
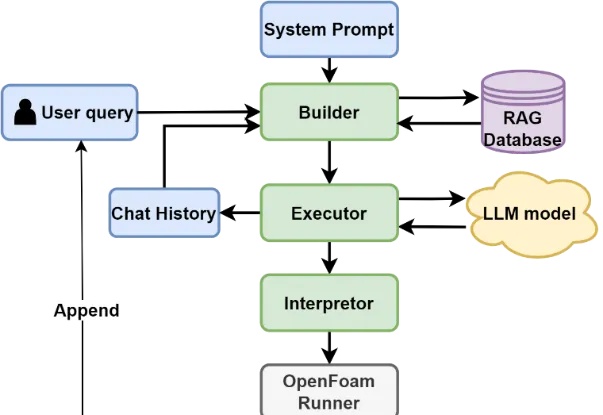
流体力学专用版DeepSeek,单GPU可跑,成本节约高达100倍
流体力学专用版DeepSeek,单GPU可跑,成本节约高达100倍又一专业领域成功引入AI工程师!
来自主题: AI技术研报
7012 点击 2025-04-11 10:00
又一专业领域成功引入AI工程师!

在现实世界中,如何让智能体理解并挖掘 3D 场景中可交互的部位(Affordance)对于机器人操作与人机交互至关重要。所谓 3D Affordance Learning,就是希望模型能够根据视觉和语言线索,自动推理出物体可供哪些操作、以及可交互区域的空间位置,从而为机器人或人工智能系统提供对物体潜在操作方式的理解。

