

刚刚,AI破解50年未解数学难题!南大校友用OpenAI模型完成首个非平凡数学证明
刚刚,AI破解50年未解数学难题!南大校友用OpenAI模型完成首个非平凡数学证明AI辅助人类,完成了首个非平凡研究数学证明,破解了50年未解的数学难题!在南大校友的研究中,这个难题中q=3的情况,由o3-mini-high给出了精确解。
来自主题: AI技术研报
7099 点击 2025-04-14 17:10
AI辅助人类,完成了首个非平凡研究数学证明,破解了50年未解的数学难题!在南大校友的研究中,这个难题中q=3的情况,由o3-mini-high给出了精确解。
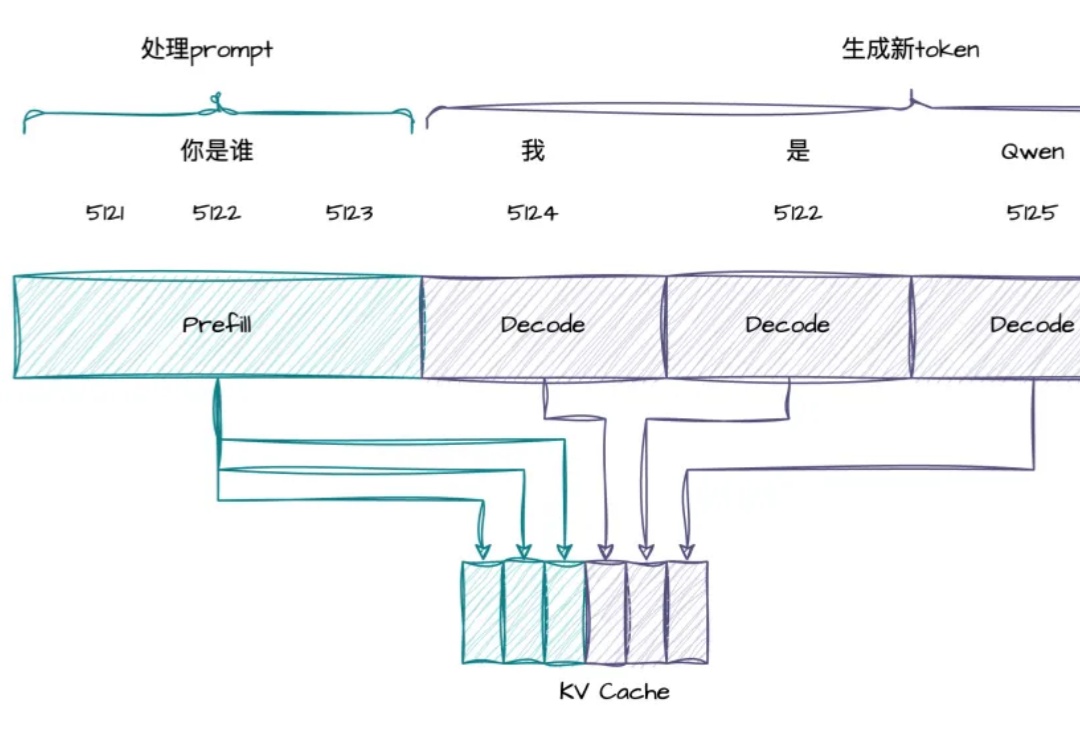
RTP-LLM 是阿里巴巴大模型预测团队开发的高性能 LLM 推理加速引擎。它在阿里巴巴集团内广泛应用,支撑着淘宝、天猫、高德、饿了么等核心业务部门的大模型推理需求。在 RTP-LLM 上,我们实现了一个通用的投机采样框架,支持多种投机采样方法,能够帮助业务有效降低推理延迟以及提升吞吐。
