

超越DeepSeek推理,效率更高!斯坦福马腾宇新作:有限数据,无限迭代
超越DeepSeek推理,效率更高!斯坦福马腾宇新作:有限数据,无限迭代STP(自博弈定理证明器)让模型扮演「猜想者」和「证明者」,互相提供训练信号,在有限的数据下实现了无限自我改进,在Lean和Isabelle验证器上的表现显著优于现有方法,证明成功率翻倍,并在多个基准测试中达到最先进的性能。
来自主题: AI技术研报
3857 点击 2025-02-28 15:21
STP(自博弈定理证明器)让模型扮演「猜想者」和「证明者」,互相提供训练信号,在有限的数据下实现了无限自我改进,在Lean和Isabelle验证器上的表现显著优于现有方法,证明成功率翻倍,并在多个基准测试中达到最先进的性能。

DeepSeek最后一天,送上了3FS文件并行系统,以及数据处理框架Smallpond。五天开源连更,终于画上了完美的句号。
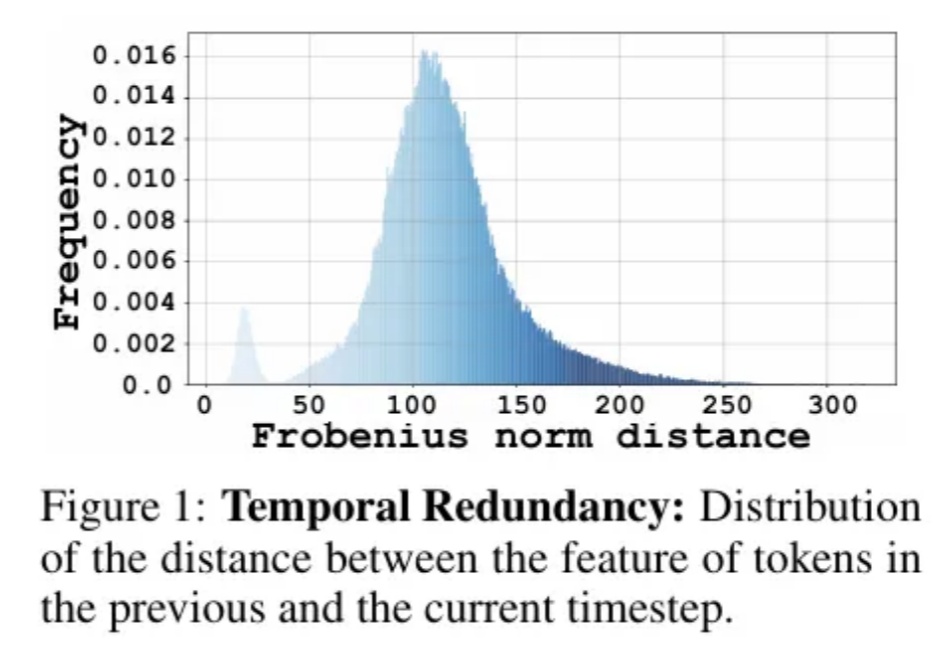
Diffusion Transformer模型模型通过token粒度的缓存方法,实现了图像和视频生成模型上无需训练的两倍以上的加速。