港中文、清华等高校提出SICOG框架,通过预训练、推理优化和后训练协同,引入自生成数据闭环和结构化感知推理机制,实现模型自我进化,为大模型发展提供新思路。
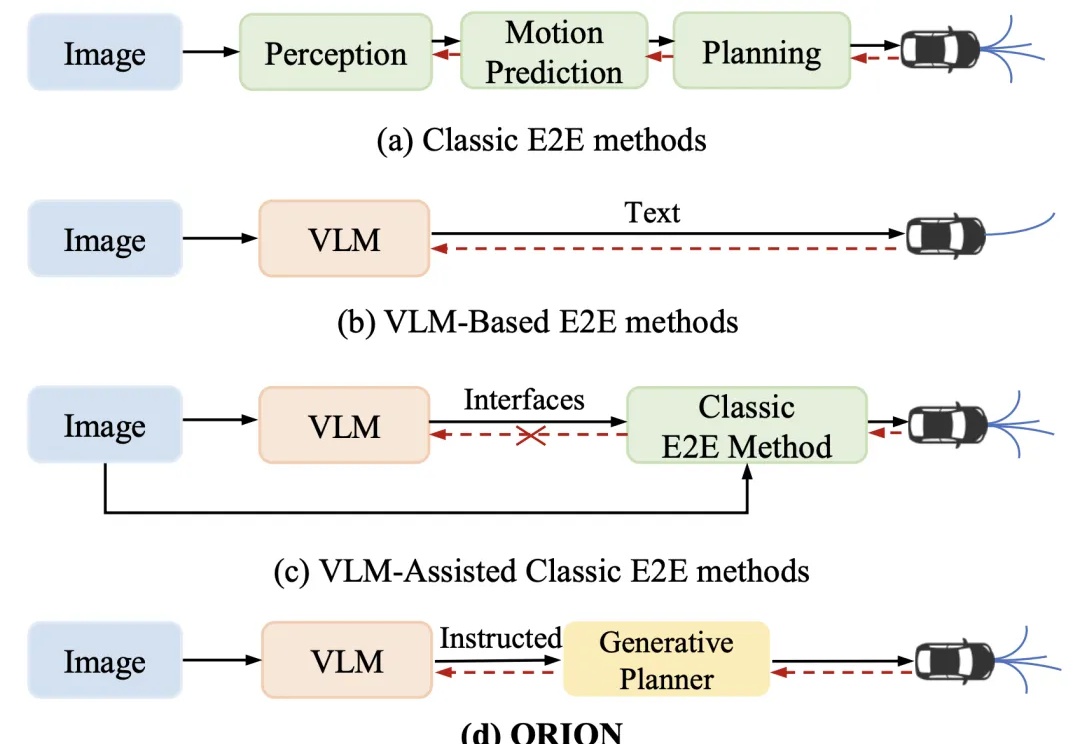
近年来,端到端(End-to-End,E2E)自动驾驶技术不断进步,但在复杂的闭环交互环境中,由于其因果推理能力有限,仍然难以做出准确决策。虽然视觉 - 语言大模型(Vision-Language Model,VLM)凭借其卓越的理解和推理能力,为端到端自动驾驶带来了新的希望,但现有方法在 VLM 的语义推理空间和纯数值轨迹的行动空间之间仍然存在巨大鸿沟。
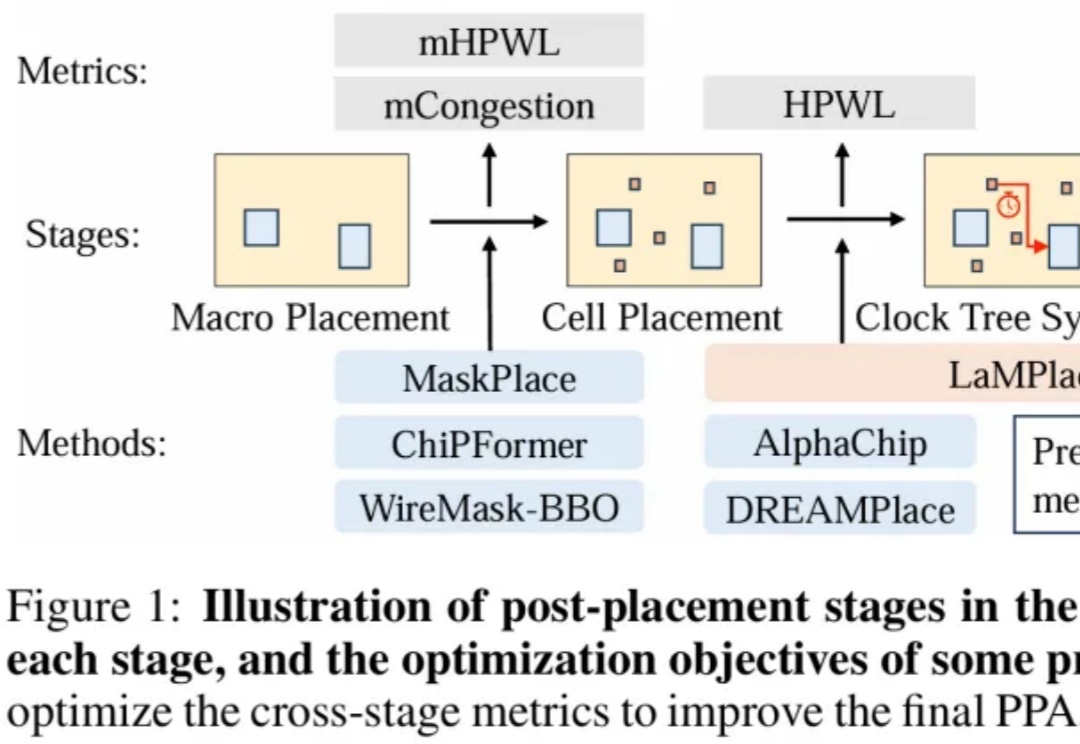
用AI指导芯片设计,中科大王杰教授团队、华为诺亚实验室、天津大学提出全新芯片宏单元布局优化方法LaMPlace!

刚刚,Kimi团队上新了!

利用字节团队魔改的FLUX模型,可以直接把多个参考主体放进一张图了。

谷歌Deep Research重大升级,搭载全球顶尖Gemini 2.5 Pro模型。5分钟生成46页学术论文、复杂报告转为10分钟播客。性能超OpenAI DR 40%,价格仅为其1/10。

世界模型领域最新进展,要比拼“世界生成”了。
OpenAI o1/o3-mini级别的代码推理模型竟被抢先开源!UC伯克利和Together AI联合推出的DeepCoder-14B-Preview,仅14B参数就能媲美o3-mini,开源代码、数据集一应俱全,免费使用。

