
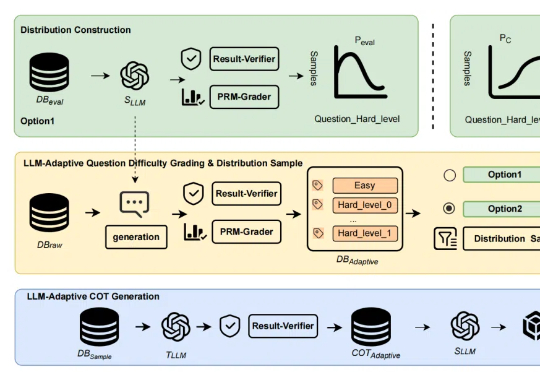
大模型推理上限再突破:「自适应难易度蒸馏」超越R1蒸馏,长CoT语料质量飞升
大模型推理上限再突破:「自适应难易度蒸馏」超越R1蒸馏,长CoT语料质量飞升近年来,「思维链(Chain of Thought,CoT)」成为大模型推理的显学,但要让小模型也拥有长链推理能力却非易事。
来自主题: AI技术研报
7047 点击 2025-05-04 17:08
近年来,「思维链(Chain of Thought,CoT)」成为大模型推理的显学,但要让小模型也拥有长链推理能力却非易事。

知名 Go 大佬 Thorsten Ball 最近用 315 行代码构建了一个编程智能体,并表示「它运行得非常好」且「没有护城河」(指它并非难以复制)。

近日,阿里云通义点金团队与苏州大学携手合作,在金融大语言模型领域推出了突破性的创新成果:DianJin-R1。

AI也会偷偷努力了?Letta和UC伯克利的研究者提出「睡眠时计算」技术,能让LLM在空闲时间提前思考,大幅提升推理效率。

颠覆LLM预训练认知:预训练token数越多,模型越难调!CMU、斯坦福、哈佛、普林斯顿等四大名校提出灾难性过度训练。

超越YOLOv3、Faster-RCNN,首个在COCO2017 val set上突破30AP的纯多模态开源LLM来啦!

技术在进化,验证码也该变得更有人情味一点。

扩散模型(Diffusion Models, DMs)如今已成为文本生成图像的核心引擎。凭借惊艳的图像生成能力,它们正悄然改变着艺术创作、广告设计、乃至社交媒体内容的生产方式。
MCP逐渐行业标准,提出者Anthropic也官宣了Claude两项重大的针对性更新——
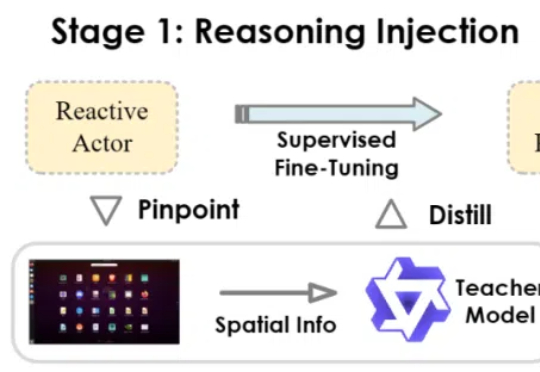
当前,多模态大模型驱动的图形用户界面(GUI)智能体在自动化手机、电脑操作方面展现出巨大潜力。然而,一些现有智能体更类似于「反应式行动者」(Reactive Actors),主要依赖隐式推理,面对需要复杂规划和错误恢复的任务时常常力不从心。

南加州大学团队只用9美元,就能在数学基准测试AIME 24上实现超过20%的推理性能提升,效果好得离谱!而其核心技术只需LoRA+强化学习,用极简路径实现超高性价比后训练。
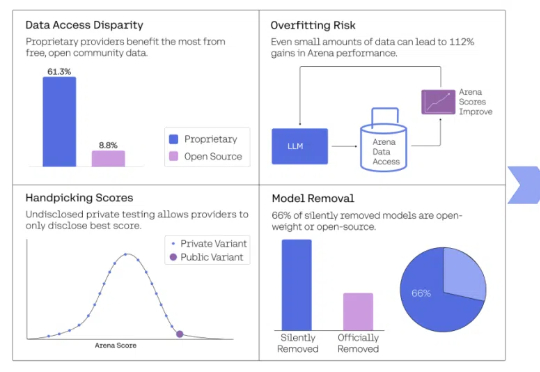
大模型竞技场的可信度,再次被锤。

