
智源开源多模态向量模型BGE-VL:多模态检索新突破
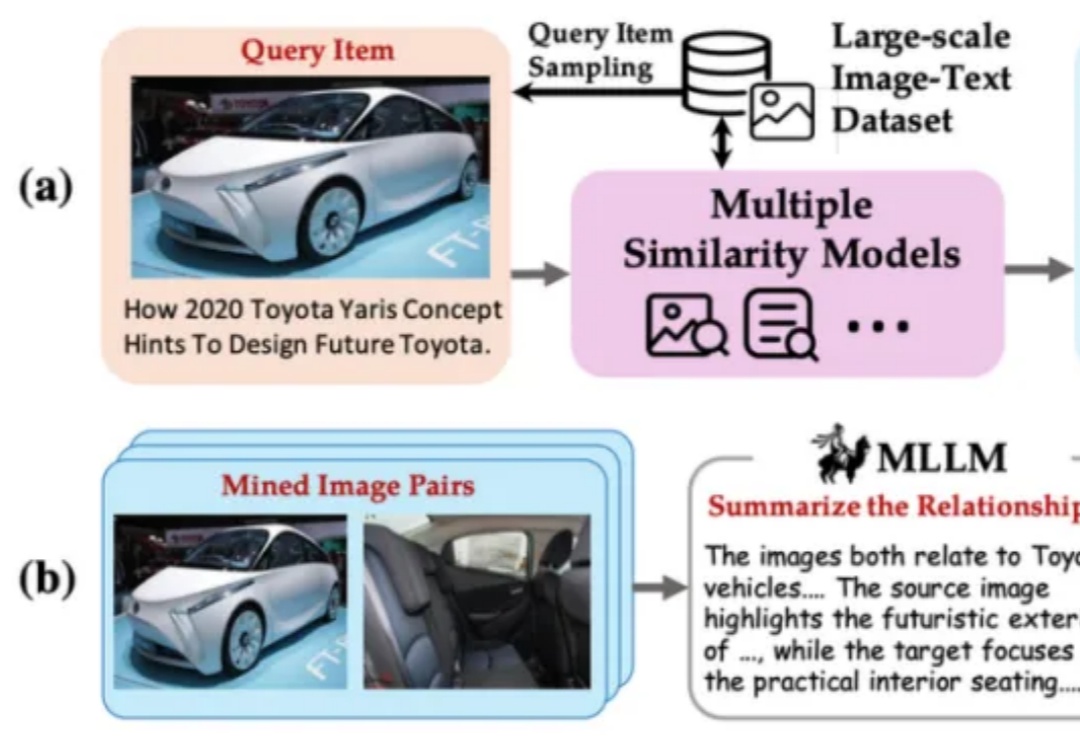
智源开源多模态向量模型BGE-VL:多模态检索新突破BGE 系列模型自发布以来广受社区好评。近日,智源研究院联合多所高校开发了多模态向量模型 BGE-VL,进一步扩充了原有生态体系。
来自主题: AI技术研报
7110 点击 2025-03-06 17:05
BGE 系列模型自发布以来广受社区好评。近日,智源研究院联合多所高校开发了多模态向量模型 BGE-VL,进一步扩充了原有生态体系。
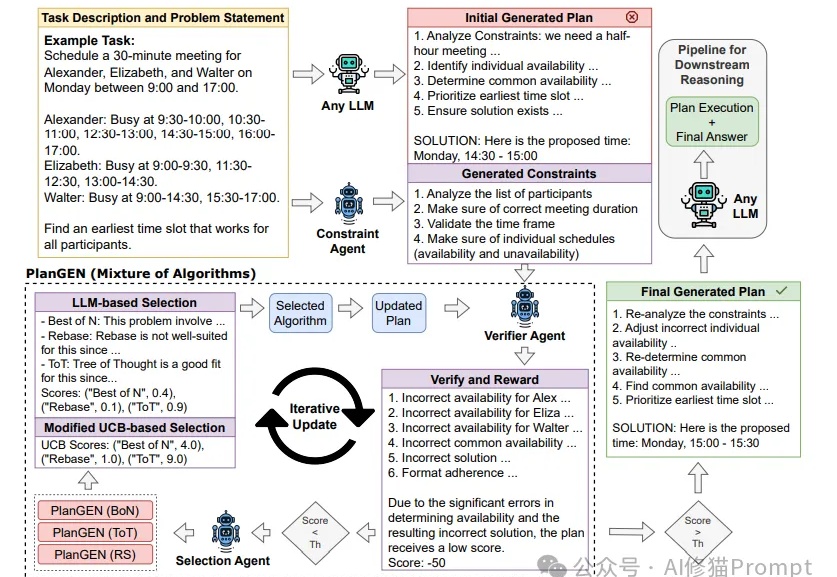
Agent这两天随着邀请码进入公众视野,展示了不凡的推理能力。然而,当面对需要精确规划和深度推理的复杂问题时,即使是最先进的LLMs也常常力不从心。Google研究团队提出的PlanGEN框架,正是为解决这一挑战而生。

