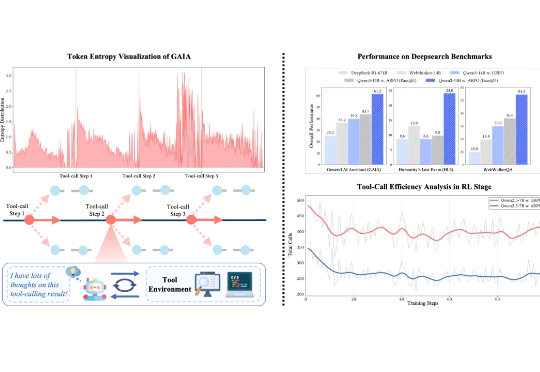
ARPO:智能体强化策略优化,让Agent在关键时刻多探索一步
ARPO:智能体强化策略优化,让Agent在关键时刻多探索一步在可验证强化学习(RLVR)的推动下,大语言模型在单轮推理任务中已展现出不俗表现。然而在真实推理场景中,LLM 往往需要结合外部工具进行多轮交互,现有 RL 算法在平衡模型的长程推理与多轮工具交互能力方面仍存在不足。
来自主题: AI技术研报
7852 点击 2025-08-10 13:29
 搜索
搜索
在可验证强化学习(RLVR)的推动下,大语言模型在单轮推理任务中已展现出不俗表现。然而在真实推理场景中,LLM 往往需要结合外部工具进行多轮交互,现有 RL 算法在平衡模型的长程推理与多轮工具交互能力方面仍存在不足。
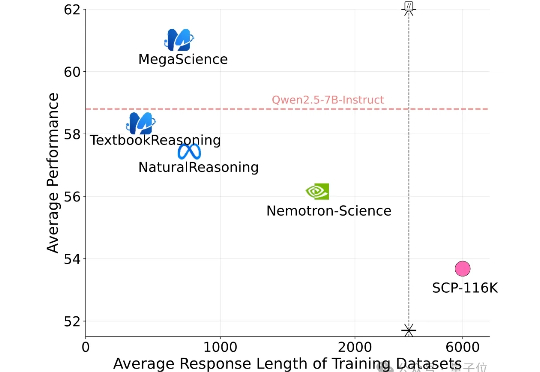
有史规模最大的开源科学推理后训练数据集来了! 上海创智学院、上海交通大学(GAIR Lab)发布MegaScience。该数据集包含约125万条问答对及其参考答案,广泛覆盖生物学、化学、计算机科学、经济学、数学、医学、物理学等多个学科领域,旨在为通用人工智能系统的科学推理能力训练与评估提供坚实的数据。
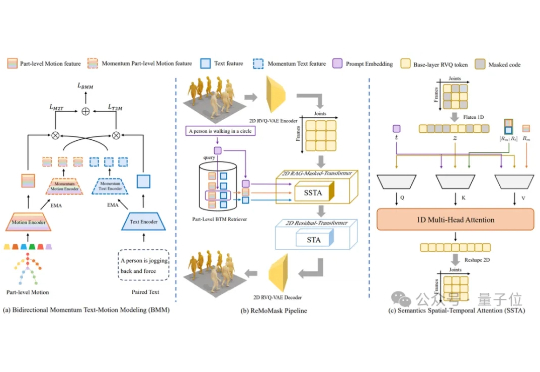
北京大学提出了ReMoMask:一种全新的基于检索增强生成的Text-to-Motion框架。它是一个集成三项关键创新的统一框架:(1)基于动量的双向文本-动作模型,通过动量队列将负样本的尺度与批次大小解耦,显著提高了跨模态检索精度;(2)语义时空注意力机制,在部件级融合过程中强制执行生物力学约束,消除异步伪影;(3)RAG-无分类器引导结合轻微的无条件生成以增强泛化能力。
