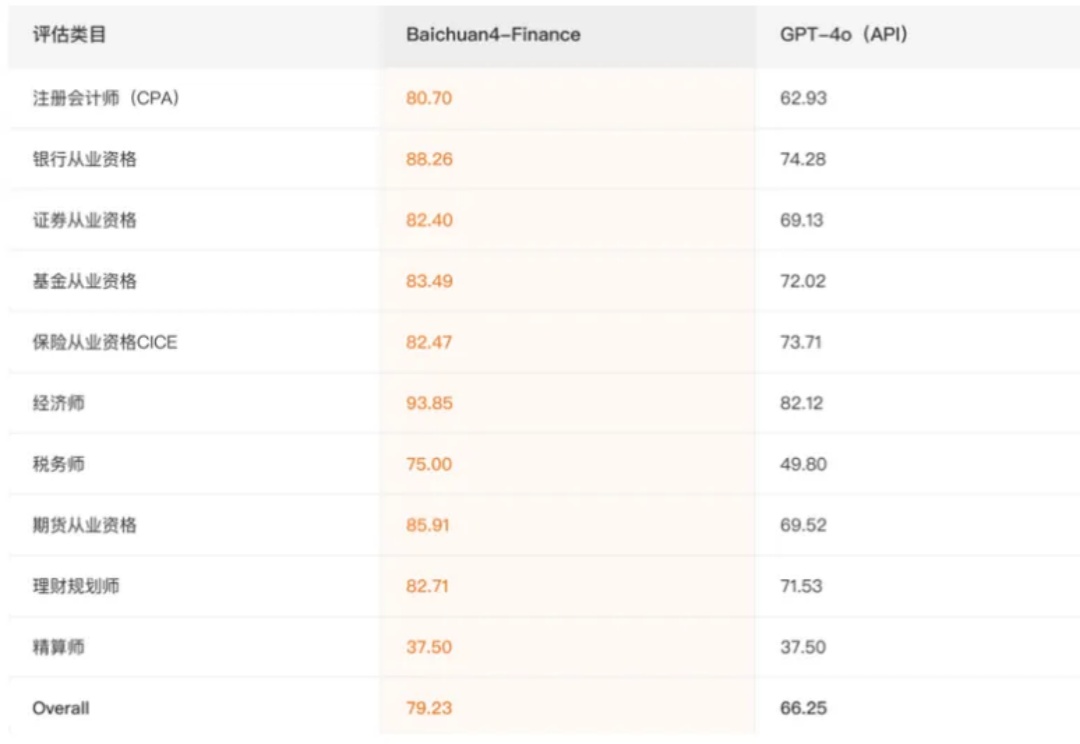
大模型的竞速赛,正站在通用底座的基础上,掀起“领域增强”风暴。
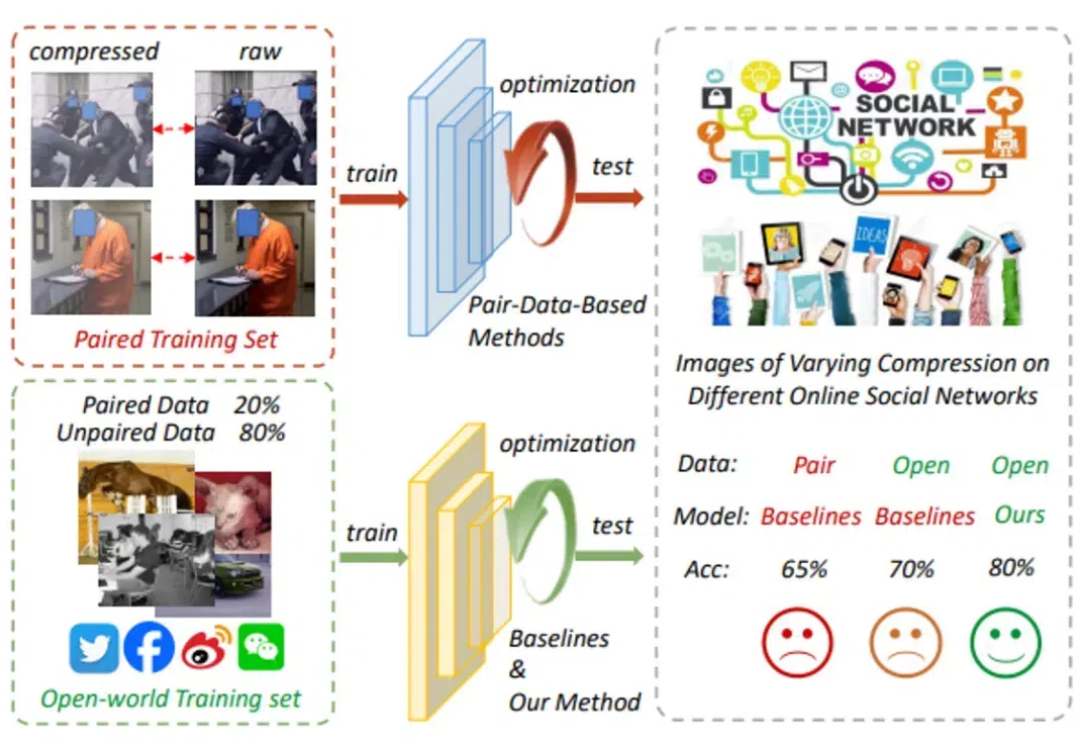
现有的深伪检测方法大多依赖于配对数据,即一张压缩图像和其对应的原始图像来训练模型,这在许多实际的开放环境中并不适用。尤其是在社交媒体等开放网络环境(OSN)中,图像通常经过多种压缩处理,导致图像质量受到影响,深伪识别也因此变得异常困难。