自数字人技术Omnihuman-1引起行业关注之后,字节智能创作团队再放大招。全新DreamActor-M1横空出世,一张照片一段视频,就能生成电影级视频,精准迁移表情动作,还支持多种画风。
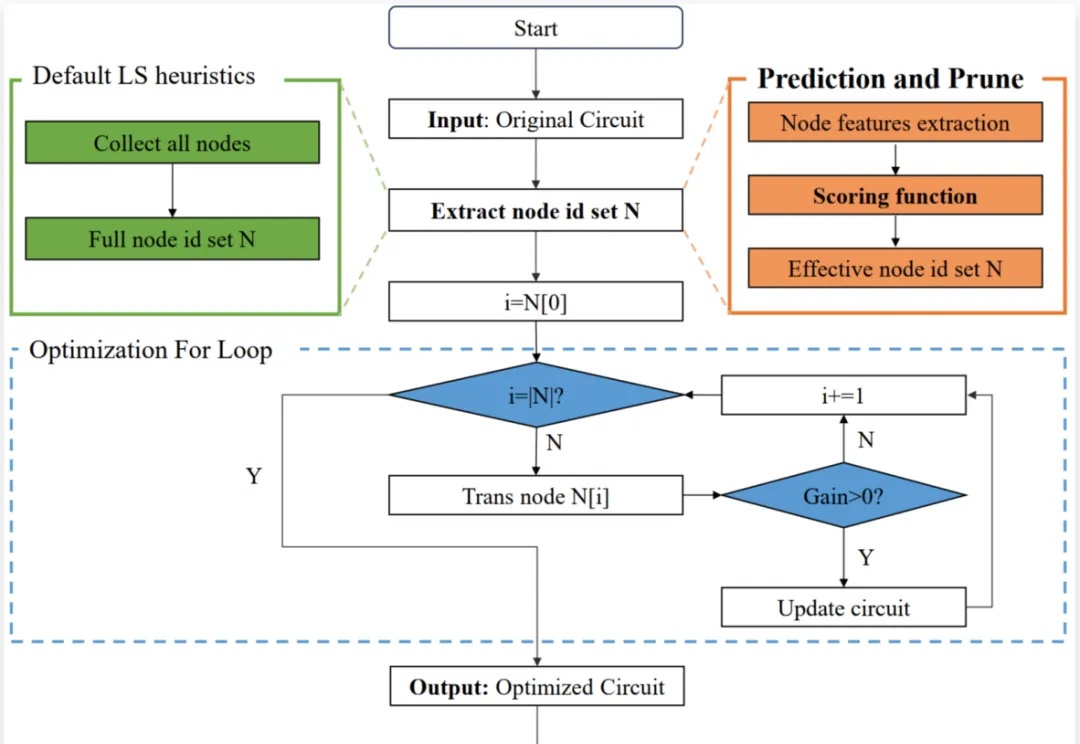
芯片设计是现代科技的核心,逻辑优化(Logic Optimization, LO)作为芯片设计流程中的关键环节,其效率直接影响着芯片设计的整体性能。

北京大学陈宝权教授团队提出RainyGS技术,通过结合物理模拟和3D高斯泼溅渲染框架,实现了真实场景中动态雨效的高质量仿真与呈现,真正实现「从真实到真实」,或者「以仿真乱真」,即Real2Sim2Real !相比现有的视频编辑工具(如 Runway),其物理真实性获得保证。