随着 AI 能力的提升,一个常见的话题便是基准不够用了——一个新出现的基准用不了多久时间就会饱和,比如 Replit CEO Amjad Masad 就预计 2023 年 10 月提出的编程基准 SWE-bench 将在 2027 年饱和。
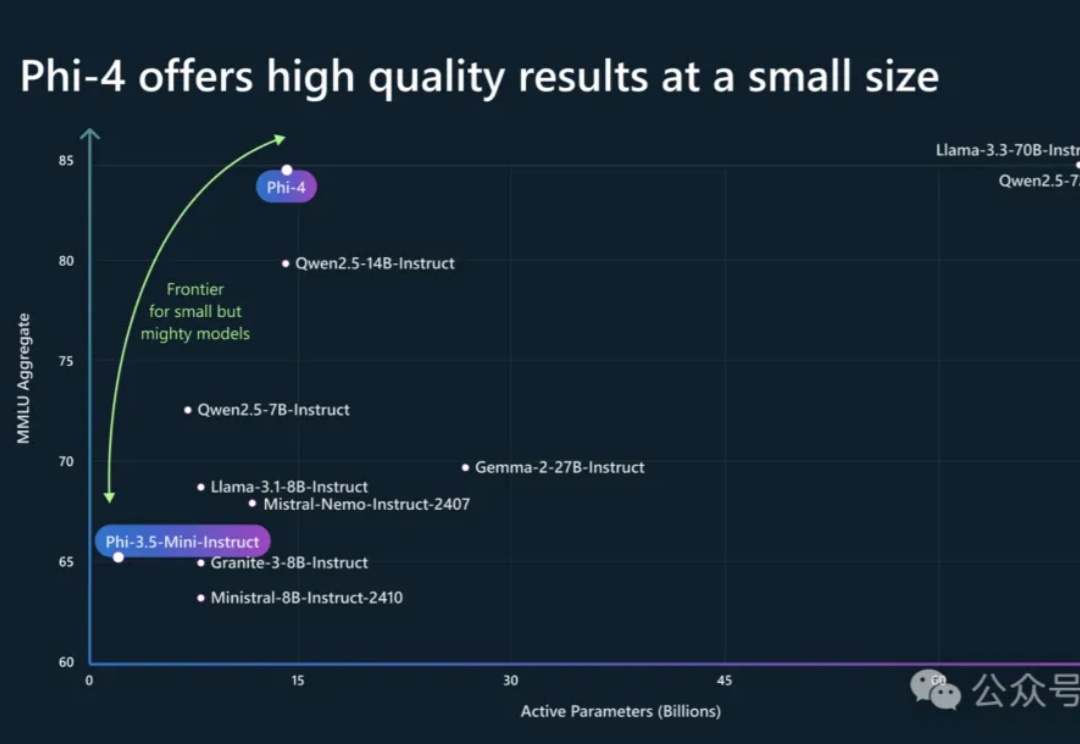
Phi-4系列模型上新了!56亿参数Phi-4-multimodal集语音、视觉、文本多模态于一体,读图推理性能碾压GPT-4o;另一款38亿参数Phi-4-mini在推理、数学、编程等任务中超越了参数更大的LLM,支持128K token上下文。
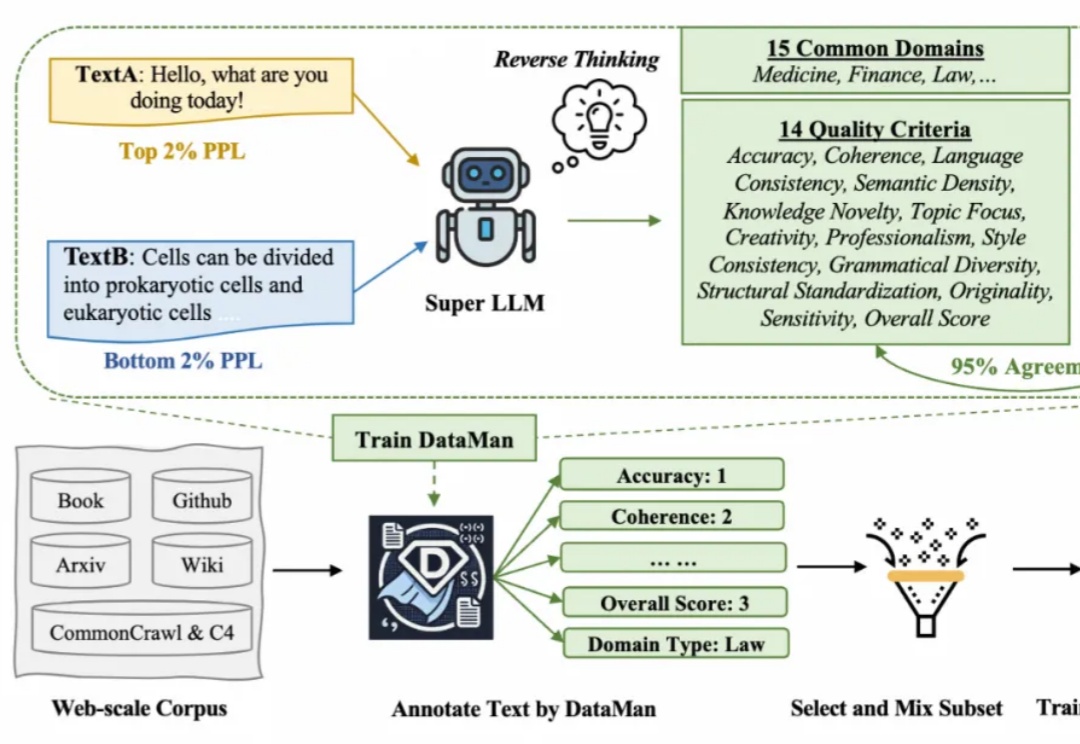
在 Scaling Law 背景下,预训练的数据选择变得越来越重要。然而现有的方法依赖于有限的启发式和人类的直觉,缺乏全面和明确的指导方针。在此背景下,该研究提出了一个数据管理器 DataMan,其可以从 14 个质量评估维度对 15 个常见应用领域的预训练数据进行全面质量评分和领域识别。

