合成数据助力视频生成提速8.5倍,上海AI Lab开源AccVideo
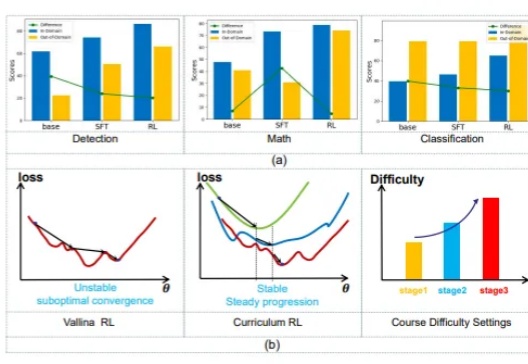
合成数据助力视频生成提速8.5倍,上海AI Lab开源AccVideo虽然扩散模型在视频生成领域展现出了卓越的性能,但是视频扩散模型通常需要大量的推理步骤对高斯噪声进行去噪才能生成一个视频。这个过程既耗时又耗计算资源。例如,HunyuanVideo [1] 需要 3234 秒才能在单张 A100 上生成 5 秒、720×1280、24fps 的视频。
来自主题: AI技术研报
7938 点击 2025-04-15 10:53