可靠的Agent该用哪个模型,LLM多轮对话中的「迷失」现象 |微软最新
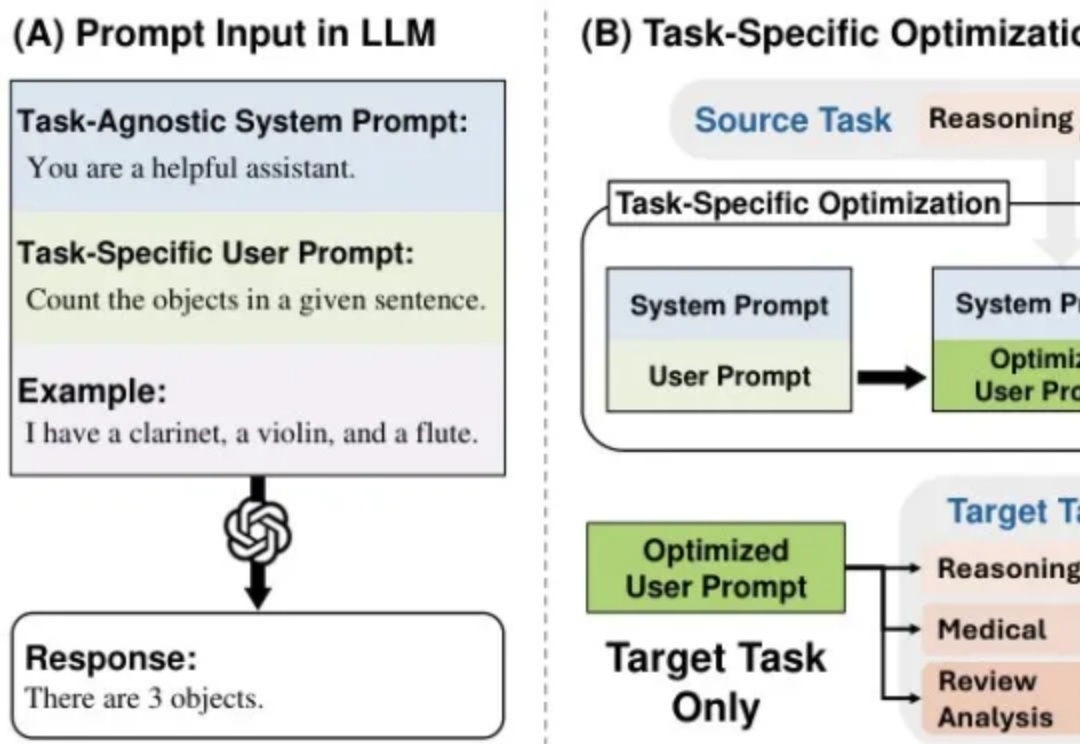
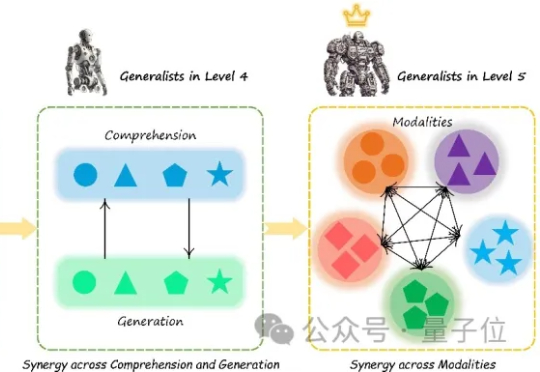
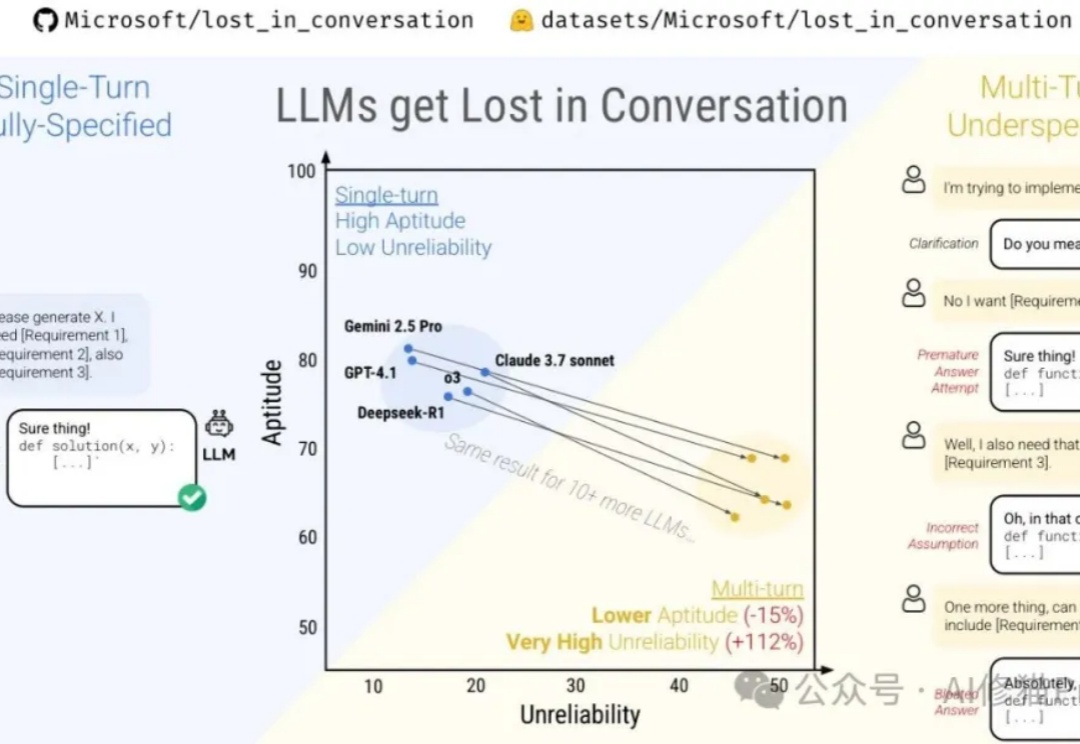
可靠的Agent该用哪个模型,LLM多轮对话中的「迷失」现象 |微软最新微软最近与Salesforce Research联合发布了一篇名为《Lost in Conversation》的研究,说当前最先进的LLM在多轮对话中表现会大幅下降,平均降幅高达39%。这一现象被称为对话中的"迷失"。文章分析了各大模型(包括Claude 3.7-Sonnet、Deepseek-R1等)在多轮对话中的表现差异,还解析了模型"迷失"的根本原因及有效缓解策略。
来自主题: AI技术研报
7013 点击 2025-05-20 10:16