DeepSeek开源周的最后一天,迎来的是支撑其V3/R1模型全生命周期数据访问需求的核心基础设施 — Fire-Flyer File System(3FS) 和构建于其上的Smallpond数据处理框架。

单个模型的优缺点也能分析
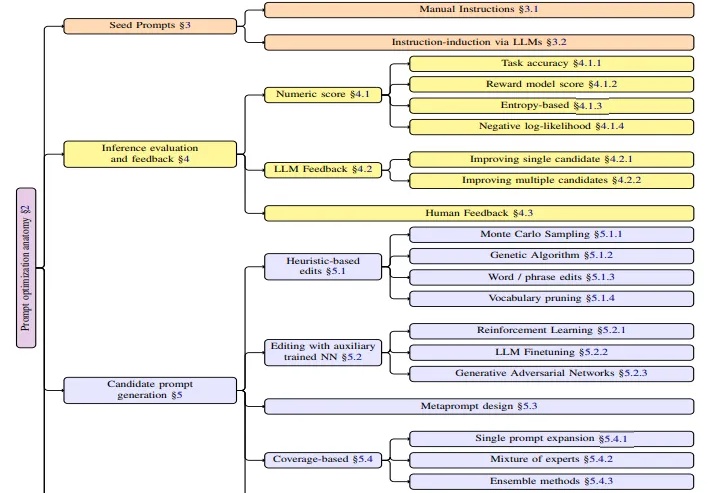
本文是对亚马逊AWS研究团队最新发表的APO(自动提示词优化)技术综述的深度解读。该研究由Kiran Ramnath、Kang Zhou等21位来自AWS的资深研究者共同完成,团队成员来自不同技术背景,涵盖了机器学习、自然语言处理、系统优化等多个专业领域。

这是智能体平台扣子官方整理的AI应用的相关数据,该报告可以让大家更好的了解用户在智能体方面的创建情况,同时也可以了解智能体平台本身的用户情况,更清楚的分析智能体商业的前景。
动辄百亿、千亿参数的大模型正在一路狂奔,但「小而美」的模型也在闪闪发光。

最近,英伟达开源了首个在Blackwell架构上优化的DeepSeek-R1,实现了推理速度提升25倍,和每token成本降低20倍的惊人成果。同时,DeepSeek连续开源多个英伟达GPU优化项目,共同探索模型性能极限。

斯坦福和普林斯顿研究者发现,DeepSeek-R1生成的自定义CUDA内核,完爆了o1和Claude 3.5 Sonnet,拿下总排名第一。虽然目前只能在不到20%任务上超越PyTorch Eager基线,但GPU编程加速自动化的按钮,已经被按下!