近期,OpenAI 号称最强推理模型的推出,引发了社区的热议,无论是性能还是价格,都产生了不少话题。最近,我们对 o1 新发布的 o1 满血版、o1 pro mode 模型进行了高难度数学测试,旨在深入探究其在数学推理方面的能力表现。
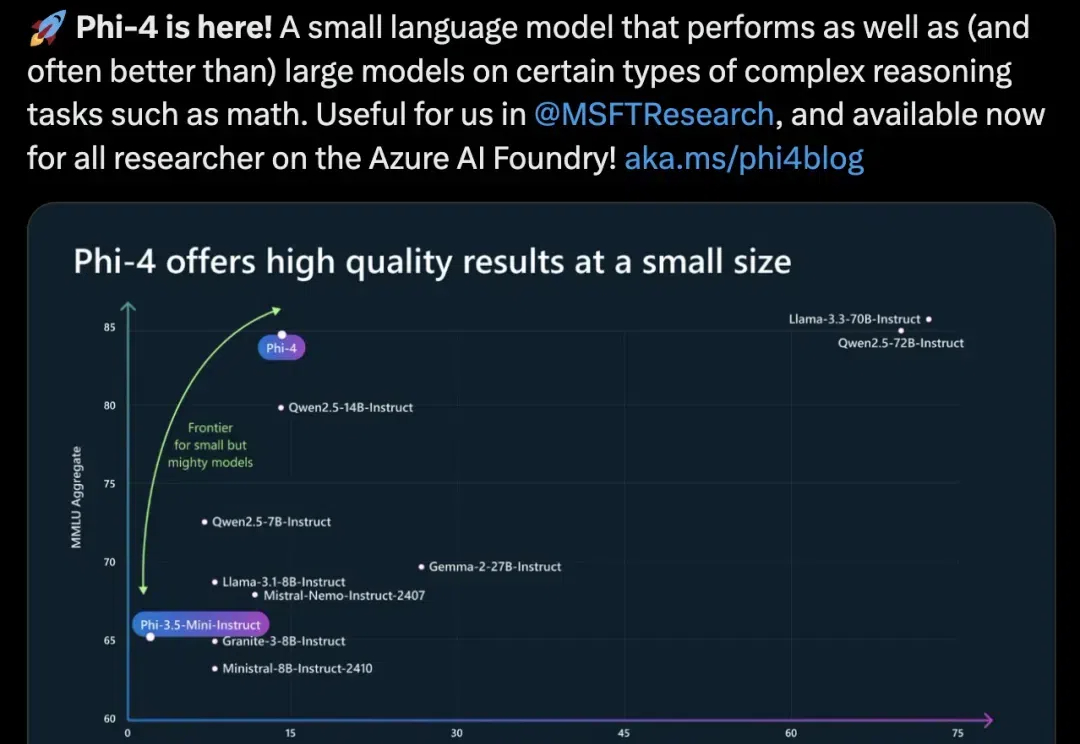
微软下一代14B小模型Phi-4出世了!仅用了40%合成数据,在数学性能上击败了GPT-4o,最新36页技术报告出炉。
最近AI业界的观点开始产生变化,Jason Wei明确指出AI for Science蕴藏着巨大的机遇,而其中最大的场景在于AlphaFold 2掀起的蛋白质革命。

