

打脸!GPT-4o输出长度8k都勉强,陈丹琦团队新基准测试:所有模型输出都低于标称长度
打脸!GPT-4o输出长度8k都勉强,陈丹琦团队新基准测试:所有模型输出都低于标称长度很多大模型的官方参数都声称自己可以输出长达32K tokens的内容,但这数字实际上是存在水分的??
来自主题: AI技术研报
9276 点击 2025-01-16 10:30
很多大模型的官方参数都声称自己可以输出长达32K tokens的内容,但这数字实际上是存在水分的??

Sakana AI发布了Transformer²新方法,通过奇异值微调和权重自适应策略,提高了LLM的泛化和自适应能力。新方法在文本任务上优于LoRA;即便是从未见过的任务,比如MATH、HumanEval和ARC-Challenge等,性能也都取得了提升。

Stability AI推出3D重建方法:2D图像秒变3D,还可以交互式实时编辑。新方法的原理、代码、权重、数据全公开,而且许可证宽松,可以商用。新方法采用点扩展模型生成稀疏点云,之后通过Transformer主干网络,同时处理生成的点云数据和输入图像生成网格。以后,人人都能轻松上手3D模型设计。

近期,OpenAI CEO Sam Altman 宣布,2025 年将推出名为 “Operator” 的虚拟员工计划,AI 代理将能够自主执行任务,如写代码、预订旅行等,成为企业中的 “数字同事”。

正如论文一作所说,「新架构 Titans 既比 Transformer 和现代线性 RNN 更有效,也比 GPT-4 等超大型模型性能更强。」
自适应 LLM 反映了神经科学和计算生物学中一个公认的原理,即大脑根据当前任务激活特定区域,并动态重组其功能网络以响应不断变化的任务需求。

开源模型上下文窗口卷到超长,达400万token! 刚刚,“大模型六小强”之一MiniMax开源最新模型—— MiniMax-01系列,包含两个模型:基础语言模型MiniMax-Text-01、视觉多模态模型MiniMax-VL-01。
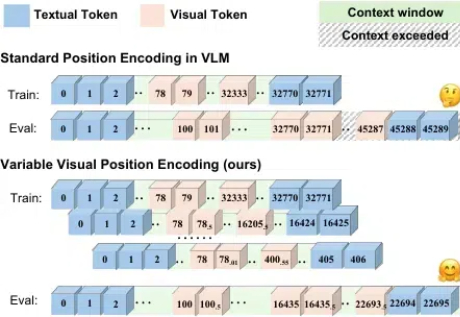
随着语言大模型的成功,视觉 - 语言多模态大模型 (Vision-Language Multimodal Models, 简写为 VLMs) 发展迅速,但在长上下文场景下表现却不尽如人意,这一问题严重制约了多模态模型在实际应用中的潜力。
「2025 年,我们可能会看到第一批 AI Agent 加入劳动力大军,并对公司的生产力产生实质性的影响。」——OpenAI CEO Sam Altman
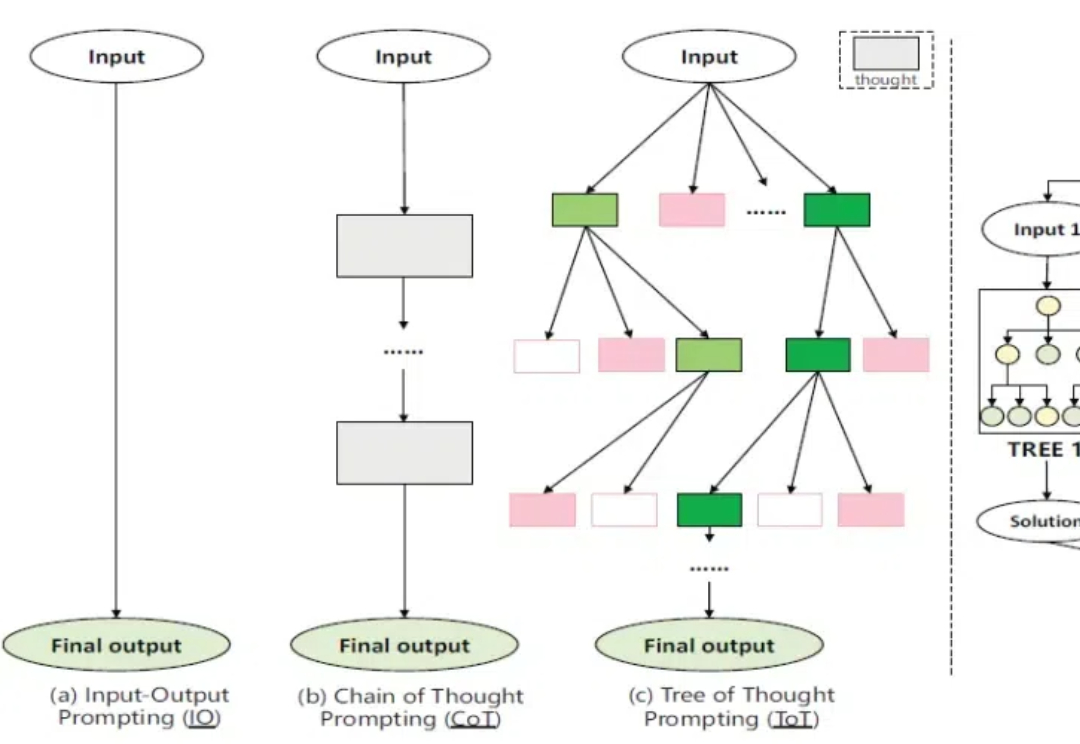
在人工智能快速发展的今天,提示工程(Prompt Engineering)已经成为AI应用开发中不可或缺的环节。然而,当我们需要生成适应不同场景的情感文本时,传统的单一目标提示优化方法往往显得力不从心。