哈尔滨工业大学团队提出HEROS-GAN技术,通过生成式深度学习将低成本加速度计信号转化为高精度信号,突破其精度与量程瓶颈。该技术利用最优传输监督和拉普拉斯能量调制,使0.5美元的传感器达到200美元高端设备的性能,为工业、医疗等领域应用带来变革。

AI引用正确率仅有4.2- 18.5%,用Deep Research就提高了引用正确率吗?似乎用Think&Cite框架的SG-MCTS和过程奖励机制PRM可以解决引用问题,生成可信内容。

当前的 AI 领域,可以说 Transformer 与扩散模型是最热门的模型架构。也因此,有不少研究团队都在尝试将这两种架构融合到一起,以两者之长探索新一代的模型范式,比如我们之前报道过的 LLaDA。不过,之前这些成果都还只是研究探索,并未真正实现大规模应用。
第四天,DeepSee发布包括三个主要项目: DualPipe- 一种用于 V3/R1 训练的双向流水线并行算法,实现计算和通信完全重叠; EPLB(Expert Parallelism Load Balancer) - 专为 V3/R1 设计的专家并行负载均衡器; Profile-data- 分析 V3/R1 中计算与通信重叠的性能数据集。

按时整活!DeepSeek开源周第四天,直接痛快「1日3连发」,且全都围绕一个主题:优化并行策略。
Web Agent是这样一种特殊的智能体:它借助AI自动控制你的浏览器,并完成你“交代”的任务。比如帮你挑选一部最新的iPhone或者到旅行网站预订机票。这样的智能数字助手,无论是对生活还是工作,未来无疑都具有重大的意义。当前有大量的研究正针对这种Agent展开,本文就来聊聊其最新进展及DeepSeek的应用。

近日,上海 AI Lab 具身智能中心研究团队在机器人控制领域取得了最新突破,提出的 HoST(Humanoid Standing-up Control)算法,成功让人形机器人在多种复杂环境中实现了自主站起,并展现出强大的抗干扰能力。

在实际应用中,我们常常需要模型输出具有严格结构的数据,比如生物制药生产记录、金融交易报告或医疗健康档案等。这种结构化输出的需求在生物制造、金融服务、医疗健康等严格监管的领域尤为重要。
现在截图生成代码,已经来到了一个新高度——

