
Multi-Agents 系统太难搞了,不要轻易尝试 | UC Berkeley 论文分享
Multi-Agents 系统太难搞了,不要轻易尝试 | UC Berkeley 论文分享这两年,AI 领域最激动人心的进展莫过于大型语言模型(LLM)的崛起,LLM 展现了惊人的理解和生成能力。
来自主题: AI技术研报
8026 点击 2025-03-28 09:33
这两年,AI 领域最激动人心的进展莫过于大型语言模型(LLM)的崛起,LLM 展现了惊人的理解和生成能力。
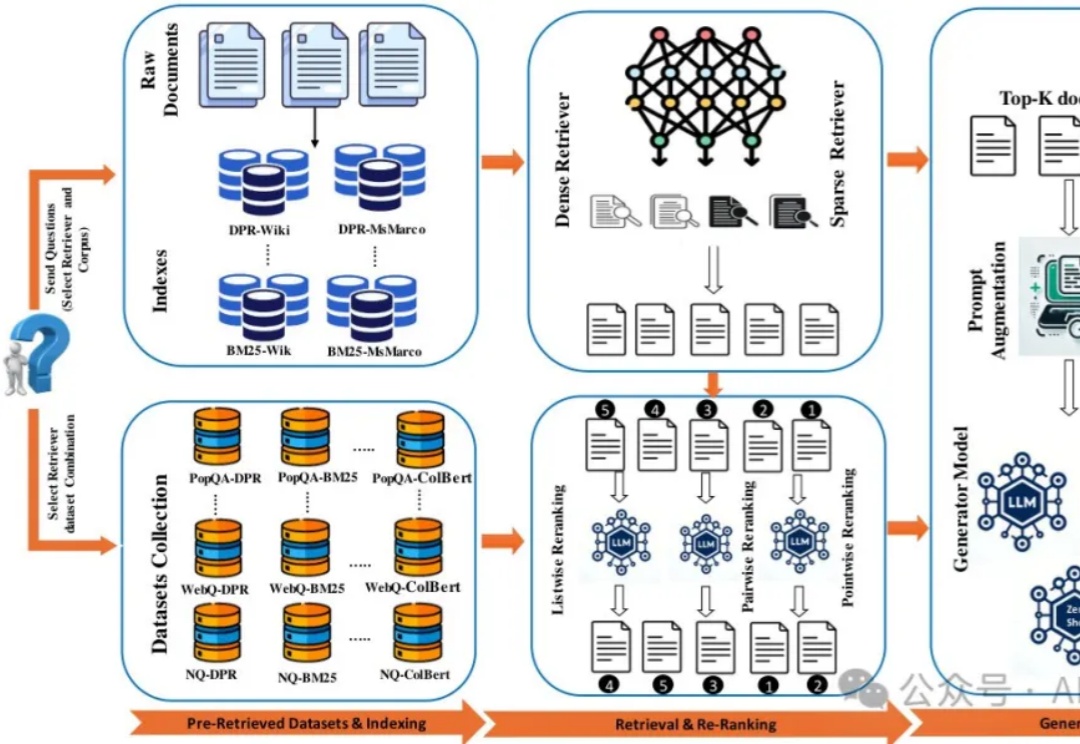
现有RAG工具的碎片化和复杂性常常让开发者头疼不已。昨天我的Agent群里朋友们就Rerank问题展开激烈讨论,我想起之前看到的一篇论文,这项研究介绍了一个完美的开源python工具包Rankify,它将检索、重排序和RAG三大功能整合在一个统一框架中,大幅简化了开发流程。
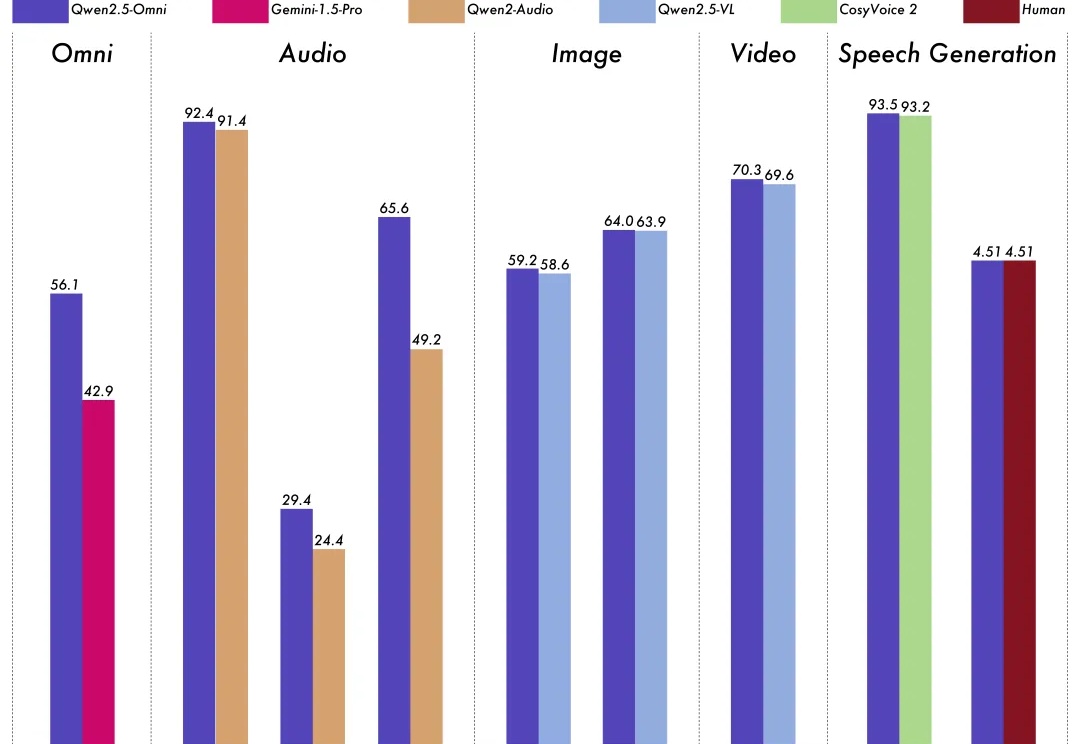
深夜重磅!阿里发布并开源首个端到端全模态大模型——