在机器学习和数据科学领域,余弦相似度长期以来一直是衡量高维对象之间语义相似度的首选指标。余弦相似度已广泛应用于从推荐系统到自然语言处理的各种应用中。它的流行源于人们相信它捕获了嵌入向量之间的方向对齐,提供了比简单点积更有意义的相似性度量。
OpenAI 接连发布 o1 和 o3 模型,大模型的高阶推理能力正在迎来爆发式增强。在预训练 Scaling law “撞墙” 的背景下,探寻新的 Scaling law 成为业界关注的热点。高阶推理能力有望开启新的 Scaling law,为大模型的发展注入新的活力。
AC3D 从基本原理出发,分析了摄像机运动在视频生成中的特点,并通过以下三方面改进了视频生成的效果和效率:
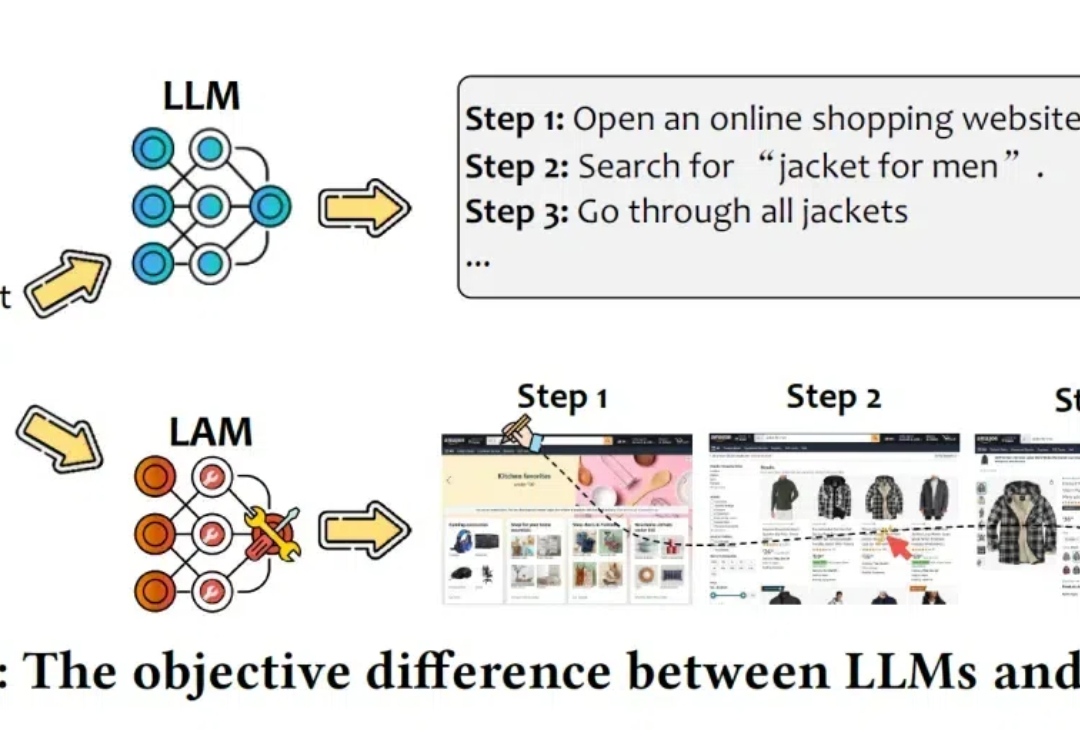
AI大模型正从仅会聊天的LLM进化为能够执行任务的大型行动模型LAM。它不仅能理解用户的指令,还能在软件环境中自主执行任务。
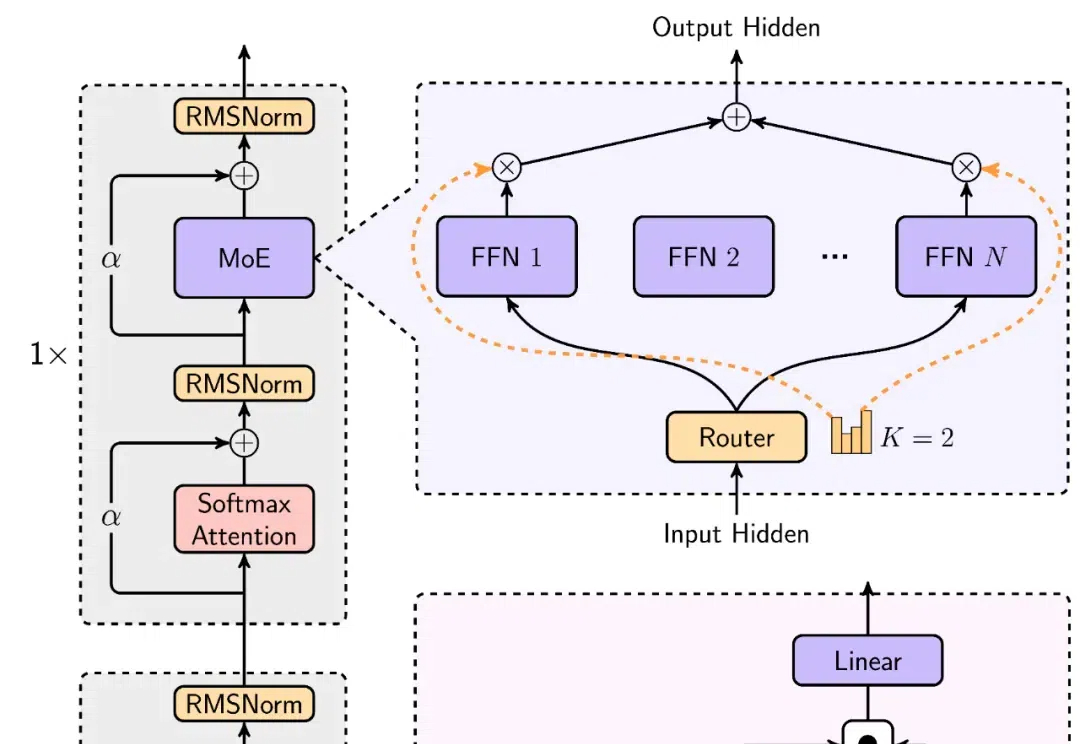
想挑战 Transformer 的新架构有很多,来自谷歌的“正统”继承者 Titan 架构更受关注。