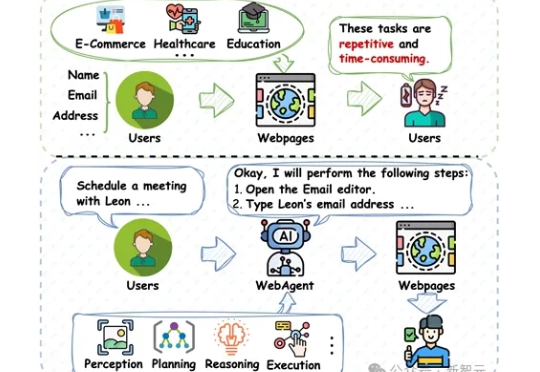
互联网技术的发展极大地便利了我们的生活,但许多网络任务重复繁琐,降低了效率。为了解决这一问题,研究人员正在开发基于大型基础模型(LFMs)的智能体——WebAgents,通过感知环境、规划推理和执行交互来完成用户指令,显著提升便利性。香港理工大学的研究人员从架构、训练和可信性等角度,总结了WebAgents的代表性方法,全面梳理了相关研究进展。
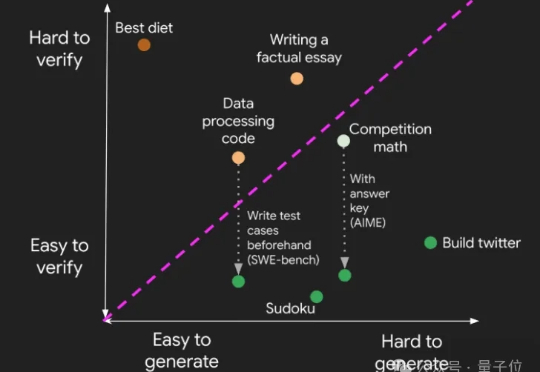
当大模型把人类曾经的终极考题变成日常练习,AI的奔跑却悄悄瘸了腿—— 训练能力突飞猛进,验证答案的本事却成了拖后腿的短板。 为此,上海AI Lab和澳门大学联合发布通用答案验证模型CompassVerifier与评测集VerifierBench。填补了Verifier领域没有建立验证->提升->验证的循环迭代体系的空白。
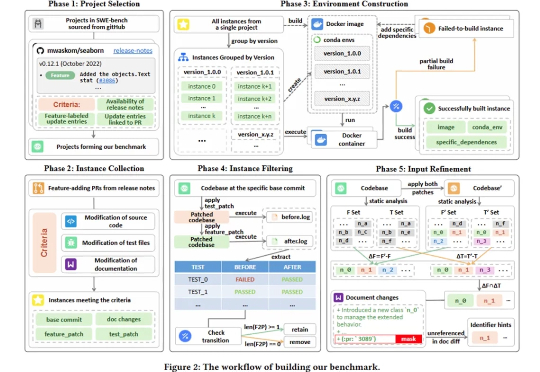
当前,大型语言模型(LLM)在软件工程领域的应用日新月异,尤其是在自动修复 Bug 方面,以 SWE-bench 为代表的基准测试展示了 AI 惊人的潜力。然而,软件开发远不止于修 Bug,功能开发与迭代才是日常工作的重头戏。
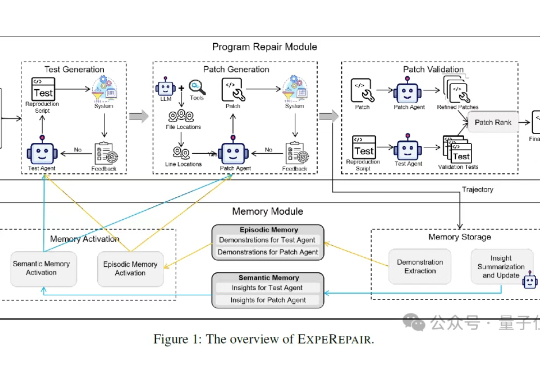
AI学会像人一样修Bug了!“这个Bug我上周刚修过”“这个报错怎么又来了”“新人怎么又在同一个地方踩坑”……
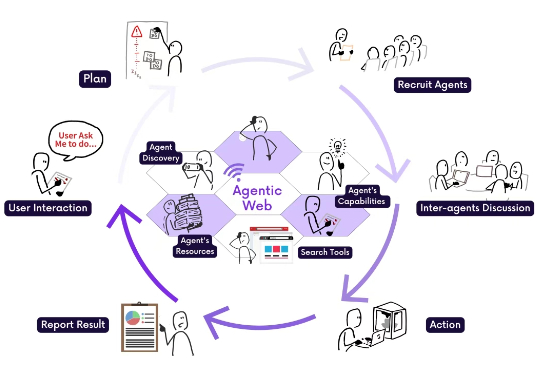