大自然的分形之美,蕴藏着宇宙的设计规则。刚刚,何恺明团队祭出「分形生成模型」,首次实现高分辨率逐像素建模,让计算效率飙升4000倍,开辟AI图像生成新范式。
相信很多用户已经见识过或至少听说过 Deep Research 的强大能力。
Zep,一个为大模型智能体提供长期记忆的插件,能将智能体的记忆组织成情节,从这些情节中提取实体及其关系,并将它们存储在知识图谱中,从而让用户以低代码的方式为智能力构建长期记忆。
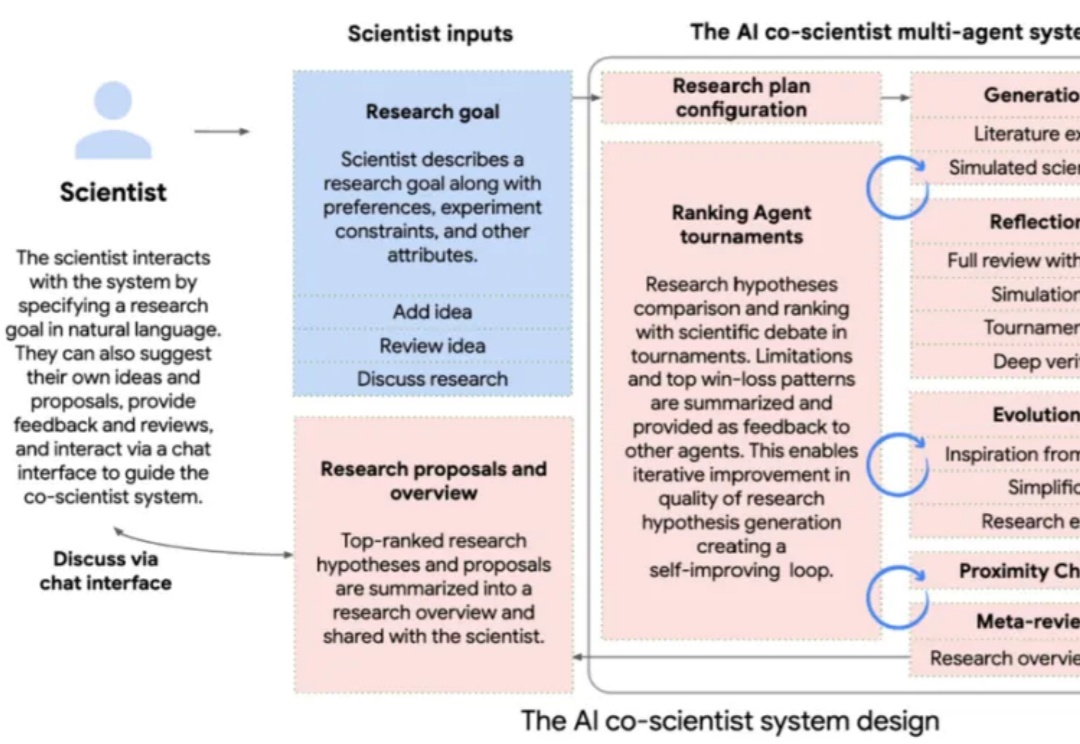
AI co-scientist系统基于Gemini 2.0开发,能够协助科研人员生成新的研究假设、制定实验方案,并通过自我改进提升结果质量。在生物医学应用中,AI co-scientist成功预测了药物再利用方向、提出新的治疗靶点,并解释了抗菌耐药机制。
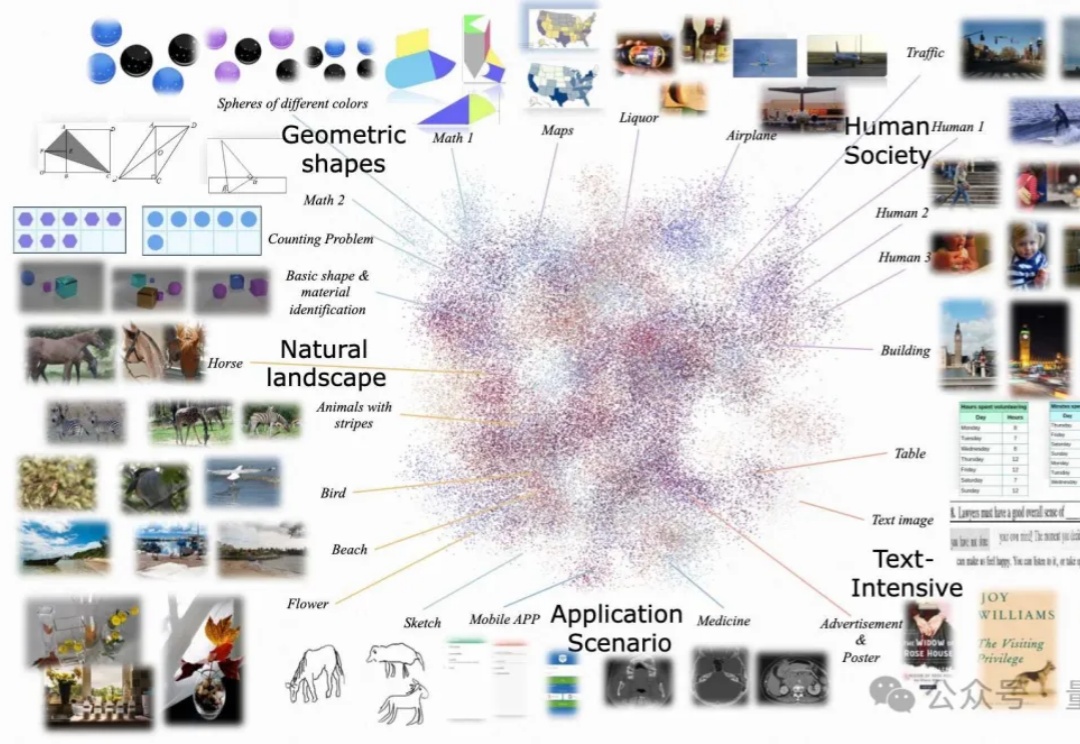
尽管多模态大语言模型(MLLMs)取得了显著的进展,但现有的先进模型仍然缺乏与人类偏好的充分对齐。这一差距的存在主要是因为现有的对齐研究多集中于某些特定领域(例如减少幻觉问题),是否与人类偏好对齐可以全面提升MLLM的各种能力仍是一个未知数。