北京大学等研究团队优化了Sdcpp框架,通过引入Winograd算法和多项策略,显著提升了图像生成速度和内存效率,最高可提速4.79倍。

OpenAI o1的数学推理能力是否真的那么强?近日,来自港大的研究人员对模型进行了严格的AB测试,在非公开的国家队奥数题面前,o1证明了自己的实力。
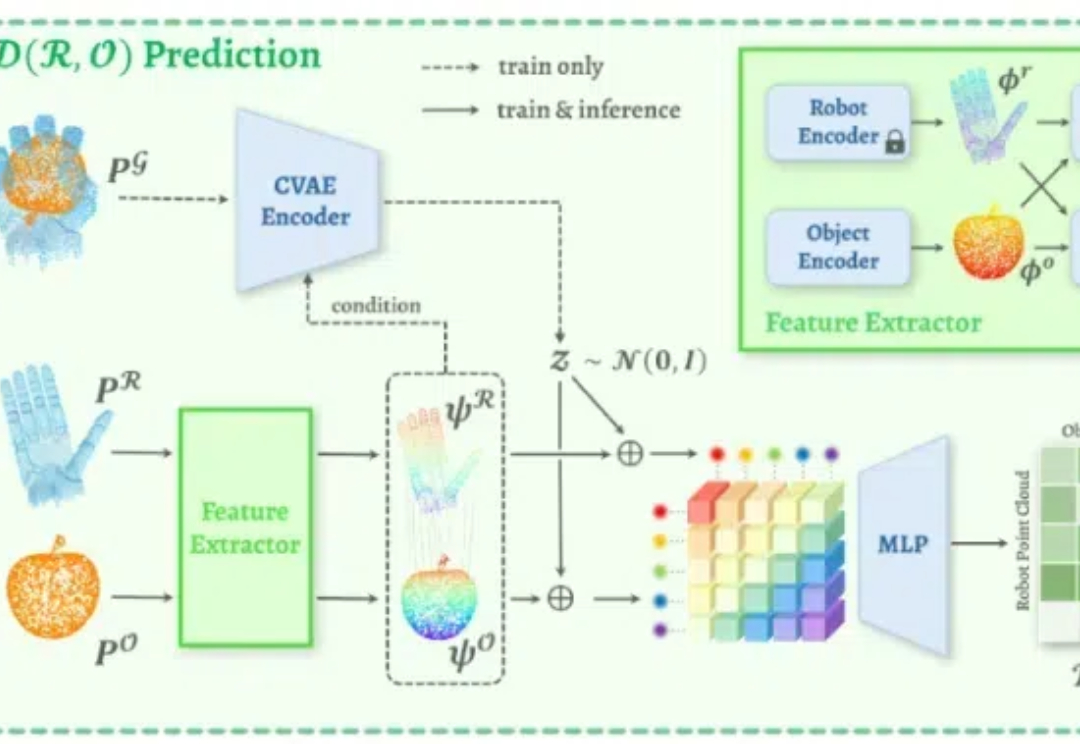
近期,新加坡国立大学计算机学院的邵林团队提出了 D(R,O) Grasp:一种面向跨智能体灵巧抓取的机器人与物体交互统一表示。