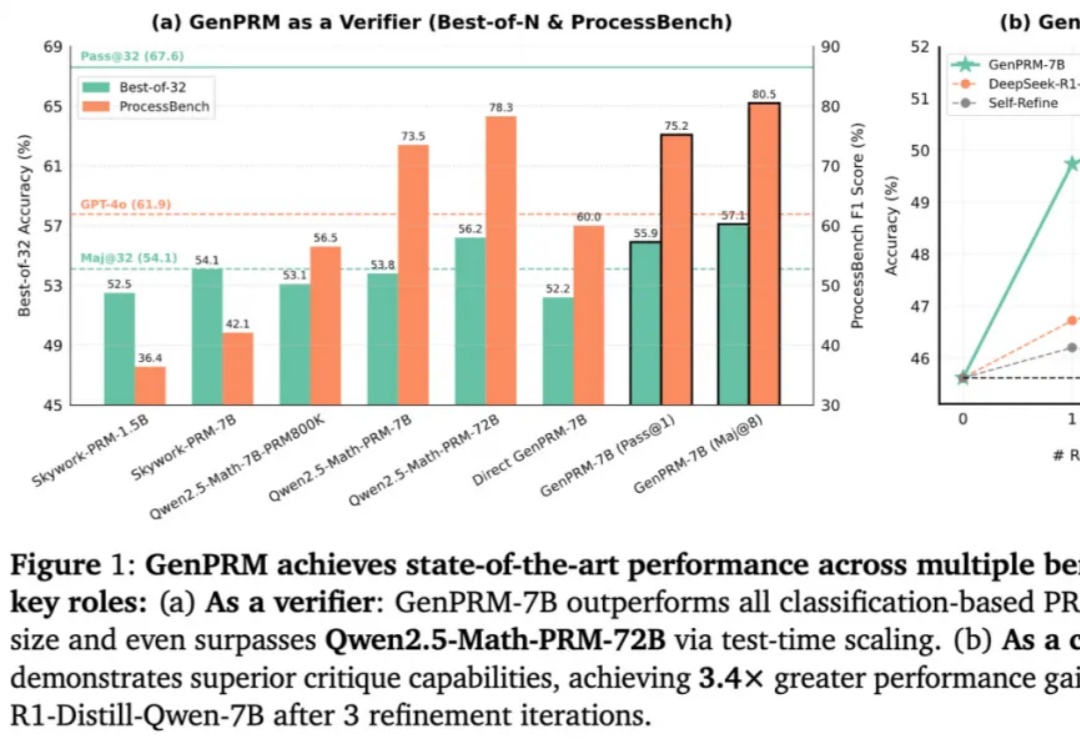
随着 OpenAI o1 和 DeepSeek R1 的爆火,大语言模型(LLM)的推理能力增强和测试时扩展(TTS)受到广泛关注。然而,在复杂推理问题中,如何精准评估模型每一步回答的质量,仍然是一个亟待解决的难题。传统的过程奖励模型(PRM)虽能验证推理步骤,但受限于标量评分机制,难以捕捉深层逻辑错误,且其判别式建模方式限制了测试时的拓展能力。
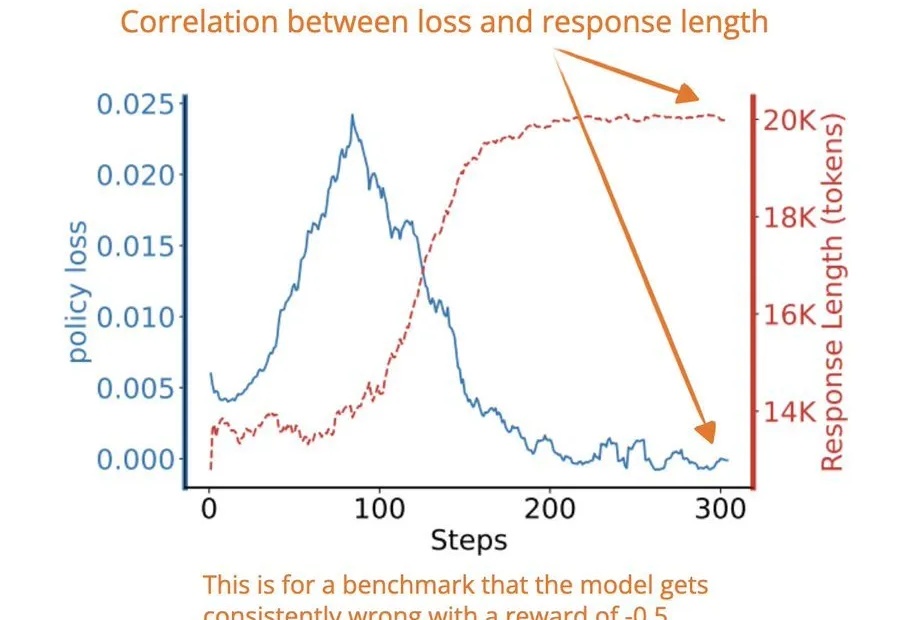
今天早些时候,著名研究者和技术作家 Sebastian Raschka 发布了一条推文,解读了一篇来自 Wand AI 的强化学习研究,其中分析了推理模型生成较长响应的原因。