进入到 2025 年,视频生成(尤其是基于扩散模型)领域还在不断地「推陈出新」,各种文生视频、图生视频模型展现出了酷炫的效果。其中,长视频生成一直是现有视频扩散的痛点。
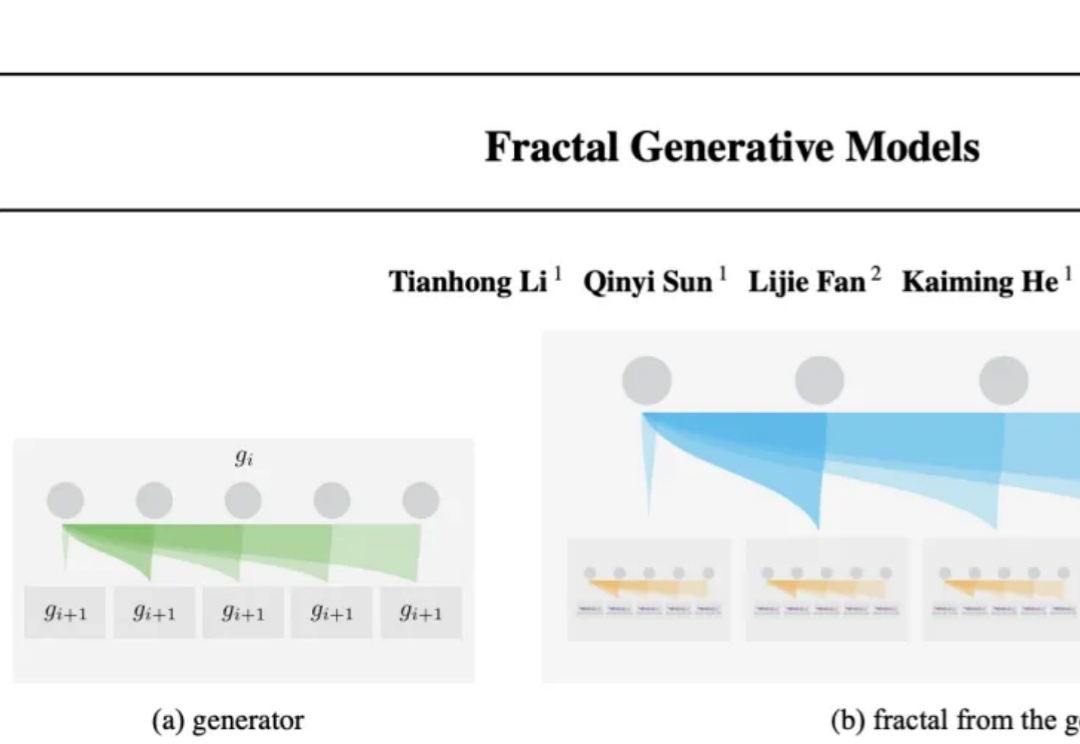
何恺明再次开宗立派!开辟了生成模型的全新范式——
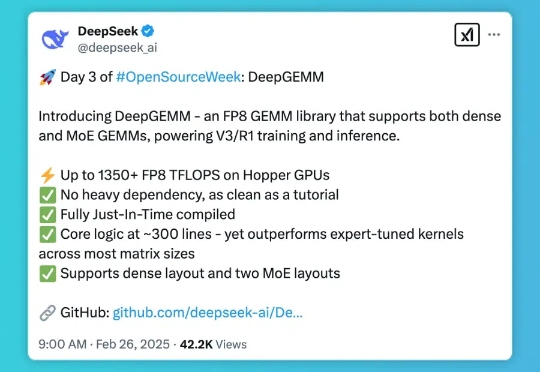
DeepSeek 开源周的第三天,带来了专为 Hopper 架构 GPU 优化的矩阵乘法库 — DeepGEMM。这一库支持标准矩阵计算和混合专家模型(MoE)计算,为 DeepSeek-V3/R1 的训练和推理提供强大支持,在 Hopper GPU 上达到 1350+FP8 TFLOPS 的高性能。