本文提出了一种轨迹级别 SE (3) 等变的扩散策略(ET-SEED),通过将等变表示学习和扩散策略结合,使机器人能够在极少的示范数据下高效学习复杂操作技能,并能够泛化到不同物体姿态和环境中。
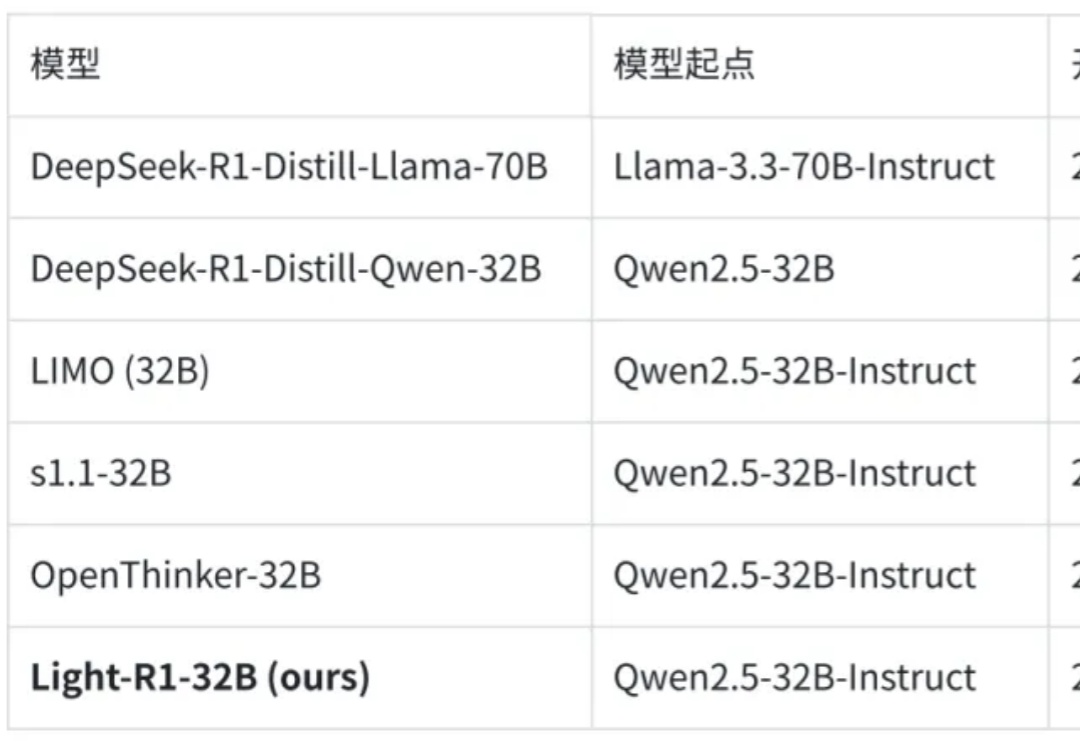
2025 年 3 月 4 日,360 智脑开源了 Light-R1-32B 模型,以及全部训练数据、代码。仅需 12 台 H800 上 6 小时即可训练完成,从没有长思维链的 Qwen2.5-32B-Instruct 出发,仅使用 7 万条数学数据训练,得到 Light-R1-32B

LLM一个突出的挑战是如何有效处理和理解长文本。就像下图所示,准确率会随着上下文长度显著下降,那么究竟应该怎样提升LLM对长文本理解的准确率呢?