火,Agent可太火了!关于Agent的进展俯拾皆是,根本看不过来……
家人们震惊了!现在 AI 成精啦,不仅能写能画,现在连唱功都是格莱美级的了!

一种新的范式。
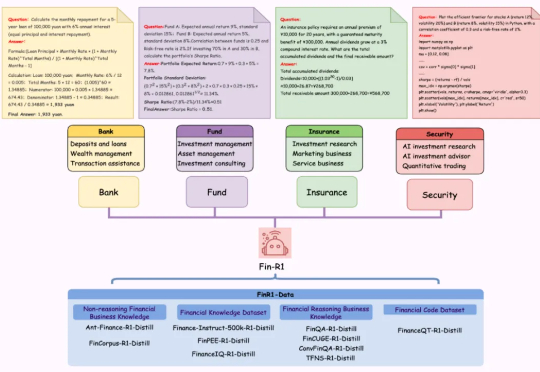
近日,上海财经大学统计与数据科学学院张立文教授与其领衔的金融大语言模型课题组(SUFE-AIFLM-Lab)联合数据科学和统计研究院、财跃星辰、滴水湖高级金融学院正式发布首款 DeepSeek-R1 类推理型人工智能金融大模型:Fin-R1,以仅 7B 的轻量化参数规模展现出卓越性能,全面超越参评的同规模模型并以 75 的平均得
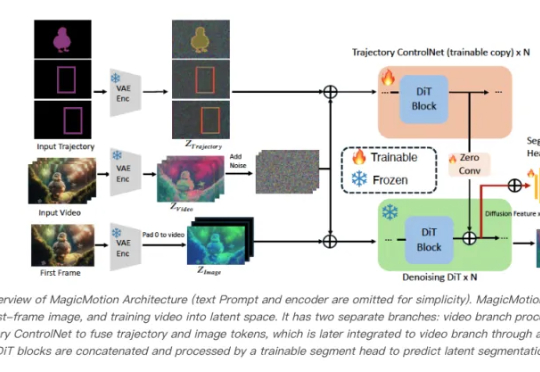
轨迹可控的视频生成来了,支持三种不同级别的轨迹控制条件——分别为掩码、边界框和稀疏框。研究人员提出了MagicMotion,一种创新的图像到视频生成框架,共同第一作者为复旦大学研究生李全昊、邢桢,通讯作者为复旦大学吴祖煊副教授。

在Stable Diffusion当中,只需加入一个LoRA就能根据图像创建3D模型了?