过去三十年,互联网经历了从静态网页到智能推荐的深刻演变。如今,我们正站在互联网的另一个重大转折点上。 这一转折,来自一种全新的范式设想 —— Agentic Web,一个由 AI 智能体组成的、目标导向型的互联网系统。在这个新框架中,用户不再手动浏览网页、点击按钮,而是通过自然语言向智能体发出一个目标,AI 会自主规划、搜索、调用服务、协调其他智能体,最终完成复杂任务。
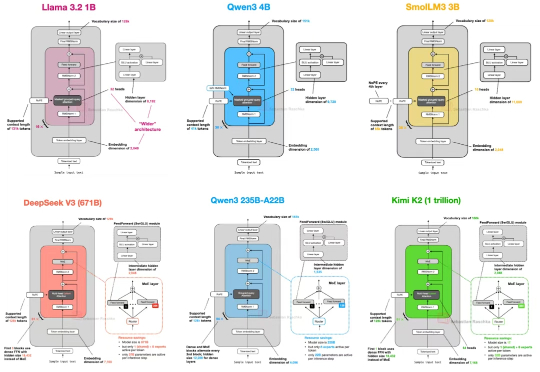
自首次提出 GPT 架构以来,转眼已经过去了七年。 如果从 2019 年的 GPT-2 出发,回顾至 2024–2025 年的 DeepSeek-V3 和 LLaMA 4,不难发现一个有趣的现象:尽管模型能力不断提升,但其整体架构在这七年中保持了高度一致。

心理健康问题影响着全球数亿人的生活,然而患者往往面临着双重负担:不仅要承受疾病本身的痛苦,还要忍受来自社会的偏见和歧视。世界卫生组织数据显示,全球有相当比例的心理健康患者因为恐惧社会歧视而延迟或拒绝治疗。
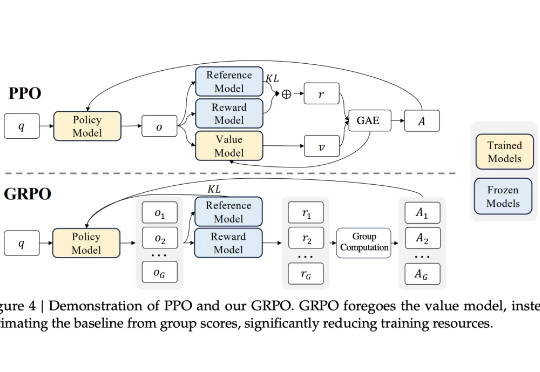
众所周知,大型语言模型的训练通常分为两个阶段。第一阶段是「预训练」,开发者利用大规模文本数据集训练模型,让它学会预测句子中的下一个词。第二阶段是「后训练」,旨在教会模型如何更好地理解和执行人类指令。
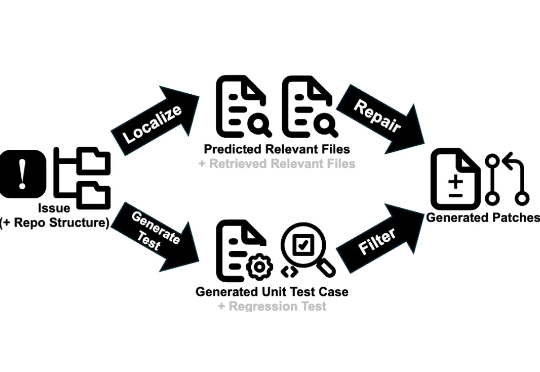
近日,一项由北京大学、字节跳动 Seed 团队及香港大学联合进行的研究,提出了一种名为「SWE-Swiss」的完整「配方」,旨在高效训练用于解决软件工程问题的 AI 模型。研究团队推出的 32B 参数模型 SWE-Swiss-32B,在权威基准 SWE-bench Verified 上取得了 60.2% 的准确率,在同尺寸级别中达到了新的 SOTA。