回顾 AGI 的爆发,从最初的 pre-training (model/data) scaling,到 post-training (SFT/RLHF) scaling,再到 reasoning (RL) scaling,找到正确的 scaling 维度始终是问题的本质。

虽然 Qwen「天生」就会检查自己的答案并修正错误。但找到原理之后,我们也能让 Llama 学会自我改进。

增长是手段,但不是能解决一切问题的手段。因为只要你的网站还存在很多问题,那么增长就无法发挥最大的作用。增长是手段,而不是目的,最终是为具体的目的服务的,比如商业化。接下来现场嘉宾会讲一下商业化。所以按照第一性原理,你不是为了增长而增长,而是为了赚钱而增长,没有商业化的增长是一种负担。
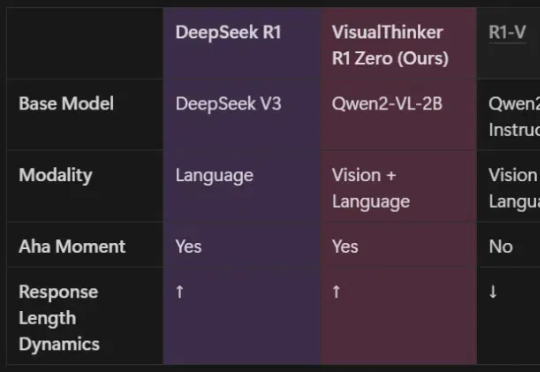
由UCLA等机构共同组建的研究团队,全球首次在20亿参数非SFT模型上,成功实现了多模态推理的DeepSeek-R1「啊哈时刻」!就在刚刚,我们在未经监督微调的2B模型上,见证了基于DeepSeek-R1-Zero方法的视觉推理「啊哈时刻」!

与3D物理环境交互、适应不同机器人形态并执行复杂任务的通用操作策略,一直是机器人领域的长期追求。
o1/DeepSeek-R1背后秘诀也能扩展到多模态了!
技术上,从传统的关键词检索,到RAG,大家已经不满足于只是生成对应的简单回答。而是期待大语言模型能够更好地应用于企业级场景,产生更大的价值。不久前,OpenAI推出了最新的深度内容生成神器“DeepResearch”,用户只需一个"特斯拉的合理市值是多少"的提问,
说真的,dify除了知识库以外,其他大部分功能体验都比fastgpt要好。而fastgpt的知识库效果是公认的好(以下是某群 群友的评价~)不过我想: 如果能把dify和fastgpt结合,且不妙哉?