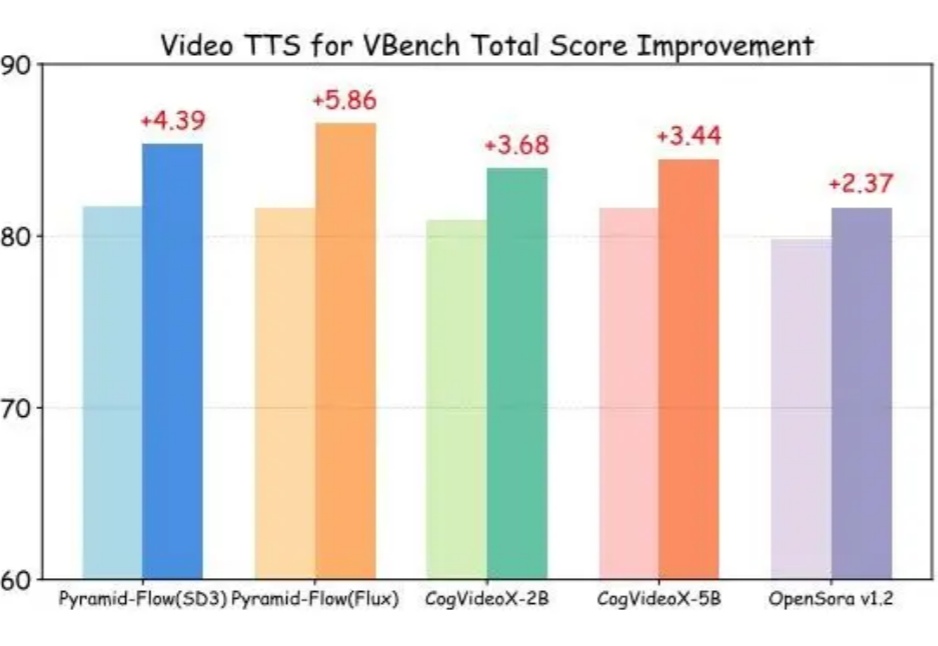
视频作为包含大量时空信息和语义的媒介,对于 AI 理解、模拟现实世界至关重要。视频生成作为生成式 AI 的一个重要方向,其性能目前主要通过增大基础模型的参数量和预训练数据实现提升,更大的模型是更好表现的基础,但同时也意味着更苛刻的计算资源需求。
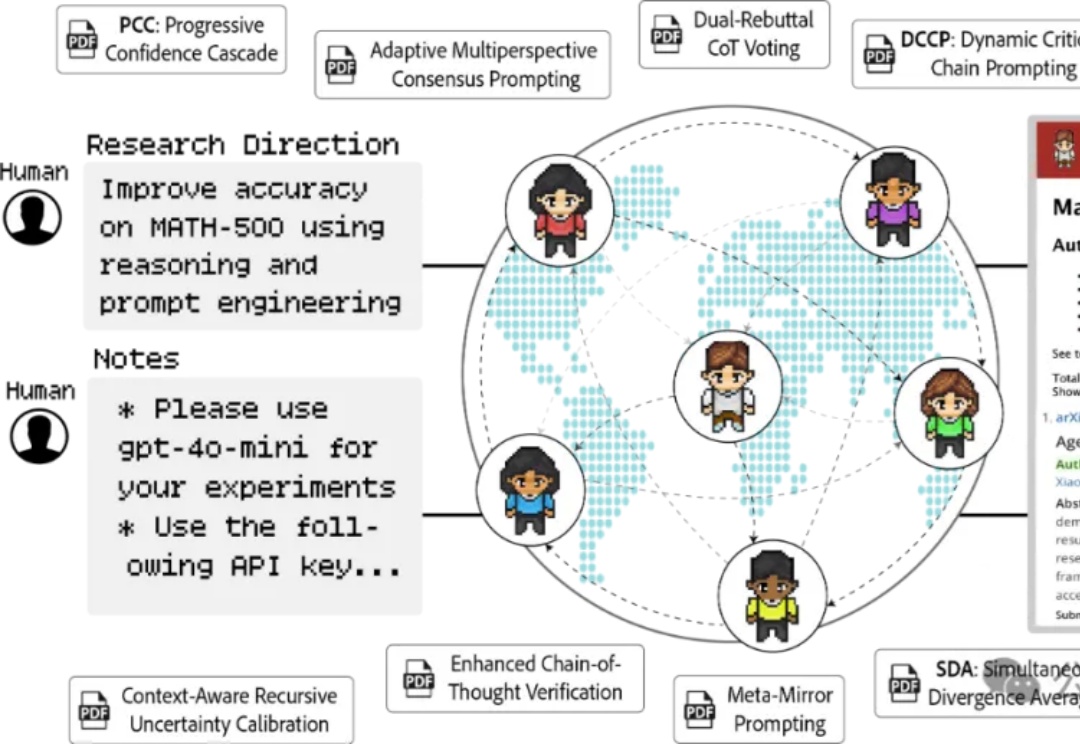
这项来自约翰霍普金斯与ETH Zurich的自主科研智能体框架AgentRxiv的确可以显著提高研究效率。我在测试了多次之后用Deepseek-V3-0324实现了它。