这篇论文包含了当前 LLM 的许多要素,十年后的今天或许仍值得一读。
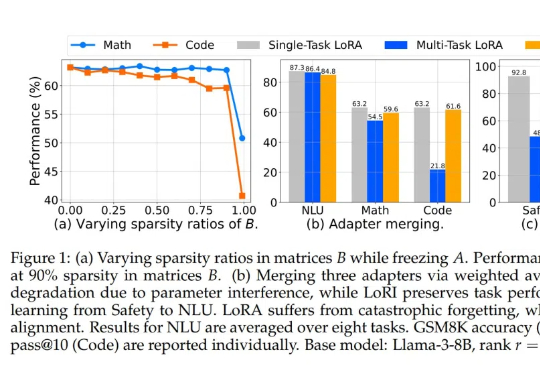
LoRA 中到底存在多少参数冗余?这篇创新研究介绍了 LoRI 技术,它证明即使大幅减少 LoRA 的可训练参数,模型性能依然保持强劲。
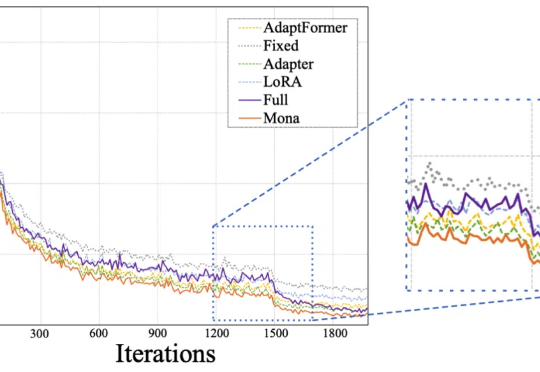
Mona(Multi-cognitive Visual Adapter)是一种新型视觉适配器微调方法,旨在打破传统全参数微调(full fine-tuning)在视觉识别任务中的性能瓶颈。

现如今,微调和强化学习等后训练技术已经成为提升 LLM 能力的重要关键。
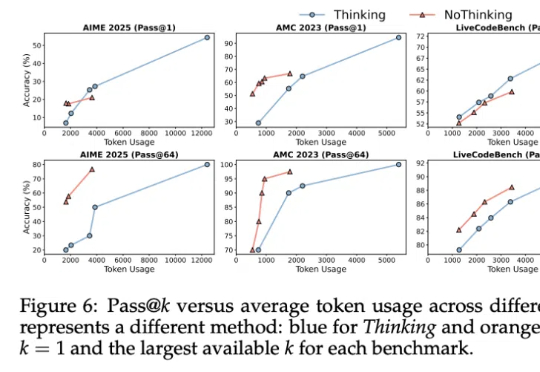
其实……不用大段大段思考,推理模型也能有效推理!
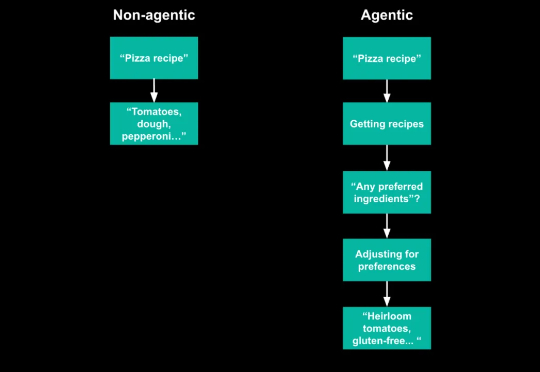
这段时间 “Agent” 成了热词,开会、聊天、朋友圈,大家都在聊。但每个人说的 “Agent” 其实都不一样,听多了反而更迷糊:究竟什么是 Agent?和我们熟悉的生成式 AI 有什么不同?这是我目前见过最清晰解释 Agent 的文章。
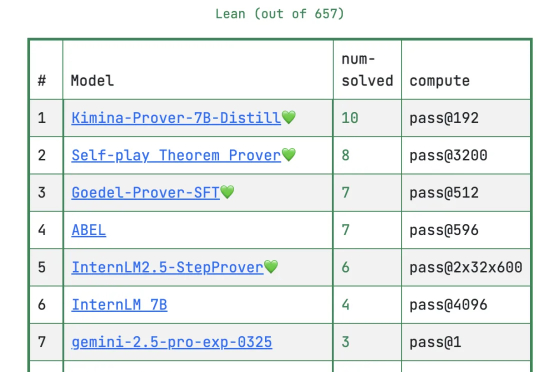
DeepSeek放大招!新模型专注数学定理证明,大幅刷新多项高难基准测试。在普特南测试上,新模型DeepSeek-Prover-V2直接把记录刷新到49道。目前的第一名在657道题中只做出10道题,为Kimi与AIME2024冠军团队Numina合作成果Kimina-Prover。

来自英伟达和UIUC的华人团队提出一种高效训练方法,将LLM上下文长度从128K扩展至惊人的400万token SOTA纪录!基于Llama3.1-Instruct打造的UltraLong-8B模型,不仅在长上下文基准测试中表现卓越,还在标准任务中保持顶尖竞争力。