研究发现,推理模型(如DeepSeek-R1、o1)遇到「缺失前提」(MiP)的问题时,这些模型往往表现失常:回答长度激增、计算资源浪费。本文基于马里兰大学和利哈伊大学的最新研究,深入剖析推理模型在MiP问题上的「过度思考」现象,揭示其背后的行为模式,带你一窥当前AI推理能力的真实边界。
近年来,随着大型语言模型(LLMs)的快速发展,多模态理解领域取得了前所未有的进步。像 OpenAI、InternVL 和 Qwen-VL 系列这样的最先进的视觉-语言模型(VLMs),在处理复杂的视觉-文本任务时展现了卓越的能力。
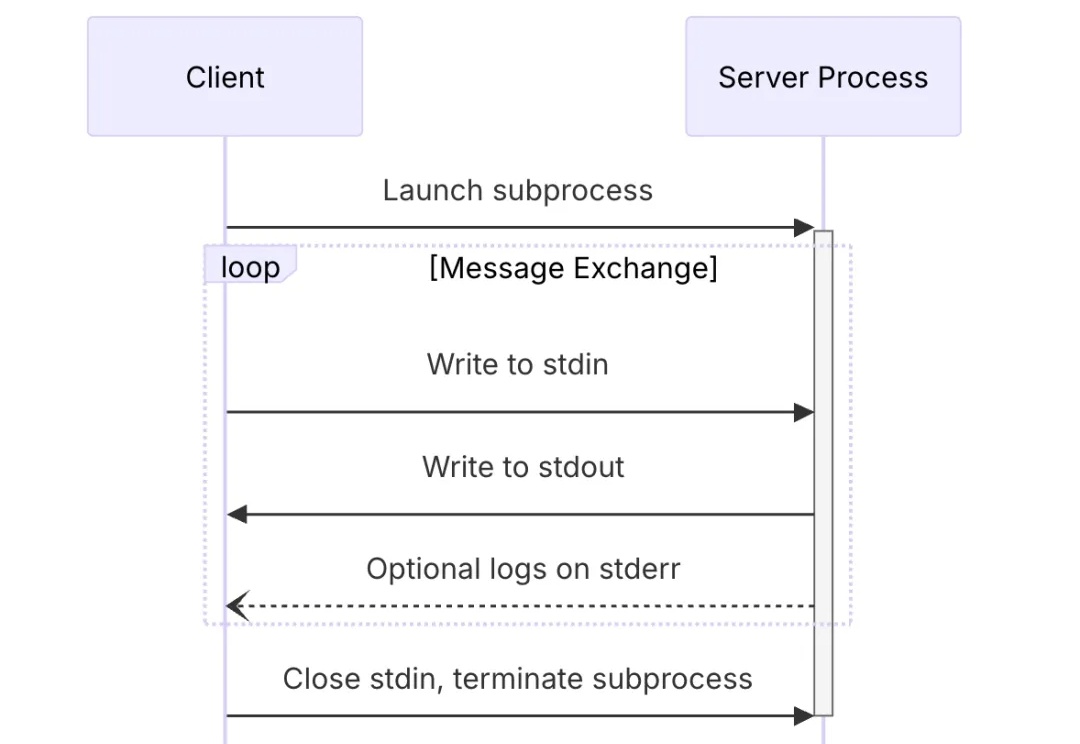