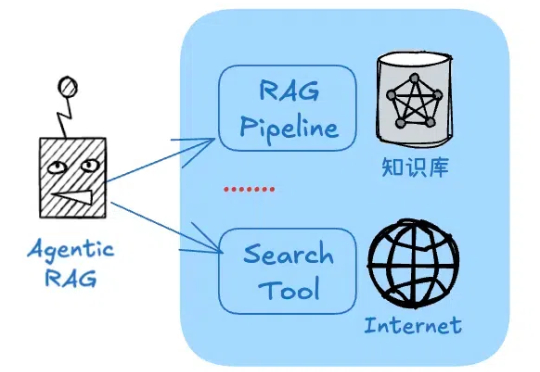
RAG是一种基于“检索结果”做推理的应用,这大大限制了类似DeepSeek-R1模型的发挥空间。但又的确存在将RAG的准确性与DeepSeek深度思考能力结合的场景,而不仅仅是回答事实性问题。比如:

DeepSeek R1 催化了 reasoning model 的竞争:在过去的一个月里,头部 AI labs 已经发布了三个 SOTA reasoning models:OpenAI 的 o3-mini 和deep research, xAI 的 Grok 3 和 Anthropic 的 Claude 3.7 Sonnet。
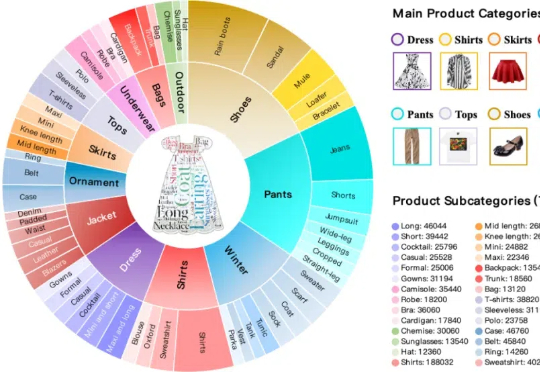
本文构建了新的多轮组合图像检索数据集和评测基准FashionMT。其特点包括:(1)回溯性:每轮修改文本可能涉及历史参考图像信息(如保留特定属性),要求算法回溯利用多轮历史信息;(2)多样化:FashionMT包含的电商图像数量和类别分别是MT FashionIQ的14倍和30倍,且交互轮次数量接近其27倍,提供了丰富的多模态检索场景。
满血版DeepSeek R1部署A100,基于INT8量化,相比BF16实现50%吞吐提升! 美团搜推机器学习团队最新开源,实现对DeepSeek R1模型基本无损的INT8精度量化。
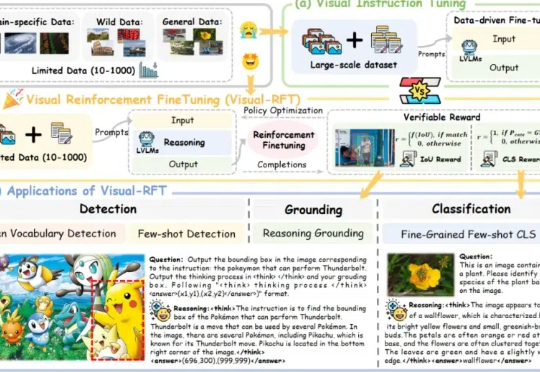
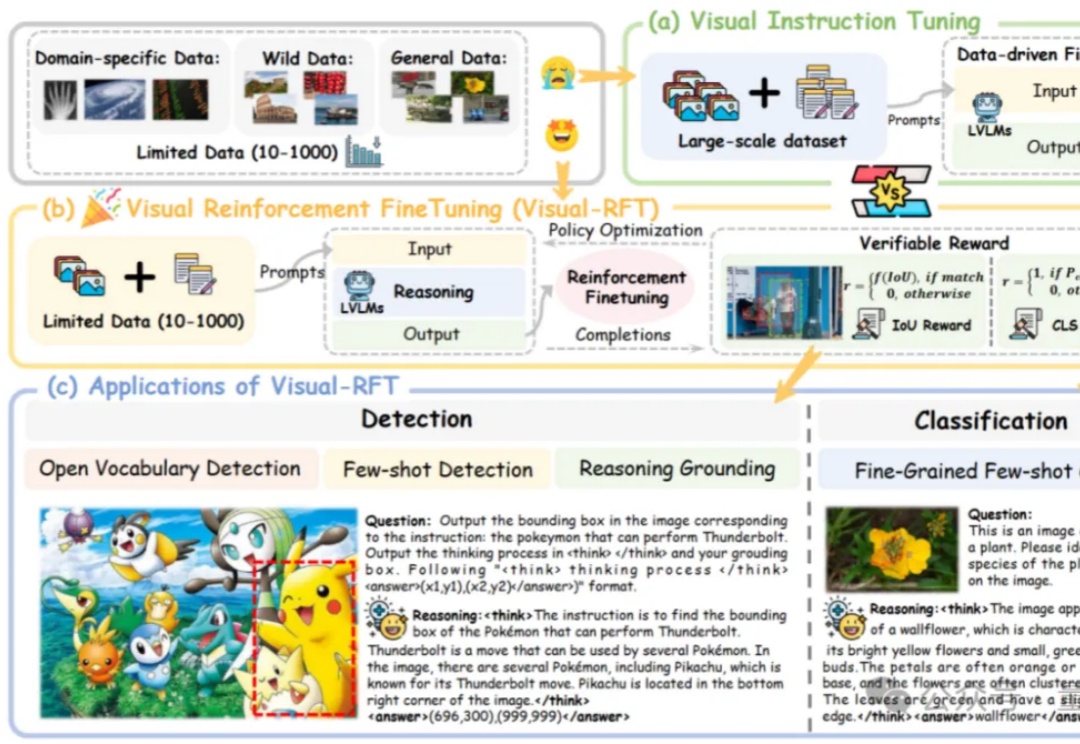
通过针对视觉的细分类、目标检测等任务设计对应的规则奖励,Visual-RFT 打破了 DeepSeek-R1 方法局限于文本、数学推理、代码等少数领域的认知,为视觉语言模型的训练开辟了全新路径!