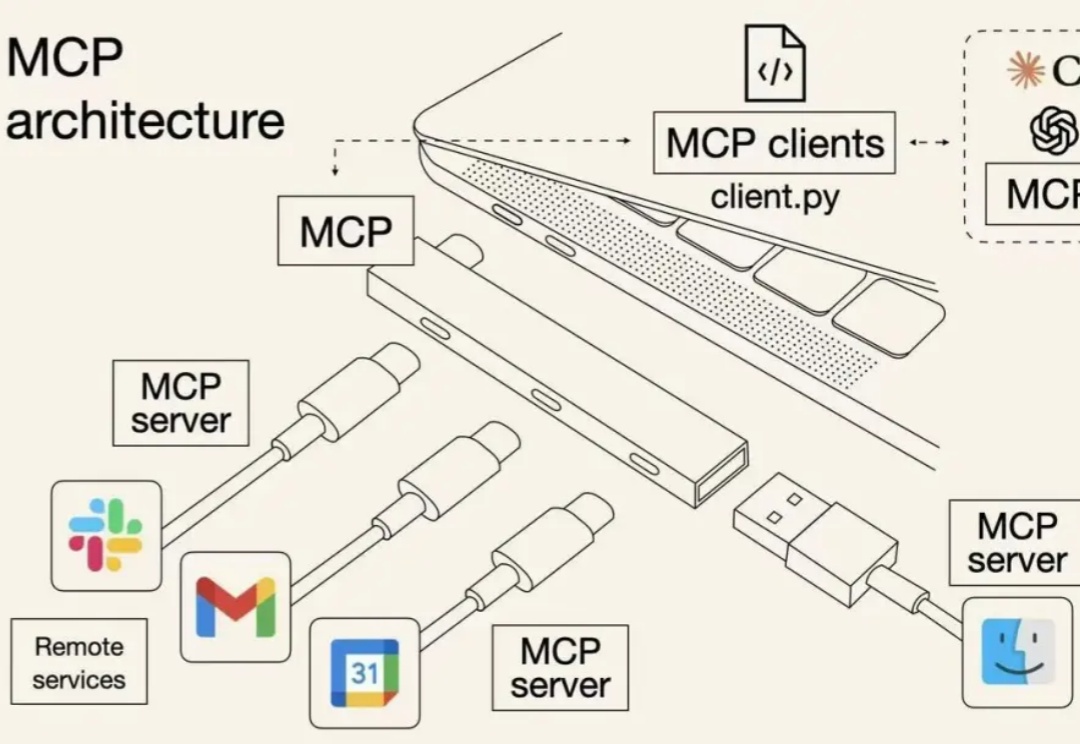
在拾象团队的 2025 的 AI 关键预测中,我们提到:随着 Agent 时代到来,OS 才是 LLM 厂商们最高的护城河,从 computer use 到 MCP,Anthropic 构建 OS 的决心是 AI labs 中最强、最明显的。

牛津大学教授新研究,未来AI的增长率足以在不到10年的时间里,推动相当于100年的技术进步。AI变革或将完全颠覆人类社会!