MCP 传输机制(Transport)是 MCP 客户端与 MCP 服务器通信的一个桥梁,定义了客户端与服务器通信的细节,帮助客户端和服务器交换消息。
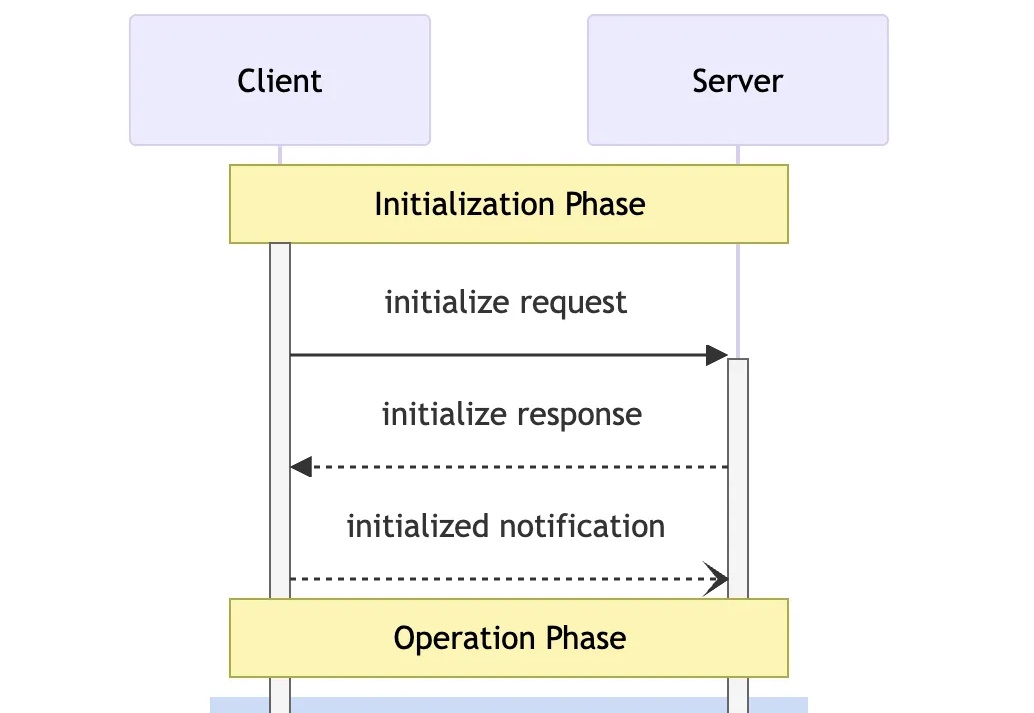
MCP 协议定义了一个严格的生命周期,用于客户端-服务器连接,确保了通信双方能进行适当的状态管理和能力协商。
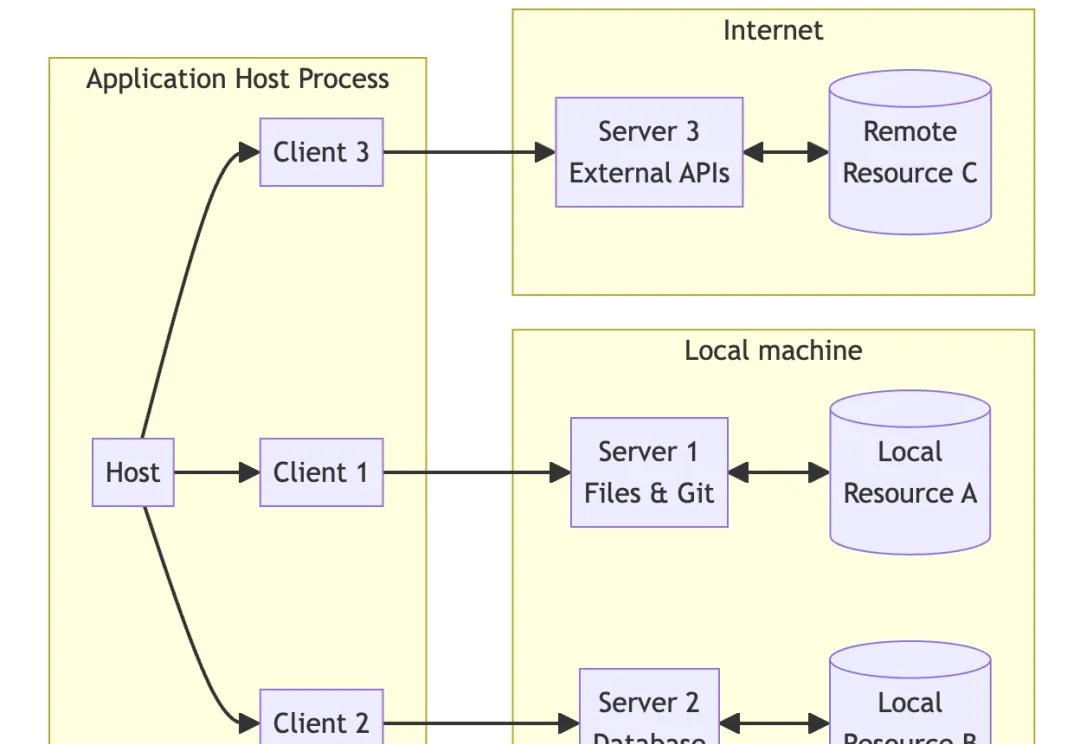
MCP 协议遵循互联网常见的 C / S 架构,即客户端(Client)- 服务器(Server)架构。
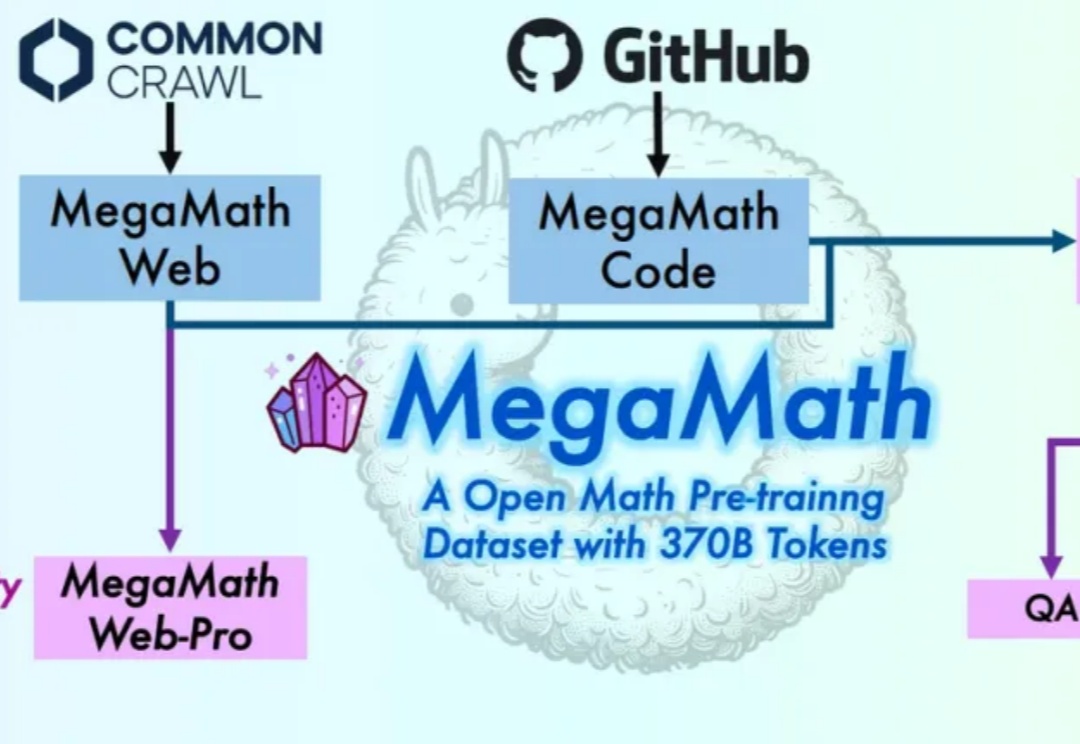
在大模型迈向推理时代的当下,数学推理能力已成为衡量语言模型智能上限的关键指标。