该方法通过创新性地建模机器人手与物体在抓取姿态下的交互关系,成功实现了对多种机器人手型与物体几何形状的高度泛化能力,为灵巧抓取技术的未来开辟了全新的方向。
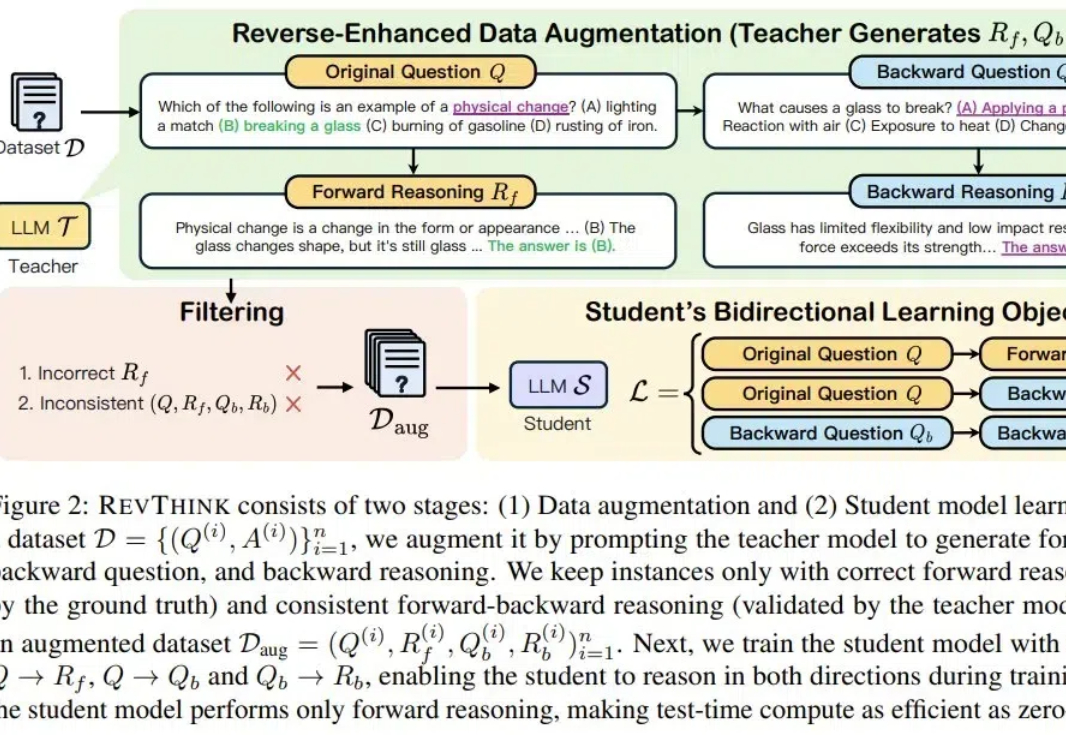
人能逆向思维,LLM 也可以吗?北卡罗来纳大学教堂山分校与谷歌最近的一项研究表明,LLM 确实可以,并且逆向思维还能帮助提升 LLM 的正向推理能力!
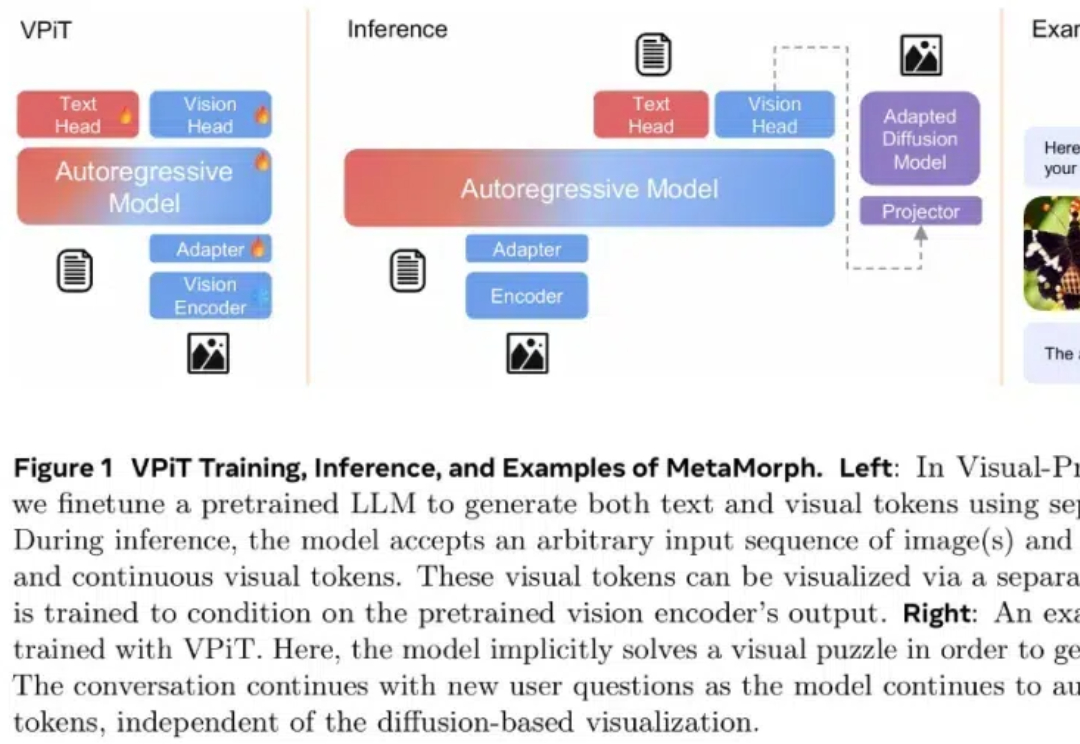
如今,多模态大模型(MLLM)已经在视觉理解领域取得了长足进步,其中视觉指令调整方法已被广泛应用。