统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。
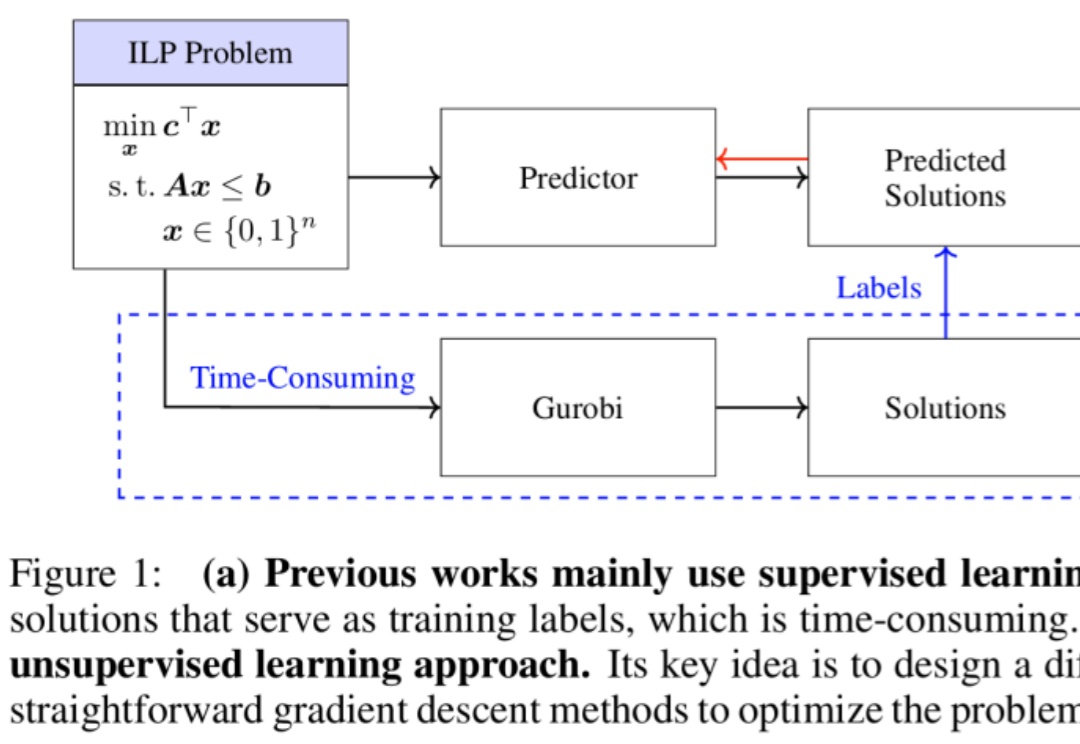
无监督学习训练整数规划求解器的新范式来了。

GPT-4o图像生成架构被“破解”了!

今天,我们正式发布jina-reranker-m0。这是一款多模态、多语言重排器(reranker),其核心能力在于 对包含丰富视觉元素的文档进行重排和精排,同时兼容跨语言场景。

随着 VR/AR、游戏娱乐、自动驾驶等领域对 3D 场景生成的需求不断攀升,从稀疏视角重建 3D 场景已成为一大热点课题。
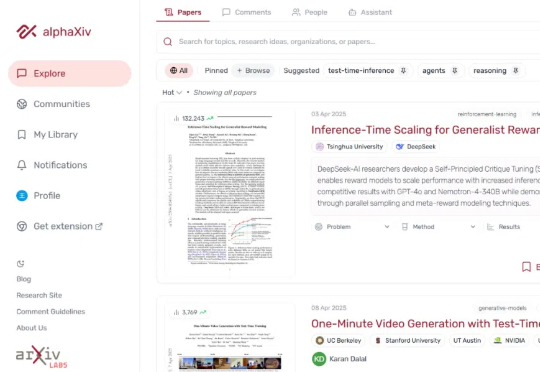
刚刚,alphaXiv 推出了新功能「Deep Research for arXiv」,该功能可协助研究人员更高效地在 arXiv 平台上进行学术论文的检索与阅读,显著提升文献检索及研究效率。

本篇论文是由南洋理工大学 S-Lab 与普渡大学提出的无分类引导新范式,支持所有 Flow Matching 的生成模型。目前已被集成至 Diffusers 与 ComfyUI。