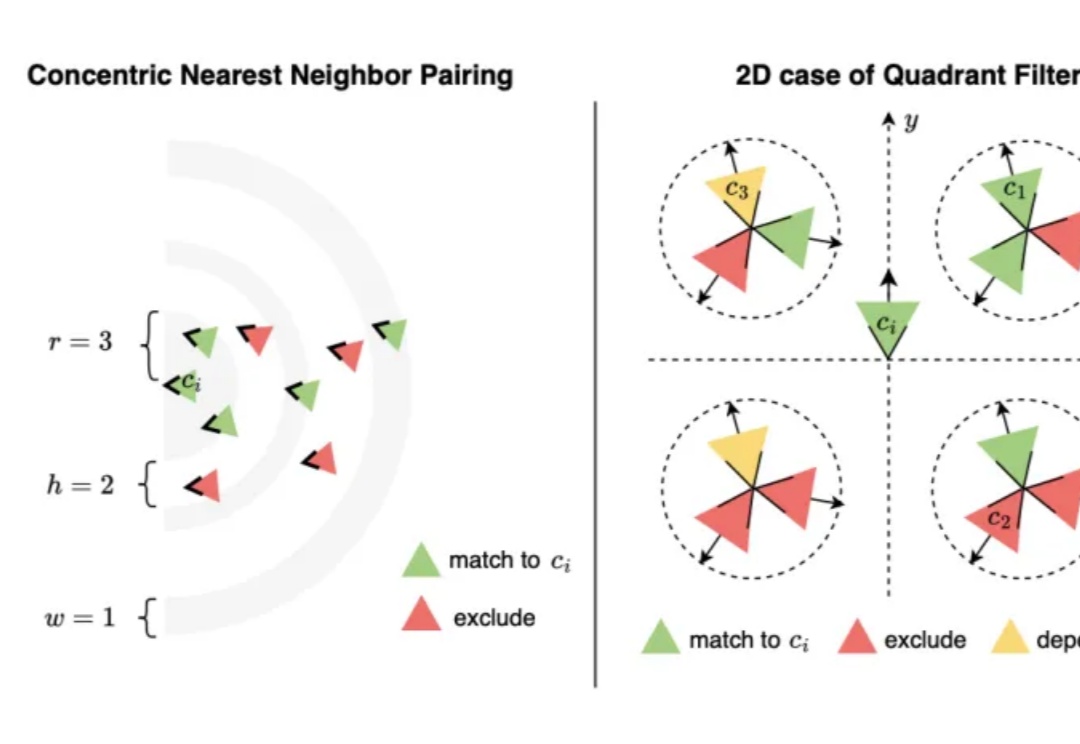
从手机随手拍、汽车行车记录仪到无人机航拍,如何从海量无序二维图像快速生成高精度三维场景?

如何让你的模型能感知到视频的粒度,随着你的心思想编辑哪就编辑哪呢?

它名为 Uni-3DAR,来自深势科技、北京科学智能研究院及北京大学,是一个通过自回归下一 token 预测任务将 3D 结构的生成与理解统一起来的框架。据了解,Uni-3DAR 是世界首个此类科学大模型。并且其作者阵容非常强大,包括了深势科技 AI 算法负责人柯国霖、中国科学院院士鄂维南、深势科技创始人兼首席科学家和北京科学智能研究院院长张林峰等。
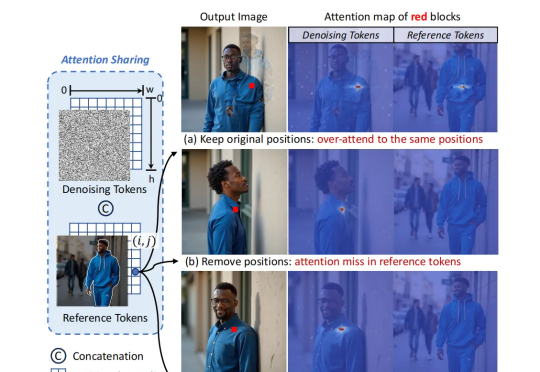
,清华大学、北京航空航天大学团队推出了全新的架构设计 ——Personalize Anything,它能够在无需训练的情况下,完成概念主体的高度细节还原,支持用户对物体进行细粒度的位置操控,并能够扩展至多个应用中,为个性化图像生成引入了一个新范式。