该方法是具有数据和计算效率方面的优势,其有效性表明大语言模型(LLM)拥有了大量固有的视觉知识,使得它们能够在指令调整过程中有效地学习和发展视觉理解。

大语言模型(LLM)在自然语言处理领域取得了令人瞩目的成就,但在需要多步推理的复杂任务中仍面临严峻挑战。
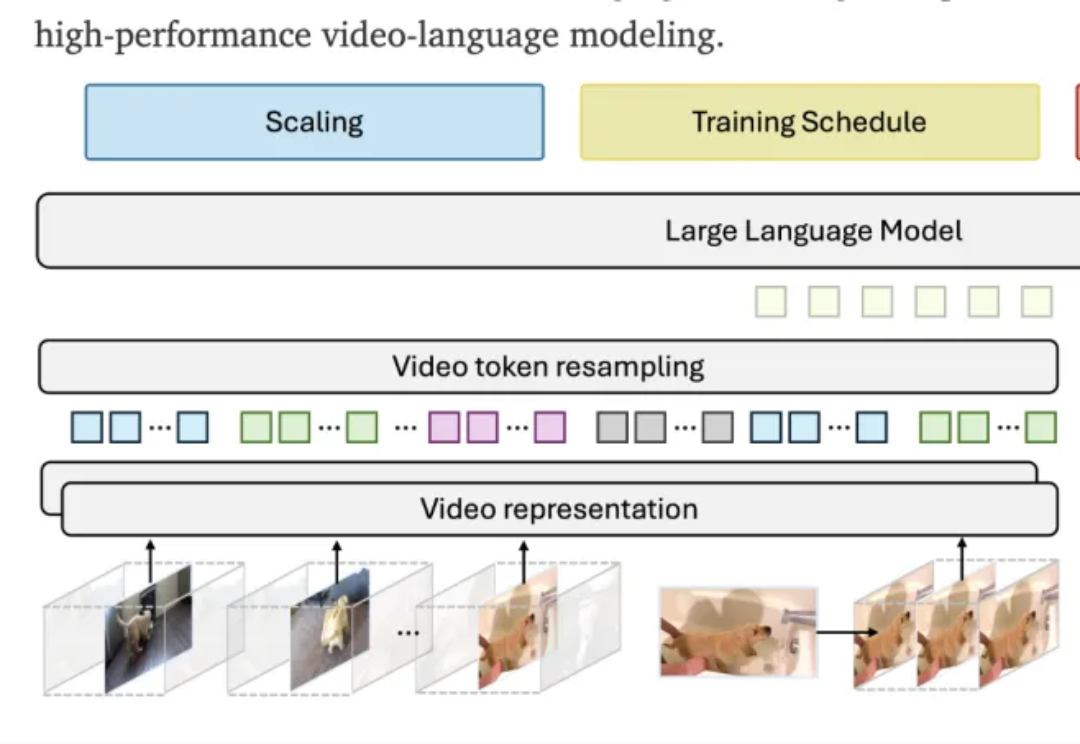
Meta斯坦福大学联合团队全面研究多模态大模型(LMM)中驱动视频理解的机制,扩展了视频多模态大模型的设计空间,提出新的训练调度和数据混合方法,并通过语言先验或单帧输入解决了已有的评价基准中的低效问题。