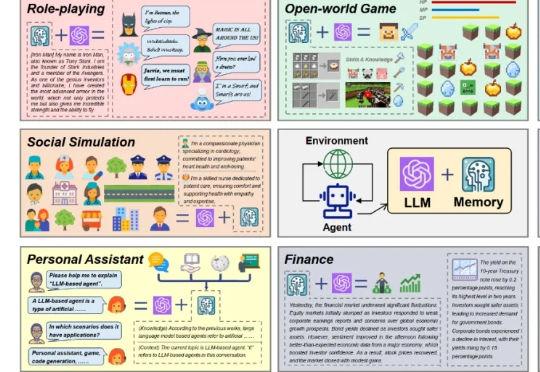
近期,基于大语言模型的智能体(LLM-based agent)在学术界和工业界中引起了广泛关注。对于智能体而言,记忆(Memory)是其中的重要能力,承担了记录过往信息和外部知识的功能,对于提高智能体的个性化等能力至关重要。

大部分现有的文档检索基准(如MTEB)只考虑了纯文本。而一旦文档的关键信息蕴含在图表、截图、扫描件和手写标记中,这些基准就无能为力。为了更好的开发下一代向量模型和重排器,我们首先需要一个能评测模型在视觉复杂文档能力的基准集。
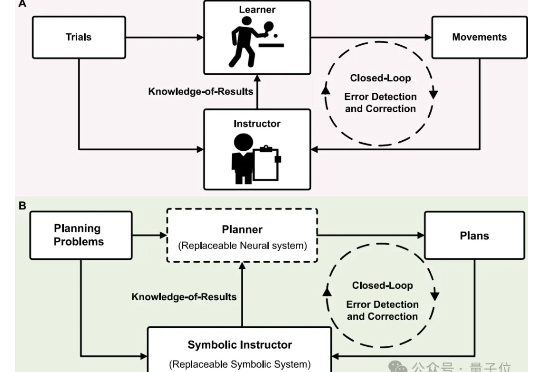
科研er看过来!还在反复尝试材料组合方案,耗时又耗力? 新型“神经-符号”融合规划器直接帮你一键锁定高效又精准的科研智能规划。
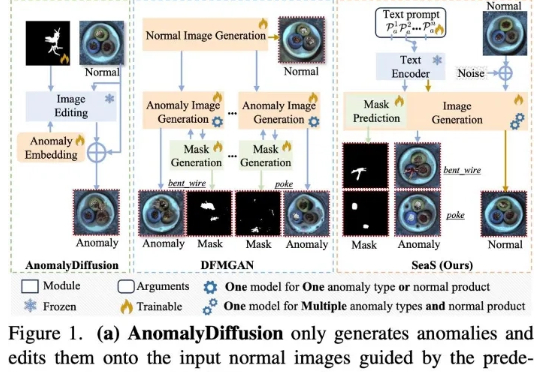
当前先进制造领域的产线良率往往超过 98%,因此异常样本(也称为缺陷样本)的搜集和标注已成为⼯业质检的核⼼瓶颈,过少的异常样本显著限制了模型的检测能⼒,利⽤⽣成模型扩充异常样本集合正逐渐成为产业界的主流选择,但现有⽅法存在明显局限
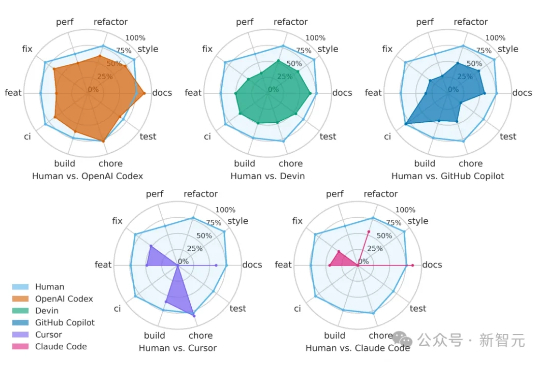
「软件正在吞噬世界,但AI将吞噬软件。」—英伟达CEO黄仁勋的预言正加速照进现实。
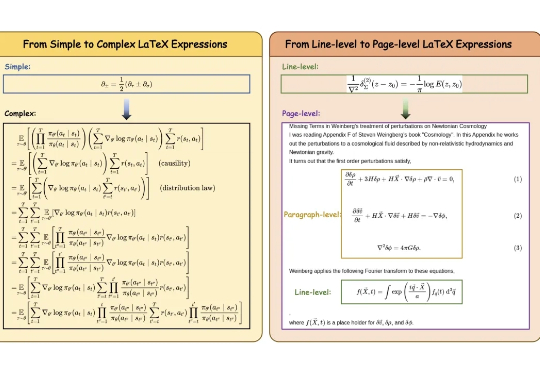
LaTeX 公式的光学字符识别(OCR)是科学文献数字化与智能处理的基础环节,尽管该领域取得了一定进展,现有方法在真实科学文献处理时仍面临诸多挑战:
