Web Agent技术揭秘:如何让DeepSeek接管与控制你的浏览器?
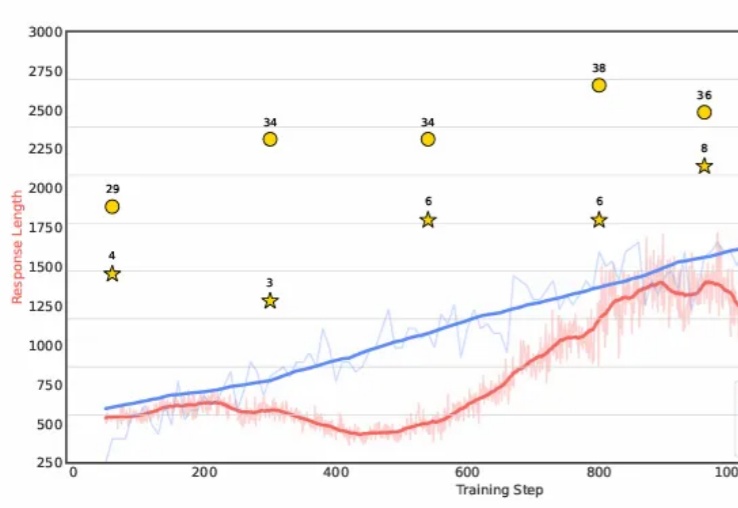
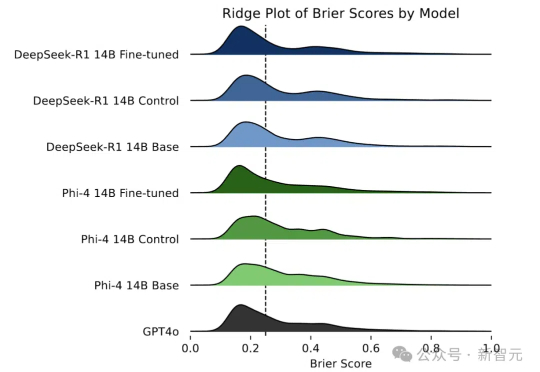
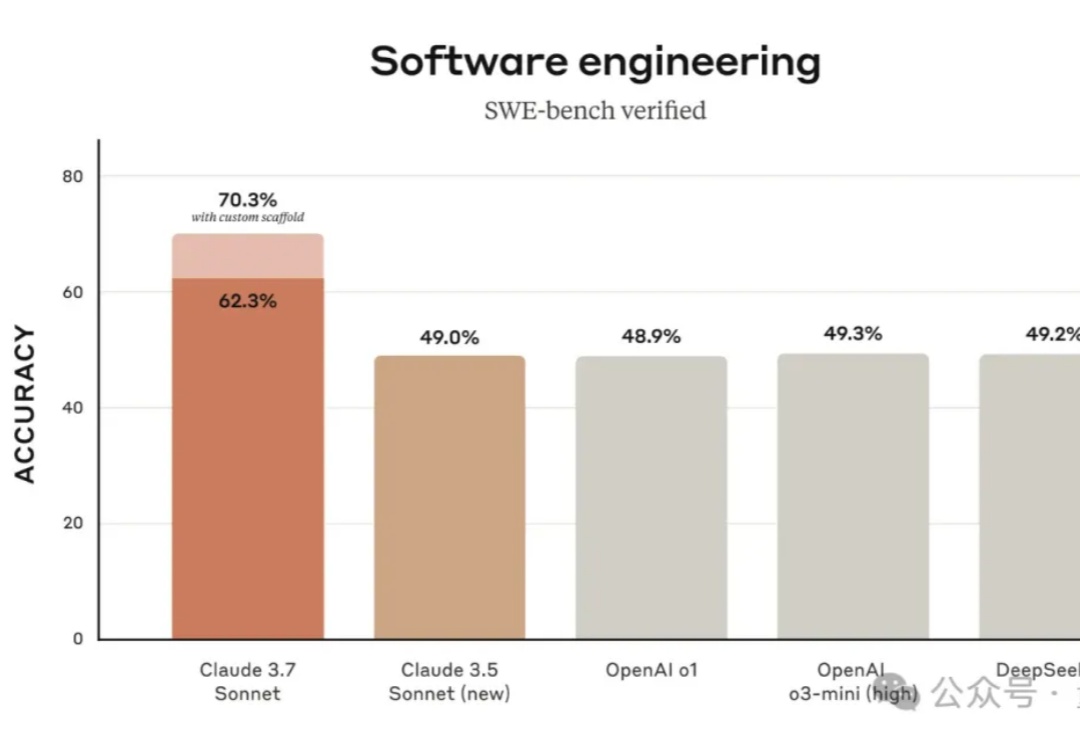
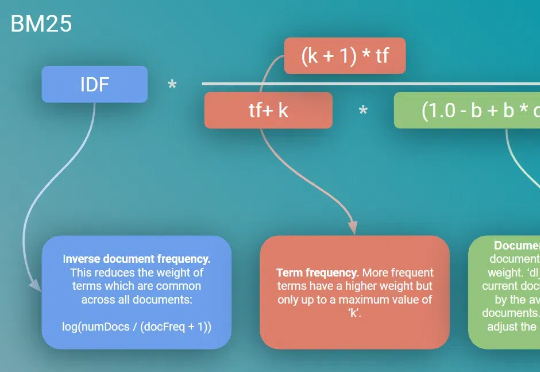
Web Agent技术揭秘:如何让DeepSeek接管与控制你的浏览器?Web Agent是这样一种特殊的智能体:它借助AI自动控制你的浏览器,并完成你“交代”的任务。比如帮你挑选一部最新的iPhone或者到旅行网站预订机票。这样的智能数字助手,无论是对生活还是工作,未来无疑都具有重大的意义。当前有大量的研究正针对这种Agent展开,本文就来聊聊其最新进展及DeepSeek的应用。
来自主题: AI技术研报
6868 点击 2025-02-27 10:51