AI不但能写论文,还能自主进行科研协作,让智能体之间不再是「孤岛」。约翰霍普金斯与ETH Zurich联合推出了自主科研智能体框架AgentRxiv。该框架允许智能体相互上传和检索研究成果,自动积累与迭代已有进展,显著提高研究效率。

DeepSeek-R1掀起新一轮购卡潮的同时,AMD的含金量也上升了。

AI界「智商大考」ARC-AGI-2重磅出炉了!一个人类用5分钟轻松解开的谜题,却让最顶尖LLM全线崩盘得分挂零,o3更是从曾经76%暴跌至4%。它正式宣告,人类还未实现AGI。
在基于物理世界的真实场景进行视觉问答时,有可能出现参考选项中没有最佳答案的情况,比如以下例子:
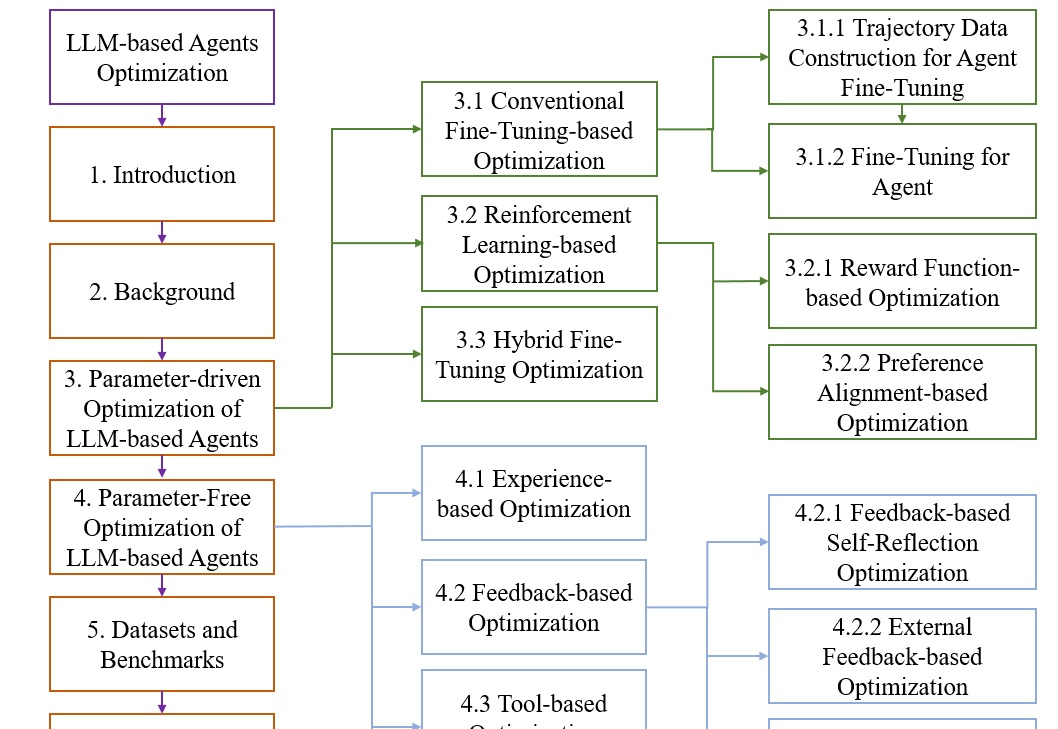
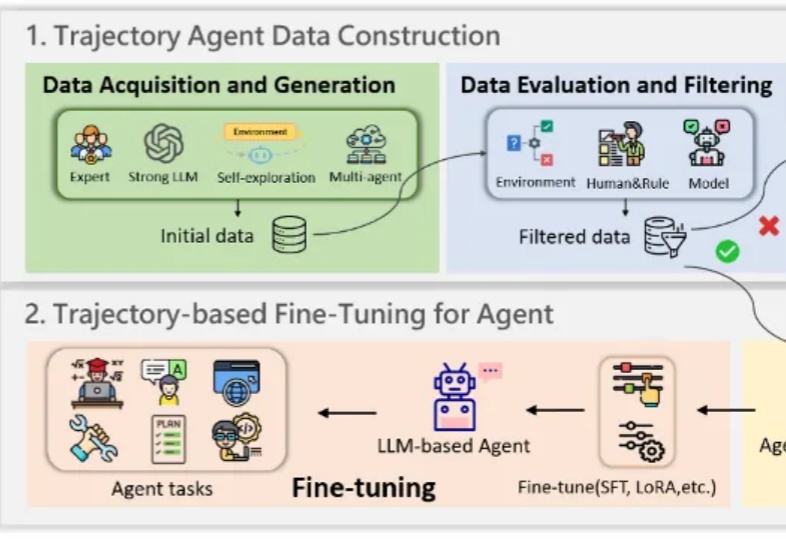
本文基于一项系统性研究《A Survey on the Optimization of Large Language Model-based Agents》,该研究由华东师大和东华大学多位人工智能领域的研究者共同完成。研究团队通过对大量相关文献的分析,构建了一个全面的LLM智能体优化框架,涵盖了从理论基础到实际应用的各个方面。您有兴趣可以找来读一下这篇综述。

