

离谱!DeepSeek数个字母,竟要“反思内耗”八百遍?
离谱!DeepSeek数个字母,竟要“反思内耗”八百遍?最近,我撞见了一个 DeepSeek 又“认真”又“拧巴”的怪异场景。
来自主题: AI技术研报
8045 点击 2025-04-23 10:23
最近,我撞见了一个 DeepSeek 又“认真”又“拧巴”的怪异场景。

你是否正在投入大量资源开发基于MCP的Agent,却从未质疑过一个基本假设:MCP真的比传统函数调用更有优势吗? 2025年4月的这项开创性研究直接挑战了这一广泛接受的观点,其执行摘要明确指出:"使用MCPs并不显示出比函数调用有明显改进"。

AI 也要 007 工作制了!

DeepSeek-R1是近年来推理模型领域的一颗新星,它不仅突破了传统LLM的局限,还开启了全新的研究方向「思维链学」(Thoughtology)。这份长达142页的报告深入剖析了DeepSeek-R1的推理过程,揭示了其推理链的独特结构与优势,为未来推理模型的优化提供了重要启示。

随着3D Gaussian Splatting(3DGS)成为新一代高效三维建模技术,它的自适应特性却悄然埋下了安全隐患。
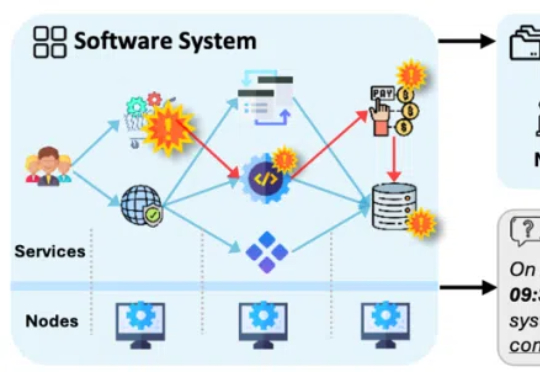
论文的第一作者是香港中文大学(深圳)数据科学学院三年级博士生徐俊杰龙,指导老师为香港中文大学(深圳)数据科学学院的贺品嘉教授和微软主管研究员何世林博士。贺品嘉老师团队的研究重点是软件工程、LLM for DevOps、大模型安全。
这款产品是一个改变世界的产品,而刚好有一个产品经理将其复刻出来了,即使一款产品拆解案例也是一个用AI产品从0到1搭建的过程。

给大家推荐一个好东西:21st.dev ,大致上你可以将它理解为一个非常前卫的组件托管市场
只靠模型尺寸变大已经不行了?大语言模型(LLM)推理需要强化学习(RL)来「加 buff」。

AI会无脑附和吗?Anthropic研究发现,Claude能根据场景切换人格:谈恋爱时化身情感导师,聊历史时秒变严谨学者。一些对话中,它强烈支持用户价值观,但在3%的情况下,它会果断抵制。
AI设计新型引力波探测工具,推动物理学突破,宇宙观测扩大50倍。
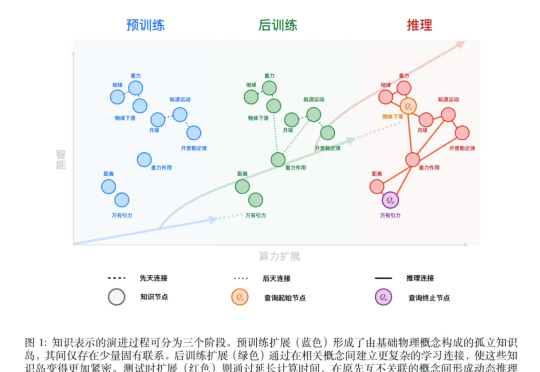
无论你是技术创造者还是使用者,理解这场认知革命都至关重要。我们正在从「AI as tools」向「AI as thinking partners」转变,这不仅改变了技术的能力边界,也改变了我们与技术协作的方式。

近日,上海人工智能实验室(上海 AI 实验室)开源了生成式世界模型 AETHER。该模型全部由合成数据训练而成,不仅在传统重建与生成任务中表现领先,更首次赋予大模型在真实世界中的 3D 空间决策与规划能力,

OpenAI 最近发布了三份针对企业客户的研究报告,本次挑选了其中的「A Practical guide to building AI agents」一篇进行了翻译。除非已经是 Agent 资深开发大佬,否则强烈建议 AI 行业的大家都来读一下这篇报告。

DeepSeek-R1 展示了强化学习在提升模型推理能力方面的巨大潜力,尤其是在无需人工标注推理过程的设定下,模型可以学习到如何更合理地组织回答。然而,这类模型缺乏对外部数据源的实时访问能力,一旦训练语料中不存在某些关键信息,推理过程往往会因知识缺失而失败。

本文对DeepMind两位泰斗级科学家David Silver和Richard Sutton的重磅论文《Welcome to the Era of Experience》进行了深度解读,我将其视为AI发展方向的一份战略瞭望图。