终于,华为盘古大模型系列上新了,而且是昇腾原生的通用千亿级语言大模型。我们知道,如今各大科技公司纷纷发布百亿、千亿级模型。但这些大部分模型训练主要依赖英伟达的 GPU。
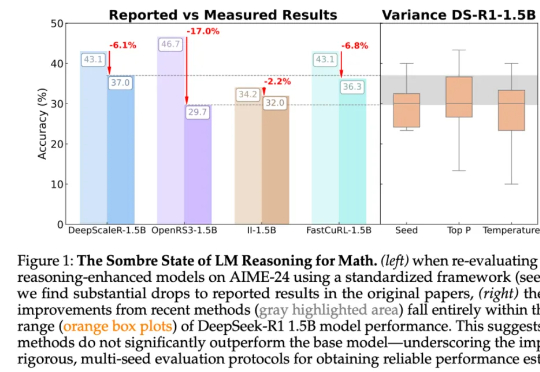
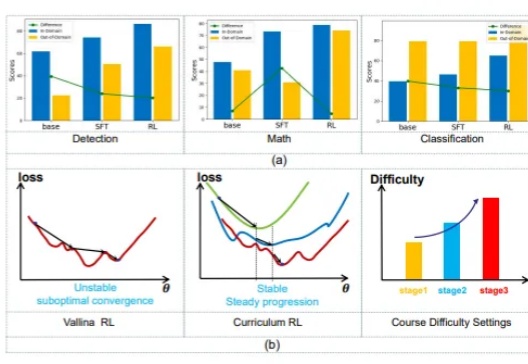
尽管这些论文的结论统统指向了强化学习带来的显著性能提升,但来自图宾根大学和剑桥大学的研究者发现,强化学习导致的许多「改进」可能只是噪音。「受推理领域越来越多不一致的经验说法的推动,我们对推理基准的现状进行了严格的调查,特别关注了数学推理领域评估算法进展最广泛使用的测试平台之一 HuggingFaceH4,2024;AI - MO。」