近年来,大语言模型(LLM)在语言理解、生成和泛化方面取得了突破性进展,并广泛应用于各种文本任务。随着研究的深入,人们开始关注将 LLM 的能力扩展至非文本模态,例如图像、音频、视频、图结构、推荐系统等。
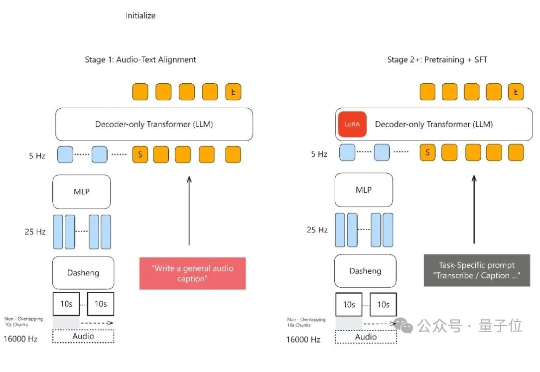
声音理解能力新SOTA,小米全量开源了模型。 MiDashengLM-7B,基于Xiaomi Dasheng作为音频编码器和Qwen2.5-Omni-7B Thinker作为自回归解码器,通过创新的通用音频描述训练策略,实现了对语音、环境声音和音乐的统一理解。
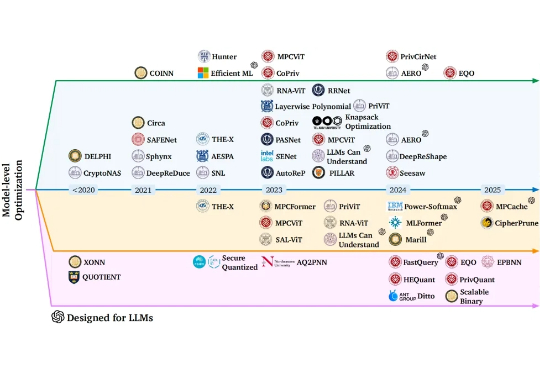
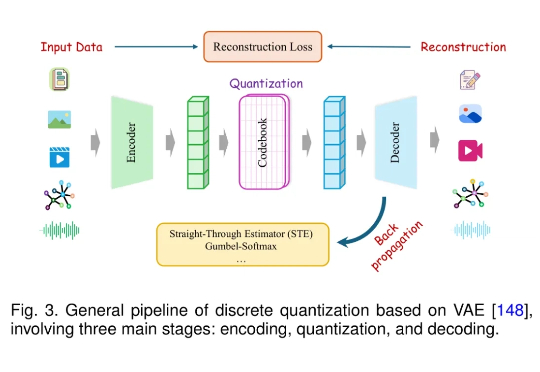
在数据隐私日益重要的 AI 时代,如何在保护用户数据的同时高效运行机器学习模型,成为了学术界和工业界共同关注的难题。

通义模型家族,刚刚又双叒开源了,这次是Qwen-Image——一个200亿参数、采用MMDiT架构的图像生成模型。 这也是通义千问系列中首个图像生成基础模型。

世界是动态变化的。为了理解这个动态变化的世界并在其中运行,AI 模型必须具备在线学习能力。为此,该领域提出了一种新的性能指标 —— 适应性遗憾值(adaptive regret),其定义为任意区间内的最大静态遗憾值。
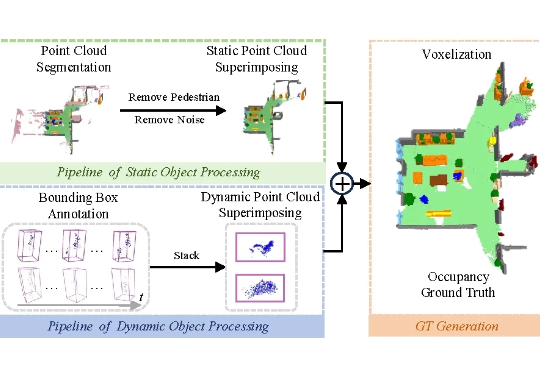
凭借类人化的结构设计与运动模式,人形机器人被公认为最具潜力融入人类环境的通用型机器人。其核心任务涵盖操作 (manipulation)、移动 (locomotion) 与导航 (navigation) 三大领域,而这些任务的高效完成,均以机器人对自身所处环境的全面精准理解为前提。