阿里巴巴的云业务部门正升级其海外可用的人工智能工具套件,以吸引更多全球客户。
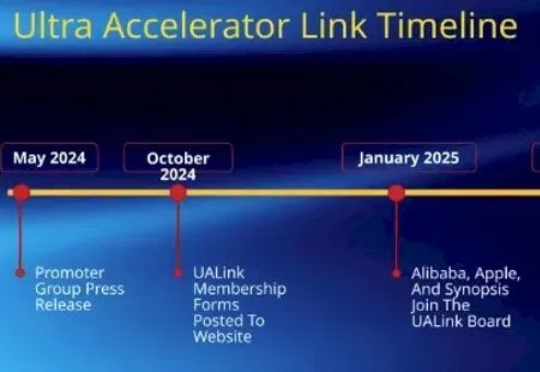
UALink 1.0发布:支持1024 GPU,200GT/s带宽,开放标准挑战NVLink。
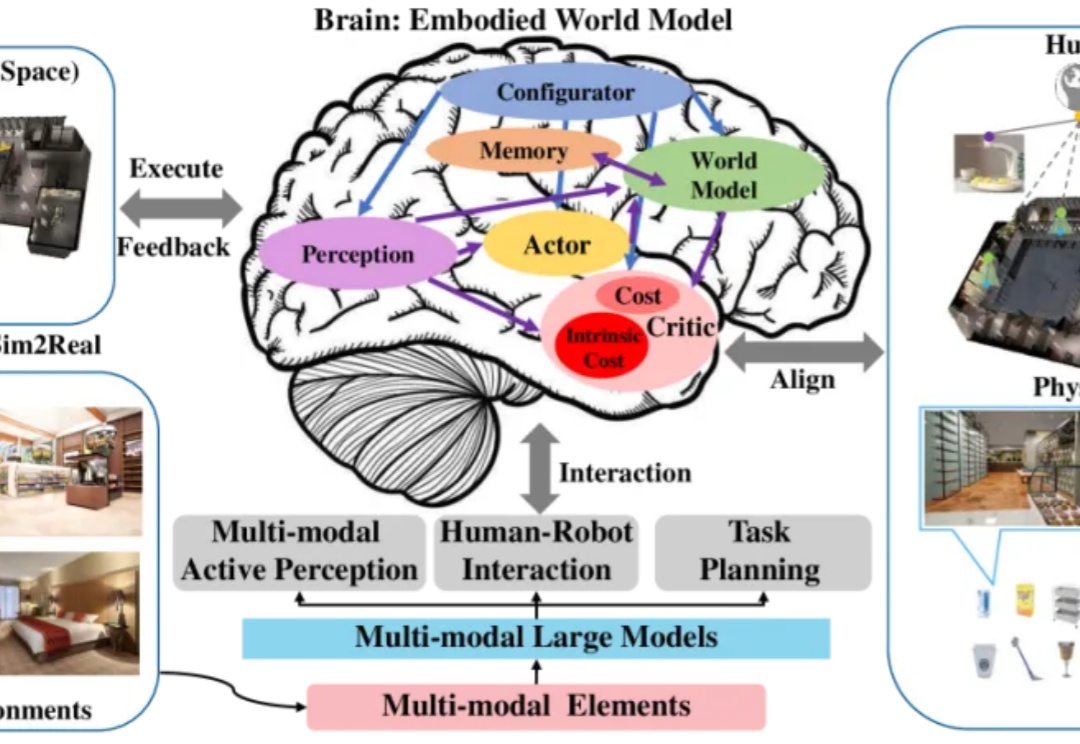
本文主要描述了具身合成数据两条主要技术路线之争:“视频合成+3D重建”or “端到端3D生成”。参考自动驾驶的成功经验,前者模态转换链路过长导致误差累积,'直接合成3D数据'理论上有信息效率优势,但需要克服“常识欠缺”等挑战。