本文作者刘圳是香港中文大学(深圳)数据科学学院的助理教授,肖镇中是德国马克思普朗克-智能系统研究所和图宾根大学的博士生,刘威杨是德国马克思普朗克-智能系统研究所的研究员,Yoshua Bengio 是蒙特利尔大学和加拿大 Mila 研究所的教授,张鼎怀是微软研究院的研究员。此论文已收录于 ICLR 2025。

来自Meta和NYU的团队,刚刚提出了一种MetaQuery新方法,让多模态模型瞬间解锁多模态生成能力!令人惊讶的是,这种方法竟然如此简单,就实现了曾被认为需要MLLM微调才能具备的能力。

GitHub 在其 Copilot 功能中引入了一项基于 AI 的密码扫描功能,该功能已经整合到 GitHub Secret Protection 中。

如果你没有杜蕾斯背后强大的5A广告公司、鬼才般的创意团队、句句封神的的金牌文案、审美爆辣的视觉艺术家。借助即梦刚上线的3.0生图模型以及 Deepseek生创意和文案,你也可以轻松复刻一个「杜蕾斯级别」的刷屏海报。

人和智能体共享奖励参数,这才是强化学习正确的方向?

仅用4090就能实现大规模城市场景重建!

在大模型争霸的时代,算力与效率的平衡成为决定胜负的关键。

AI Agent 领域也存在 scaling law,甚至还在加速。

简单分享一份下线 AI 产品的信息列表(AI Graveyard),里面囊括的产品小类非常多。
高质量数据枯竭,传统预训练走向终点,大模型如何突破瓶颈?
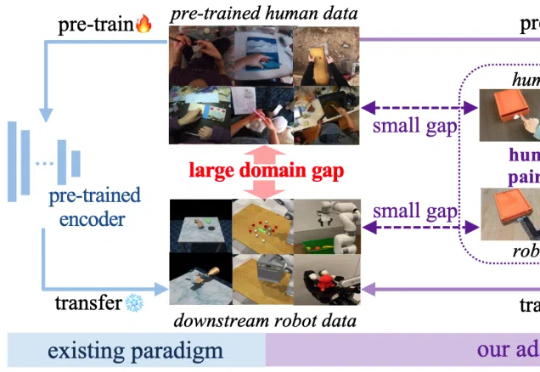
“让机器人看懂世界、听懂指令、动手干活”正从科幻走向现实。
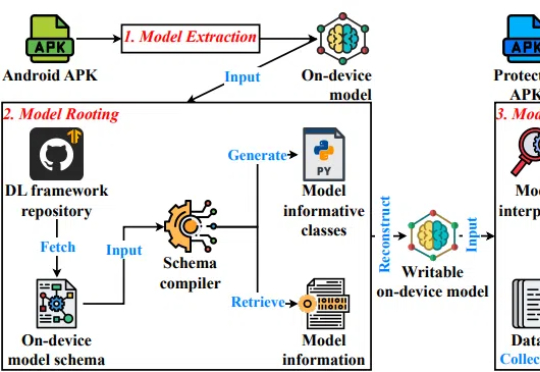
随着智能手机和物联网设备普及,移动端AI成为趋势,带来离线运行、低延迟、隐私保护等优势。然而,模型本地存储同时带来了严重风险。

字节跳动豆包团队今天发布了自家新推理模型 Seed-Thinking-v1.5 的技术报告。从报告中可以看到,这是一个拥有 200B 总参数的 MoE 模型,每次工作时会激活其中 20B 参数。其表现非常惊艳,在各个领域的基准上都超过了拥有 671B 总参数的 DeepSeek-R1。有人猜测,这就是字节豆包目前正在使用的深度思考模型。

大家还记得那个 ICLR 2025 首次满分接收、彻底颠覆静态图像光照编辑的工作 IC-Light 吗?