在人工智能领域,语言模型的发展日新月异,推理能力作为语言模型的核心竞争力之一,一直是研究的焦点,许多的 AI 前沿人才对 AI 推理的效率进行研究。
在推荐、广告场景,如何利用好大模型的能力?这是个很有挑战的命题。
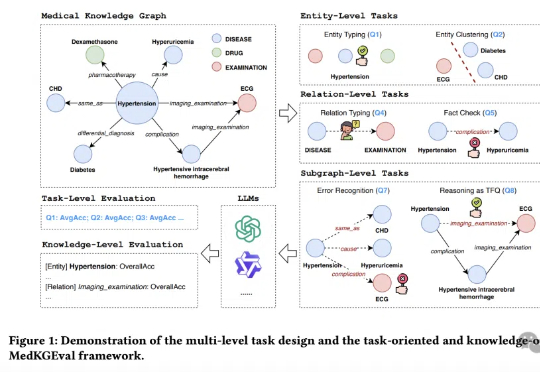
医疗大模型知识覆盖度首次被精准量化!
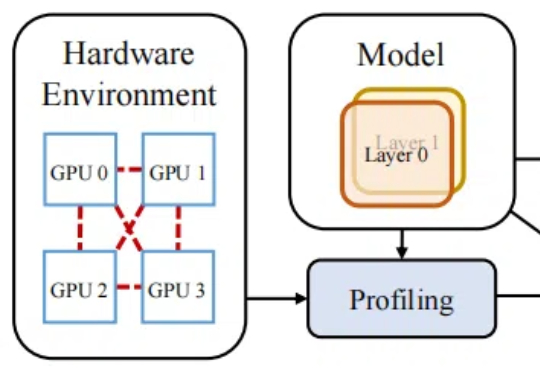
训练成本高昂已经成为大模型和人工智能可持续发展的主要障碍之一。
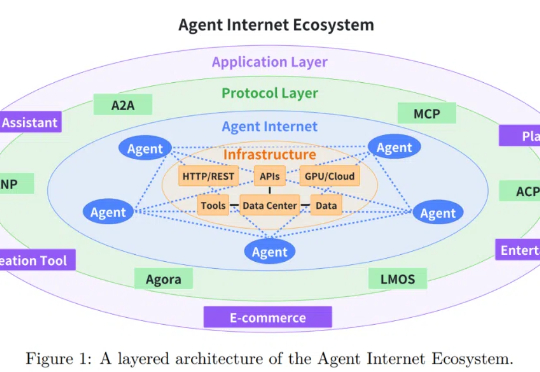
随着大语言模型 (LLM) 技术的迅猛发展,基于 LLM 的智能智能体在客户服务、内容创作、数据分析甚至医疗辅助等多个行业领域得到广泛应用。
近日,无问芯穹发起了一次推理系统开源节,连续开源了三个推理工作,包括加速端侧推理速度的 SpecEE、计算分离存储融合的 PD 半分离调度新机制 Semi-PD、低计算侵入同时通信正交的计算通信重叠新方法 FlashOverlap,为高效的推理系统设计提供多层次助力。下面让我们一起来对这三个工作展开一一解读:
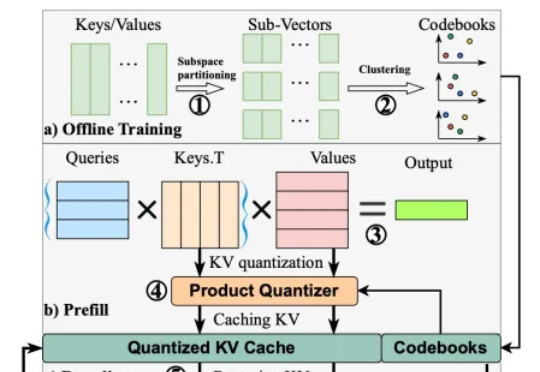
在以 transformer 模型为基础的大模型中,键值缓存虽然用以存代算的思想显著加速了推理速度,但在长上下文场景中成为了存储瓶颈。为此,本文的研究者提出了 MILLION,一种基于乘积量化的键值缓存压缩和推理加速设计。

在无数科幻电影中,增强现实(AR)通过在人们的眼前叠加动画、文字、图形等可视化信息,让人获得适时的、超越自身感知能力的信息。

AI能像人类一样不断从经验中学习、进化,而不仅仅依赖于人工标注的数据?测试时强化学习(TTRL)与记忆系统的结合正在开启这一全新可能!
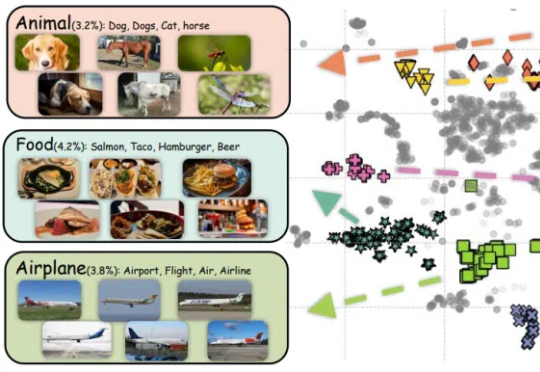
新的亿级大规模图文对数据集来了,CLIP达成新SOTA!