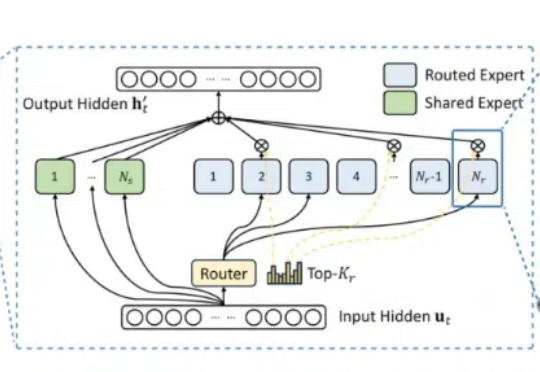
DeepSeek MoE“变体”来了,200美元以内,内存需求减少17.6-42%! 名叫CoE(Chain-of-Experts),被认为是一种“免费午餐”优化方法,突破了MoE并行独立处理token、整体参数数量较大需要大量内存资源的局限。
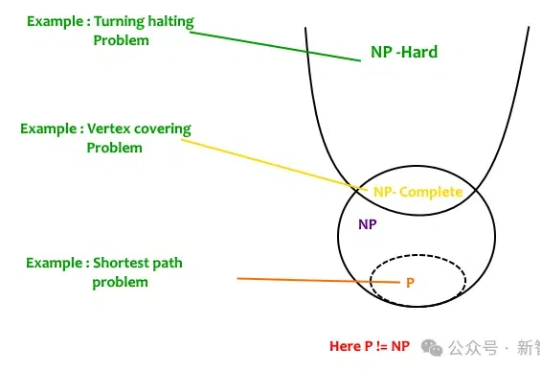
给DeepSeek-R1推理指导,它的数学推理能力就开始暴涨。更令人吃惊是,Qwen2.5-14B居然给出了此前从未见过的希尔伯特问题的反例!而人类为此耗费了27年。研究者预言:LLM离破解NP-hard问题,已经又近了一步。
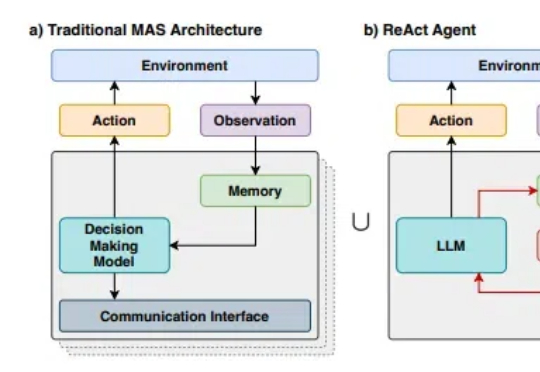