刚刚,一位AI公司CEO细细扒皮了关于Llama 4的五大疑点。甚至有圈内人表示,Llama 4证明Scaling已经结束了,LLM并不能可靠推理。但更可怕的事,就是全球的AI进步恐将彻底停滞。
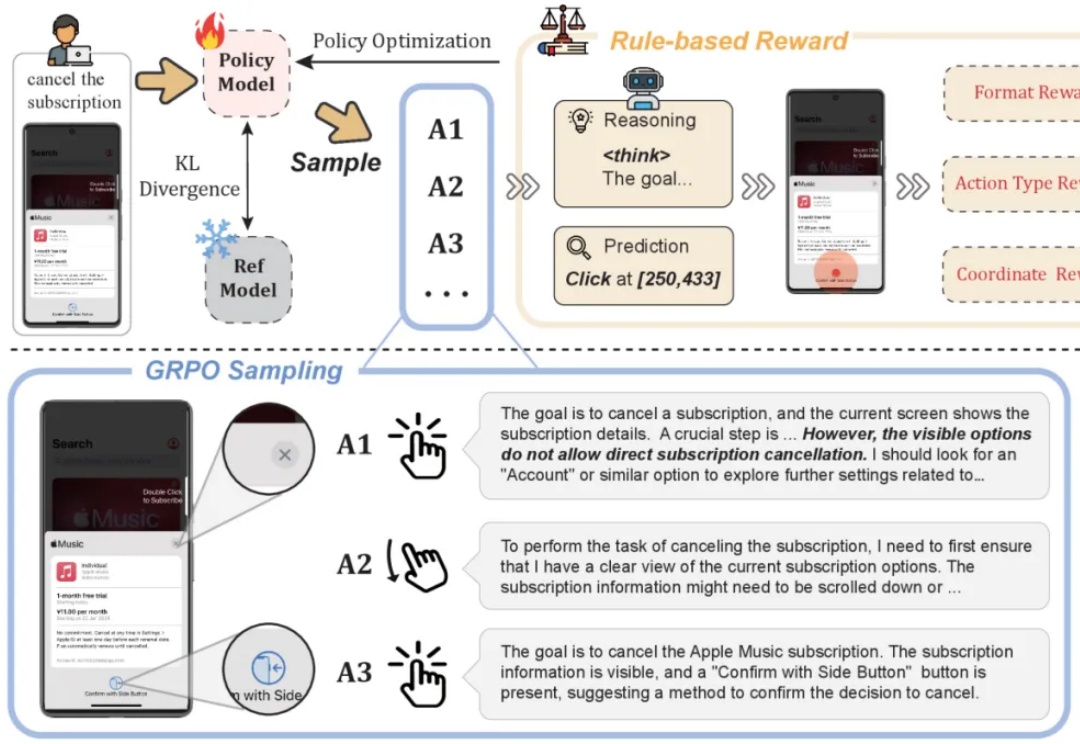
基于规则的强化学习(RL/RFT)已成为替代 SFT 的高效方案,仅需少量样本即可提升模型在特定任务中的表现。

大规模数据集和标准化评估基准显著促进了自然语言处理和计算机视觉领域的发展。然而,机器人领域在如何构建大规模数据集并建立可靠的评估体系方面仍面临巨大挑战。

多模态视频异常理解任务,又有新突破!