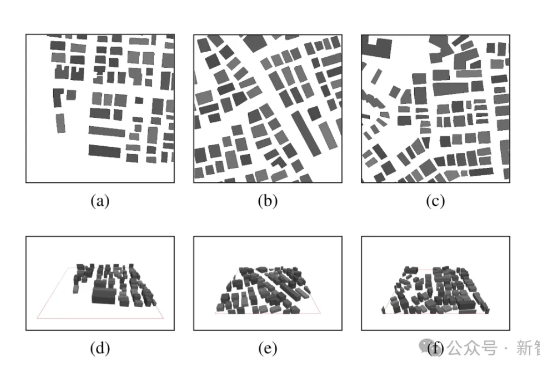
当前环境感知通信正逐步成为第六代移动通信系统(6G)的核心使能技术之一。为支撑其在复杂三维环境下的部署需求,西安电子科技大学、香港中文大学(深圳)和加拿大滑铁卢大学的研究团队联合提出了一个面向6G的高分辨率多模态三维无线电图谱数据集UrbanRadio3D,并构建了基于扩散模型的三维无线电图生成框架RadioDiff-3D。
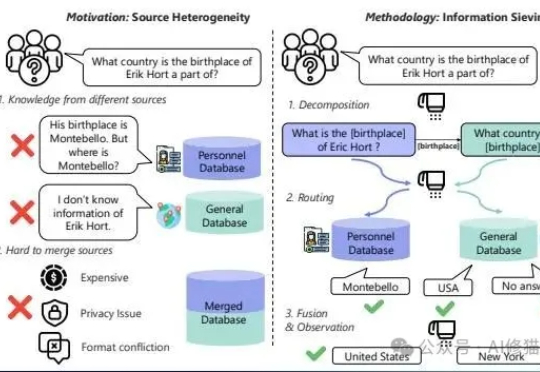
现在的RAG(检索增强生成)系统。您给它一个简单直接的问题,它能答得头头是道
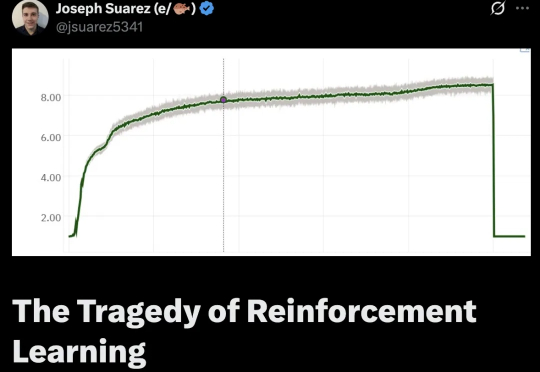
AlphaStar等证明强化学习在游戏等复杂任务上,表现出色,远超职业选手!那强化学习怎么突然就不行了呢?强化学习到底是怎么走上歧路的?
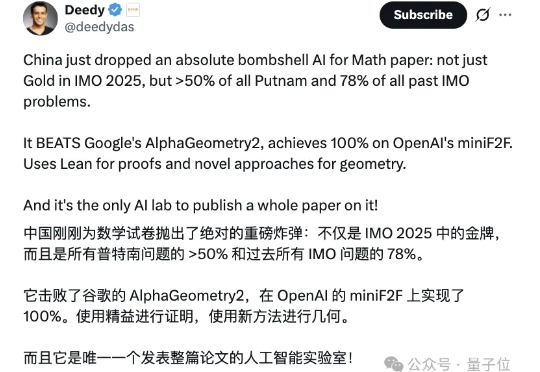
不仅能达IMO银牌水准,更能解决普特南数学竞赛难题,甚至超越顶尖模型o4-mini! 字节发布全新复杂数学解决模型——Seed-Prover。

在人工智能快速发展的今天,我们已逐渐习惯于让 AI 识别图像、理解语言,甚至与之对话。但当我们进入真实三维世界,如何让 AI 具备「看懂场景」、「理解空间」和「推理复杂任务」的能力?这正是 3D 视觉语言模型(3D VLM)所要解决的问题。

大家好,我是歸藏(guizang),今天给大家带来昨天探索的 AI 许愿祈福壁纸教程。昨天做了几张 AI 玄学的那种祈福壁纸,除了常见的文字花纹还加上了对应的神仙和一些现代化的处理。