随着R1等先进推理模型展现出接近人类的推理能力,多代理系统(Multi-Agent Systems,MAS)的发展也出现了前所未有的机遇。然而,随着我们尝试构建越来越复杂的多代理系统,一个核心问题日益凸显:如何在保持系统灵活性的同时,降低开发和维护的复杂度?

要知道,过去几年,各种通用评测逐渐同质化,越来越难以评估模型真实能力。GPQA、MMLU-pro、MMLU等流行基准,各家模型出街时人手一份,但局限性也开始暴露,比如覆盖范围狭窄(通常不足 50 个学科),不含长尾知识;缺乏足够挑战性和区分度,比如 GPT-4o 在 MMLU-Pro 上准确率飙到 92.3%。

在 DeepSeek 生成的文本中,有 74.2% 的文本在风格上与 OpenAI 模型具有惊人的相似性?这是一项新研究得出的结论。这项研究来自 Copyleaks—— 一个专注于检测文本中的抄袭和 AI 生成内容的平台。
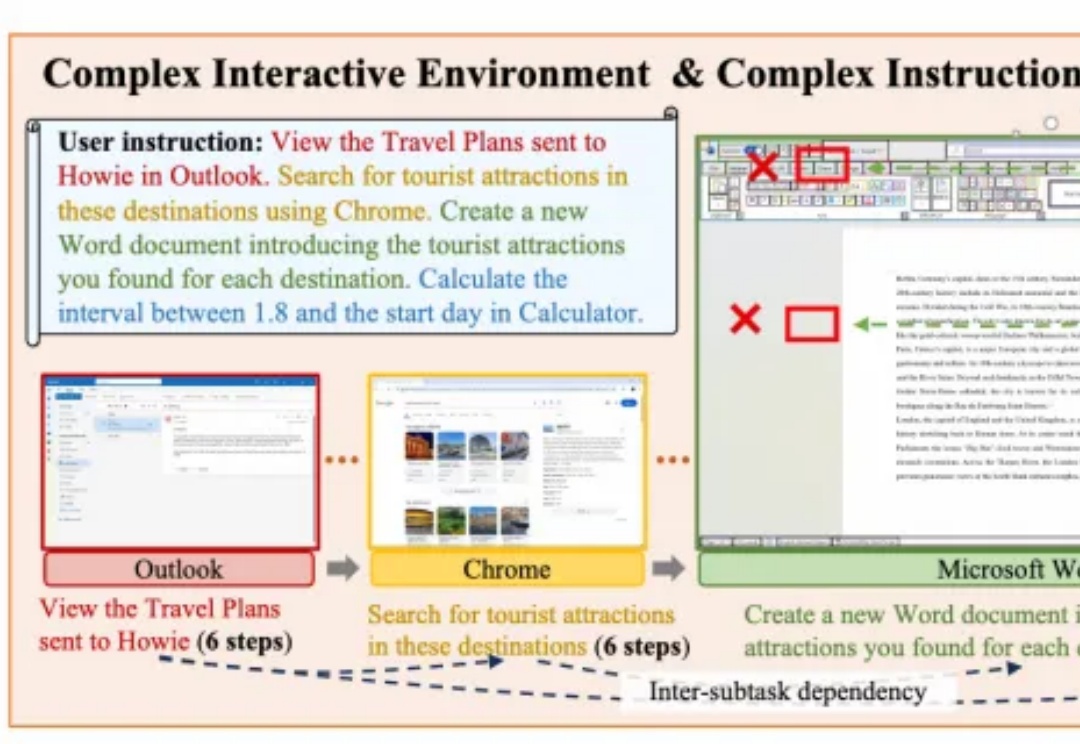
面向复杂PC任务的多模态智能体框架PC-Agent,来自阿里通义实验室。
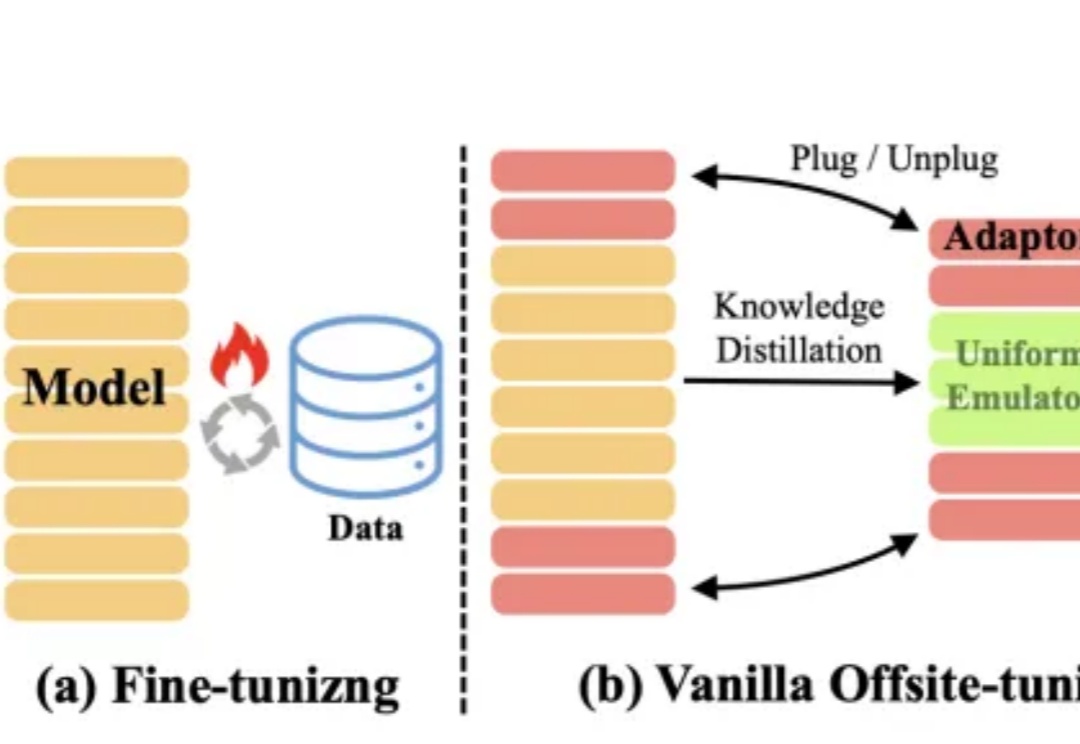
大模型的快速及持续发展,离不开对模型所有权及数据隐私的保护。
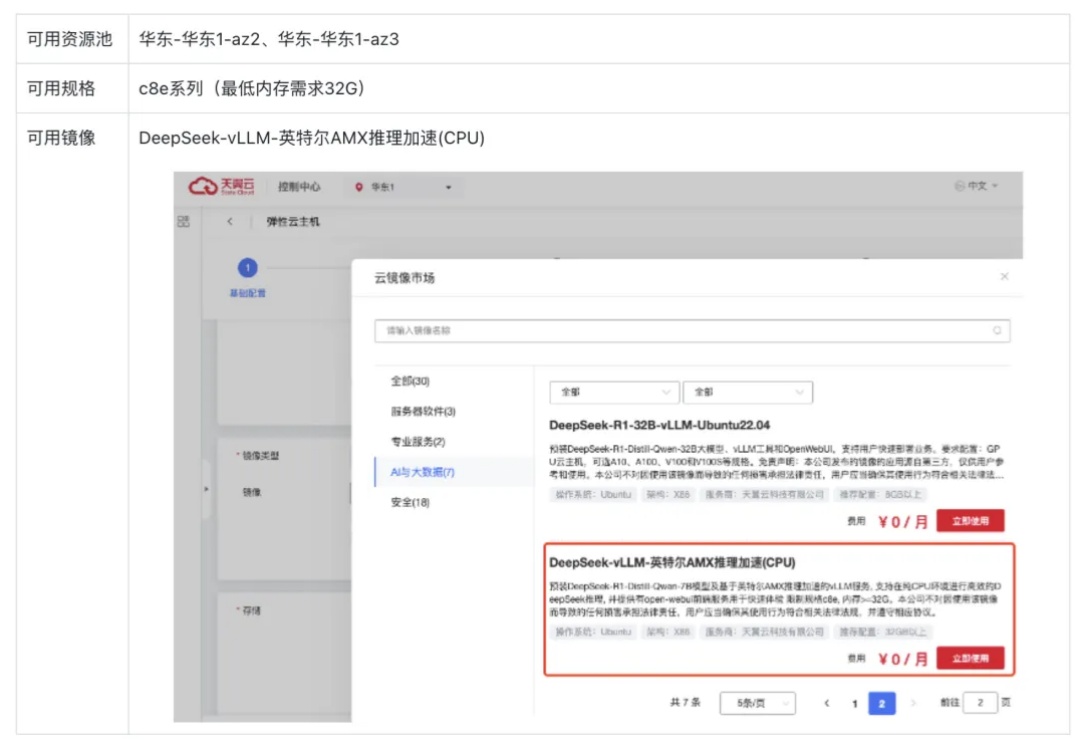
本文介绍了英特尔®至强®处理器在AI推理领域的优势,如何使用一键部署的镜像进行纯CPU环境下基于AMX加速后的DeepSeek-R1 7B蒸馏模型推理,以及纯CPU环境下部署DeepSeek-R1 671B满血版模型实践。