AI绘画总「翻车」,不是抓不住重点,就是细节崩坏?别愁!微软和港中文学者带来ImageGen-CoT技术,让AI像人一样思考推理,生成超惊艳画作,性能提升高达80%。
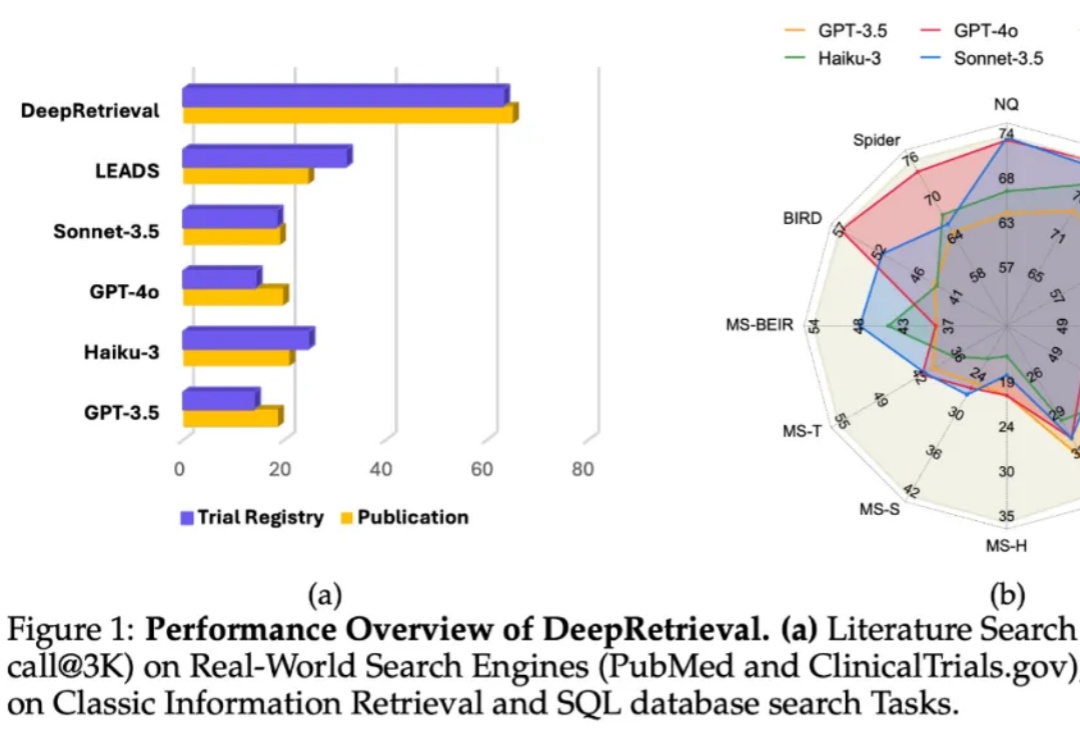
在信息检索系统中,搜索引擎的能力只是影响结果的一个方面,真正的瓶颈往往在于:用户的原始 query 本身不够好。
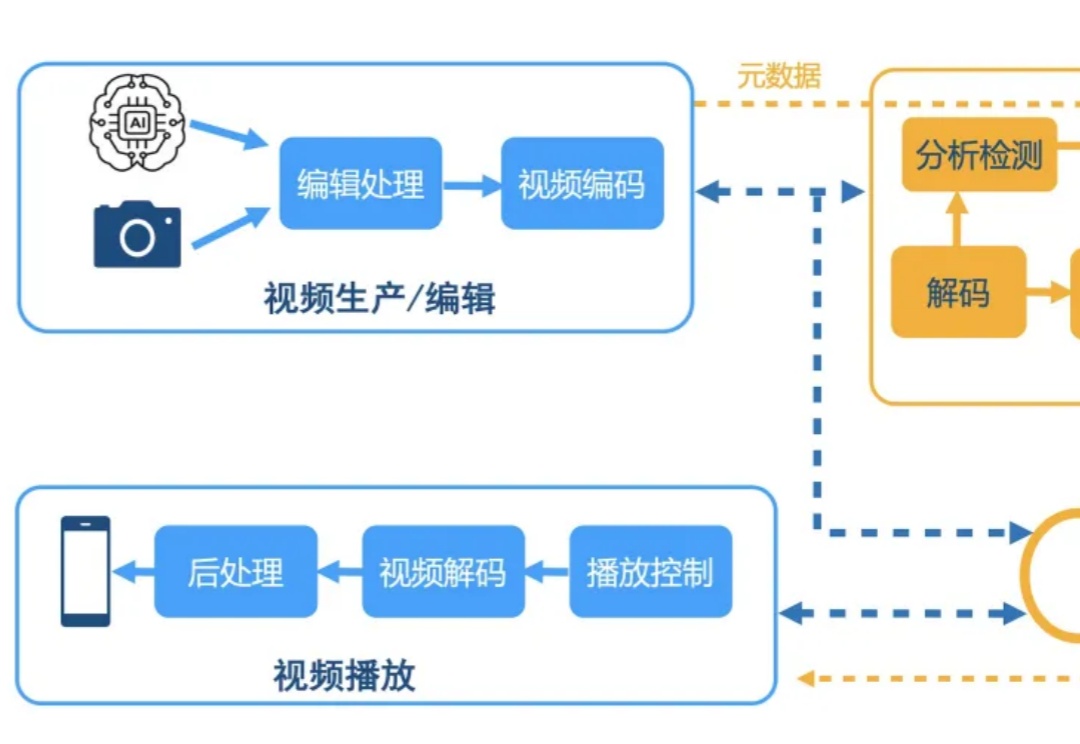
Q-Insight不再简单地让模型拟合人眼打分,而是将评分视作一种引导信号,促使模型深度思考图像质量的本质原因。有了会思考的“大脑”,视频云技术栈不仅得以重塑也让用户体验有了跃迁。