从微观世界的分子与材料结构、到宏观世界的几何与空间智能,创建和理解 3D 结构是推进科学研究的重要基石。3D 结构不仅承载着丰富的物理与化学信息,也可为科学家提供解构复杂系统、进行模拟预测和跨学科创新的重要工具。
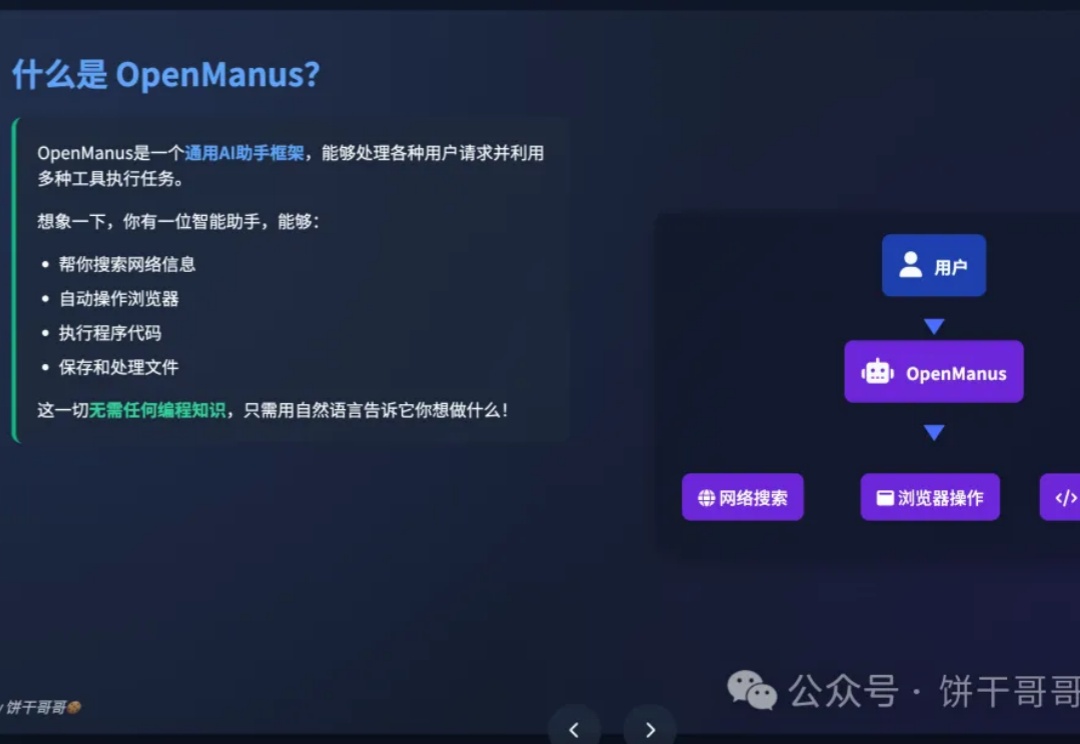
昨天我们介绍了什么是AI Agent,今天介绍一个开源的AI Agent框架,也是一号难求「Manus」的“平替”——OpenManus——曾经3小时完成Manus复刻的「神」
在引发全球关注的同时,全球资本对中国科技资产的重新评估与 AI 投资的底层逻辑也悄然发生转变。尤其是在大模型领域,过去巨额投入却屡次推迟的ChatGPT5和本就步入下半场的国内六小龙,将直面 DeepSeek这匹黑马的强劲冲击。中国AI企业在DeepSeek突破了“算力禁运”之后,正面临高质量数据稀缺的挑战,尤其是高质量、低成本、多种类、多模态的数据,将成为未来 AI 产业发展的核心关键。

个性化图像生成是图像生成领域的一项重要技术,正以前所未有的速度吸引着广泛关注。它能够根据用户提供的独特概念,精准合成定制化的视觉内容,满足日益增长的个性化需求,并同时支持对生成结果进行细粒度的语义控制与编辑,使其能够精确实现心中的创意愿景。