当前,强化学习(RL)方法在最近模型的推理任务上取得了显著的改进,比如 DeepSeek-R1、Kimi K1.5,显示了将 RL 直接用于基础模型可以取得媲美 OpenAI o1 的性能不过,基于 RL 的后训练进展主要受限于自回归的大语言模型(LLM),它们通过从左到右的序列推理来运行。

o3和o4-mini视觉推理突破,竟未引用他人成果?一名华盛顿大学博士生发出质疑,OpenAI研究人员对此回应:不存在。

动画片和我们拍摄的视频其实还是有很大不一样的。一般来说,我们平时观看的大多数电视剧使用25帧/秒的帧率,大多数电影使用24帧/秒的帧率。对于摄像机而言,帧率的调节无非是改一改摄影设备的参数,即使是胶片时代,也仅仅是胶片使用量的区别,对人工影响不大。

强化学习之父Richard Sutton和DeepMind强化学习副总裁David Silver对我们发出了当头棒喝:如今,人类已经由数据时代踏入经验时代。通往ASI之路要靠RL,而非人类数据!

「一位顶尖科学家,有数千亿美元的资源,却仍然能把Meta搞砸了!」最近,圈内对LeCun的埋怨和批评,似乎越来越压不住了。有人批评说,Meta之所以溃败,LeCun的教条主义就是罪魁祸首。但LeCun却表示,自己尝试了20年自回归预测,彻底失败了,所以如今才给LLM判死刑!

Hyper-RAG利用超图同时捕捉原始数据中的低阶和高阶关联信息,最大限度地减少知识结构化带来的信息丢失,从而减少大型语言模型(LLM)的幻觉。
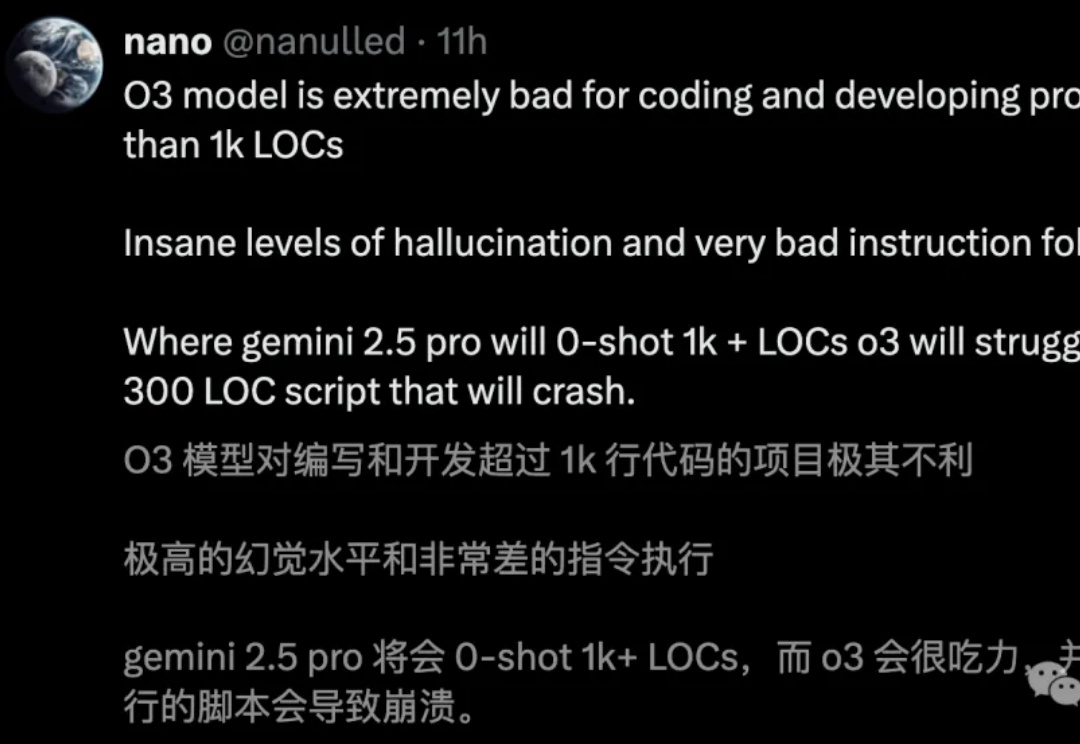
o3编码直逼全球TOP 200人类选手,却存在一个致命问题:幻觉率高达33%,是o1的两倍。Ai2科学家直指,RL过度优化成硬伤。
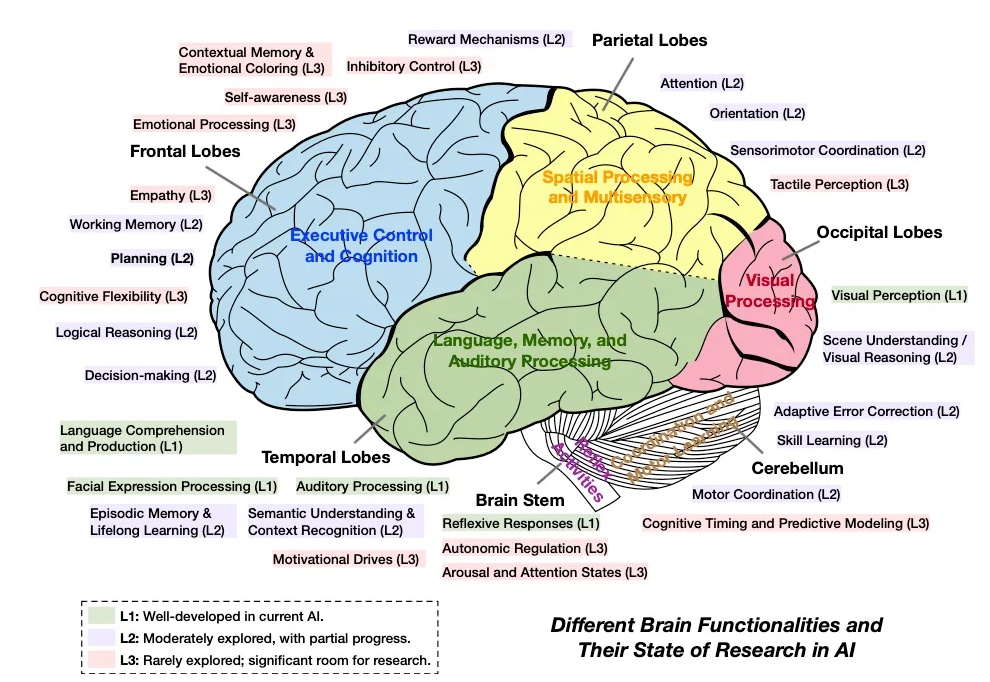
近期,大模型智能体(Agent)的相关话题爆火 —— 不论是 Anthropic 抢先 MCP 范式的快速普及,还是 OpenAI 推出的 Agents SDK 以及谷歌最新发布的 A2A 协议,都预示了 AI Agent 的巨大潜力。