报告深入分析了特朗普总统于2025年4月2日宣布的“解放日”关税措施对美国人工智能(AI)基础设施建设、相关供应链以及全球贸易格局的潜在影响。
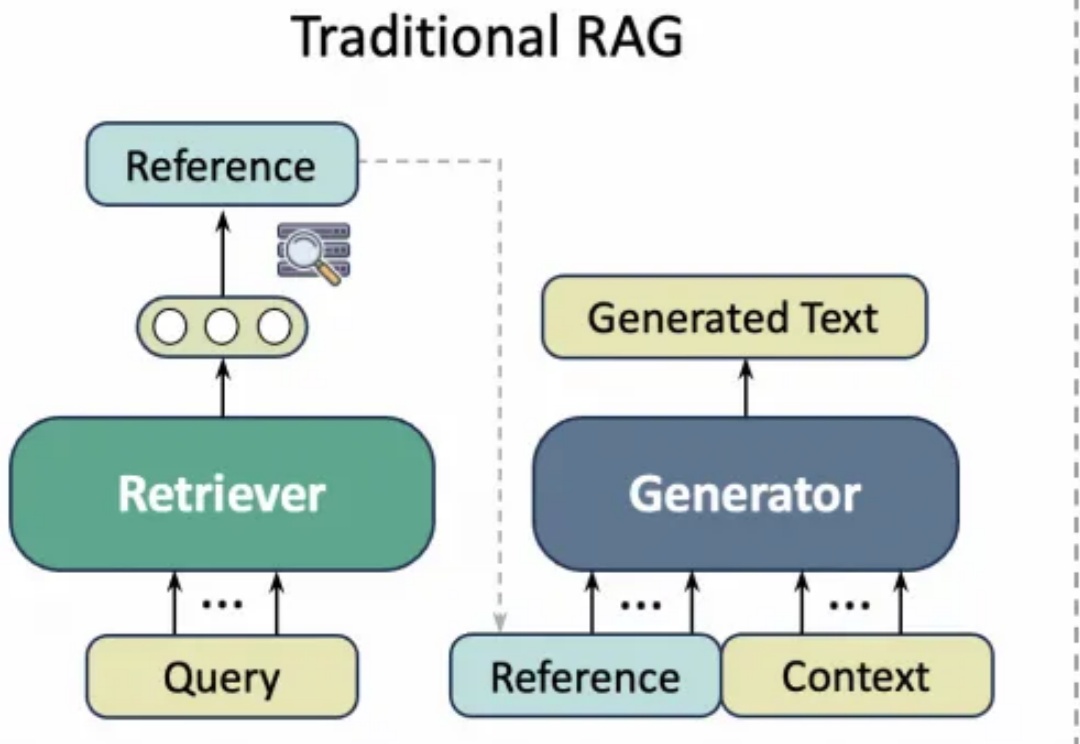
随着技术的深入应用,如何高效利用大模型技术优化用户体验,同时应对其带来的诸多挑战?本文将从RAG的发展趋势、技术挑战、核心举措以及未来展望四个维度总结我们应对挑战的新的思路和方法。
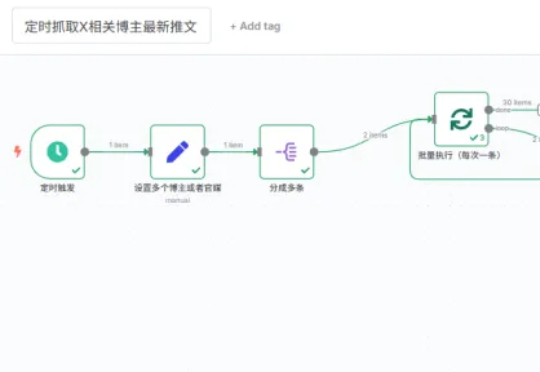
前两天给大家分享了一个我认为最强的开源AI Workflow平台:n8n。经过这几天的研究,我用n8n实现了一套超实用的X(原Twitter)热点监控workflow(工作流)。它由两个workflow(工作流)组成
学术写作通常需要花费大量精力查询文献引用,而以ChatGPT、GPT-4等为代表的通用大语言模型(LLM)虽然能够生成流畅文本,但经常出现“引用幻觉”(Citation Hallucination),即模型凭空捏造文献引用。这种现象严重影响了学术论文的可信度与专业性。