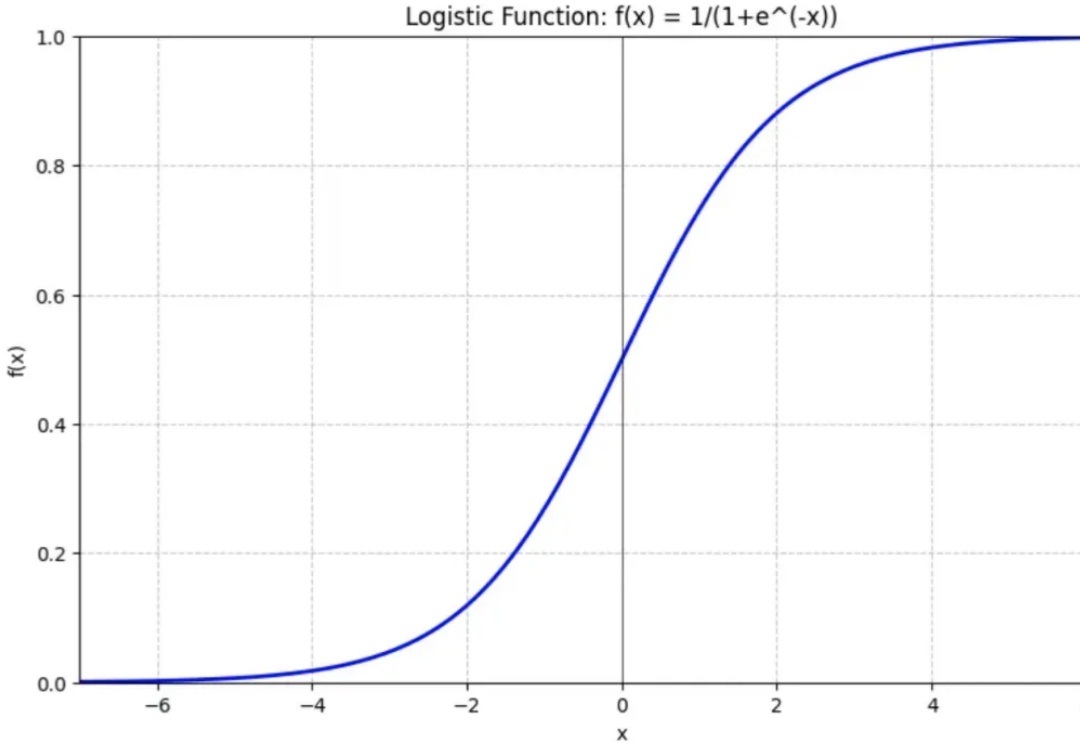
LLM本质上是一个基于概率输出的神经网络模型。但这里的“概率”来自哪里?今天我们就来说说语言模型中一个重要的角色:Softmax函数。(相信我,本文真的只需要初等函数知识)

685B的DeepSeek-V3新版本,就在昨夜悄悄上线了。参数量685B的V3,代码数学推理再次显著提升,甚至代码追平Claude 3.7,网友们实测后大呼强到离谱!有人预测说,按照此前的节奏,DeepSeek-R2大概率几周内就将上线。
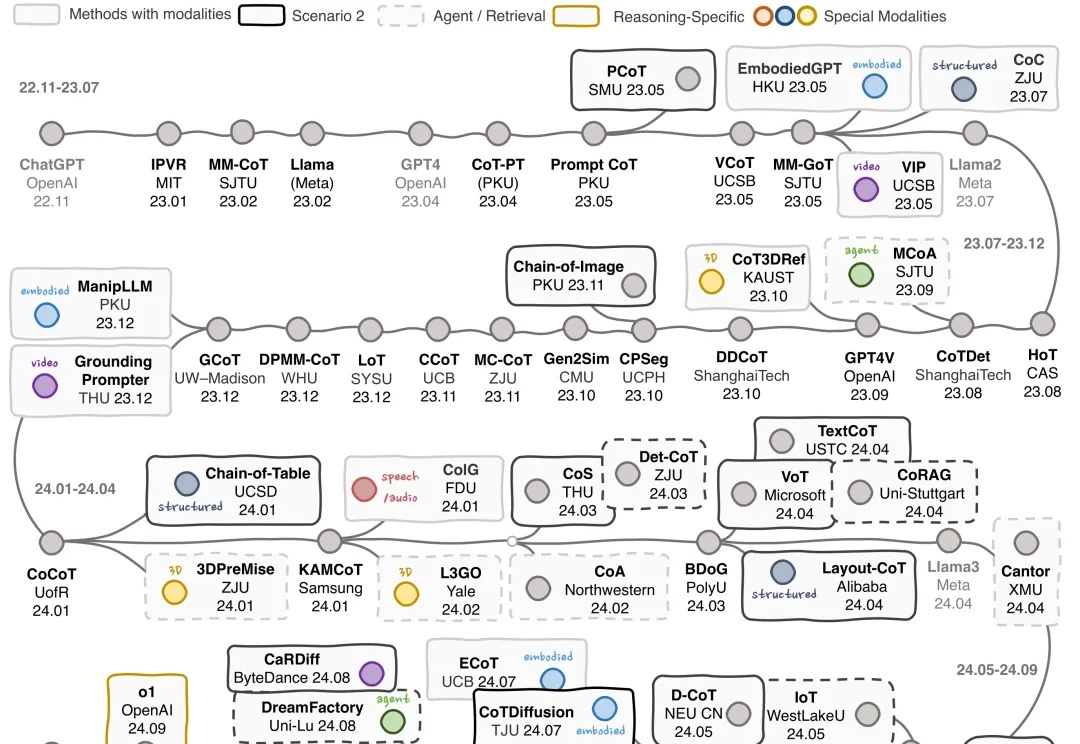
多模态思维链(MCoT)系统综述来了!

块离散去噪扩散语言模型(BD3-LMs)结合自回归模型和扩散模型的优势,解决了现有扩散模型生成长度受限、推理效率低和生成质量低的问题。通过块状扩散实现任意长度生成,利用键值缓存提升效率,并通过优化噪声调度降低训练方差,达到扩散模型中最高的预测准确性,同时生成效率和质量优于其他扩散模型。