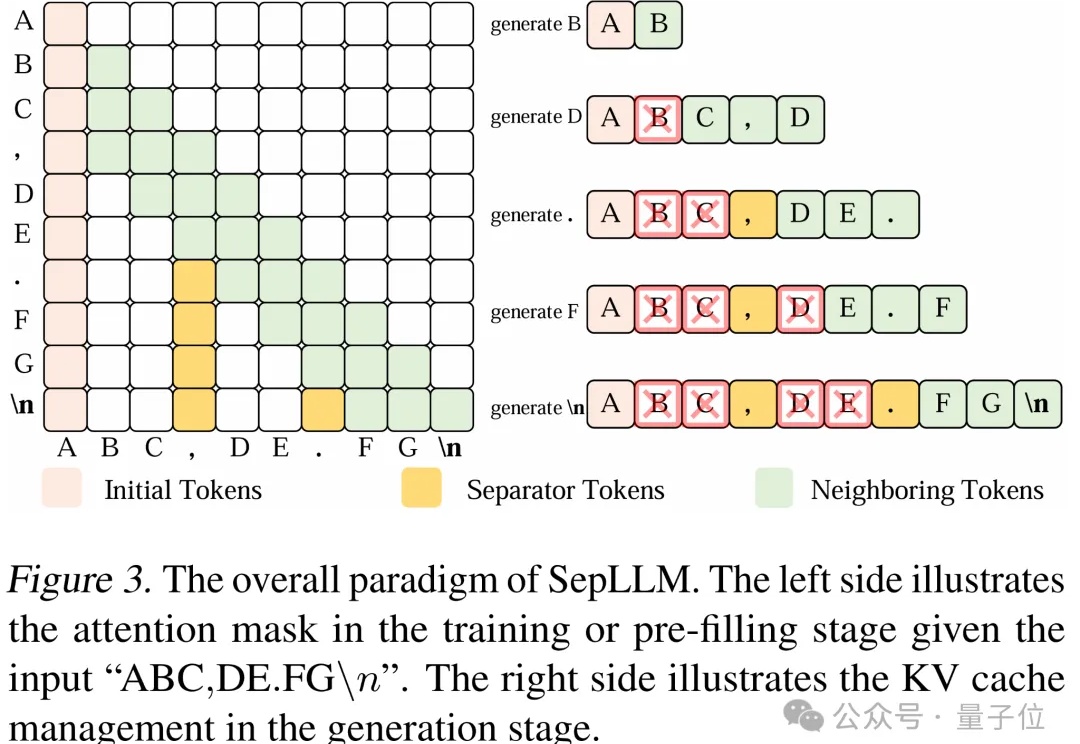
文字中貌似不起眼的标点符号,竟然可以显著加速大模型的训练和推理过程?

近年来大语言模型(LLM)的迅猛发展正推动人工智能迈向多模态融合的新纪元。然而,现有主流多模态大模型(MLLM)依赖复杂的外部视觉模块(如 CLIP 或扩散模型),导致系统臃肿、扩展受限,成为跨模态智能进化的核心瓶颈。

Hugging Face发布了「超大规模实战手册」,在512个GPU上进行超过4000个scaling实验。联创兼CEO Clement对此感到十分自豪。
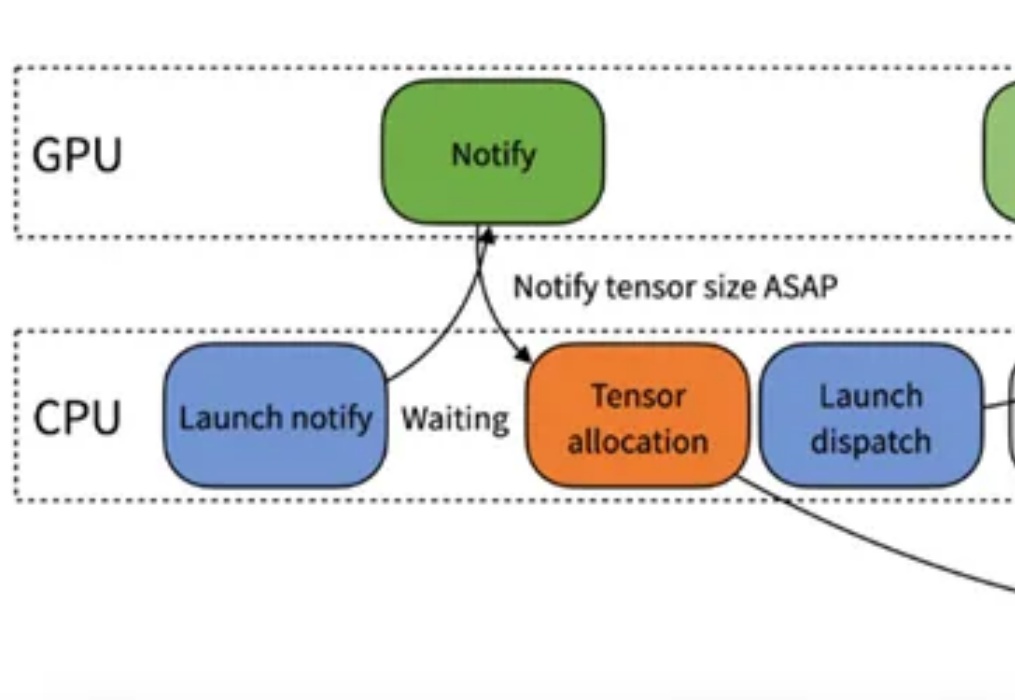
农历新年刚过,DeepSeek卷王依旧,这次一下子进行了接连六天的开源Week。