还在用搜索和规则训练AI游戏?现在直接「看回放」学打宝可梦了!德州大学奥斯汀分校的研究团队用Transformer和离线强化学习打造出一个智能体,不靠规则、没用启发式算法,纯靠47.5万场人类对战回放训练出来,居然打上了Pokémon Showdown全球前10%!
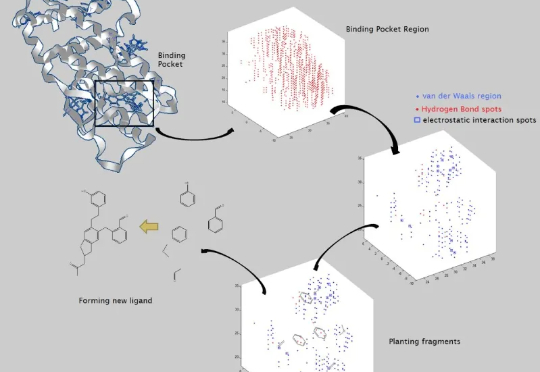
当前,人们对人工智能驱动的药物发现公司(以下简称 AIDD)这一新兴公司确发有效的界定。2025年开年,DeepSeek的爆火为AI医疗和AI制药领域带来了多维度变革。近日,BioPharma Trend发表了一份AI制药研究报告,报告力图从各个维度回答AI对生物医药的关键价值。

具身智能的突破离不开高质量数据。目前,具身合成数据有两条主要技术路线之争:“视频合成+3D重建”or “端到端3D生成”。英伟达在CES 2025指出“尚无互联网规模的机器人数据”,自动驾驶已具备城市级仿真,但家庭等复杂室内环境缺乏3D合成平台。

微软研究院开源的原生1bit大模型BitNet b1.58 2B4T,将低精度与高效能结合,开创了AI轻量化的新纪元。通过精心设计的推理框架,BitNet不仅突破了内存的限制,还在多项基准测试中表现出色,甚至与全精度模型不相上下。

在GitHub狂揽1w+星标的通义万相Wan2.1,又双叒上新了!
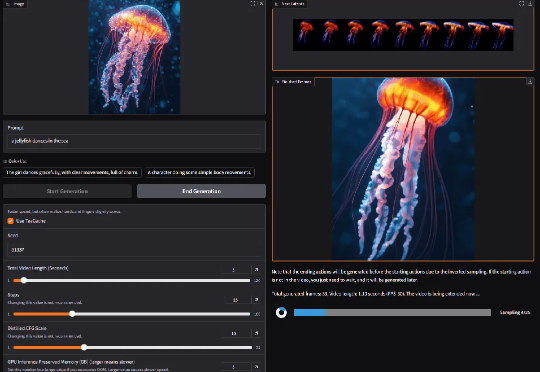
只用6GB显存的笔记本GPU,就能生成流畅的高质量视频!斯坦福研究团队重磅推出FramePack,大幅改善了视频生成中的遗忘和漂移难题。