谷歌推出的FACTS Grounding基准测试,能评估AI模型在特定上下文中生成准确文本的能力,有助于提升模型的可靠性;通过去除不满足用户需求的回复,确保了评分的准确性和模型排名的公正性。
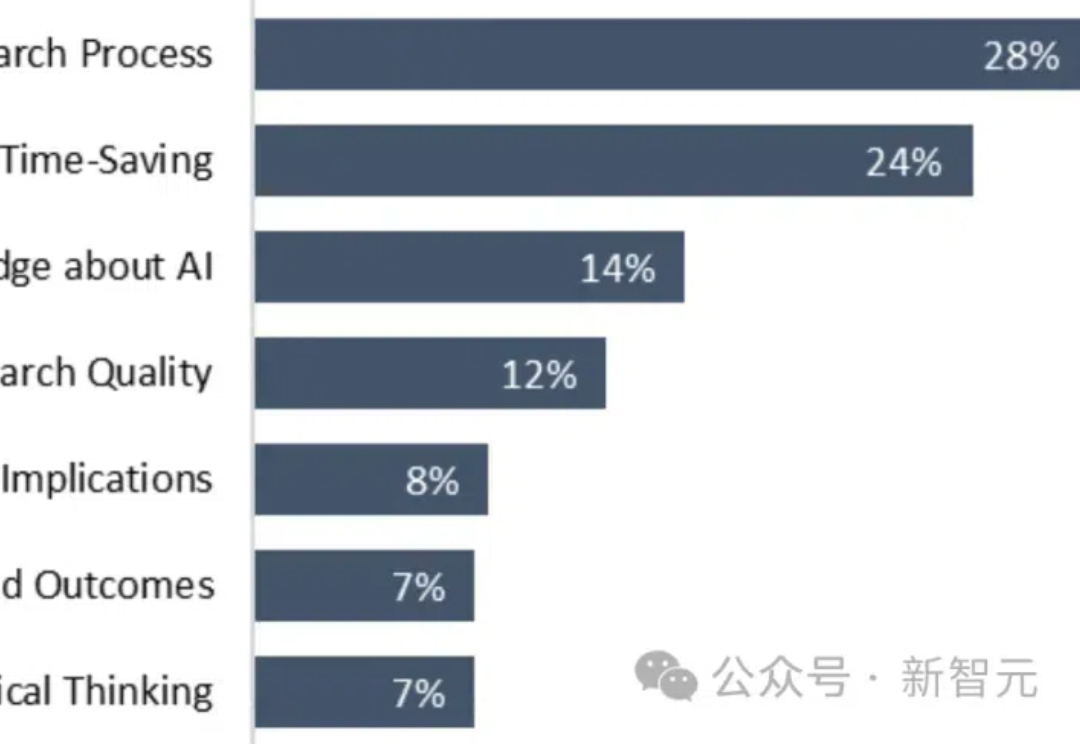
Nature子刊近日发布了一项研究,针对学术写作中大模型的使用。他们发现,那些了解LLM以及大模型相关技术的受访者有更多的发表文章数量。
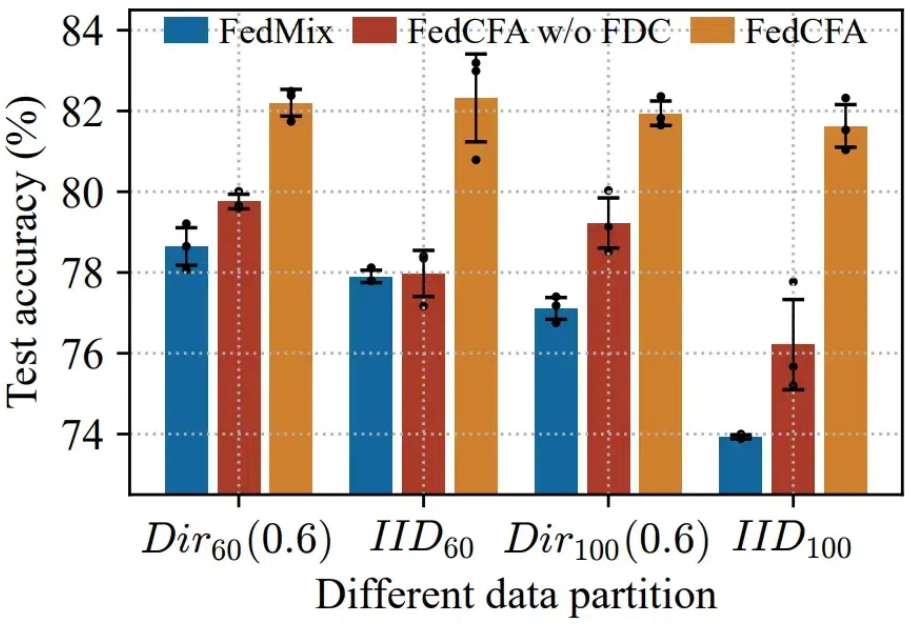
本地训练的客户模型忽视了全局数据中明显的更广泛的模式,聚合的全局模型可能无法准确反映所有客户端的数据分布,甚至可能出现「辛普森悖论」—— 多端各自数据分布趋势相近,但与多端全局数据分布趋势相悖。

MuseAI 是由阿里集团爱橙科技研发的面向阿里内部的 AIGC 创作工作台,同时通过与阿里云旗下魔搭社区合作共建的形式,将主体能力通过魔搭社区的 AIGC 专区对公众开放。

在软件开发过程中,测试用例的生成一直是一个既重要又耗时的环节。近年来,大型语言模型(LLM)在这一领域展现出了巨大的潜力。然而,实践表明,即使是同一个提示词(Prompt),在不同的LLM上也会产生截然不同的效果。
GANs are so back!?

随着 AI 技术的突飞猛进,其进步几乎每天都在刷新人们的认知,很多人都在猜想,AI 是否会在不久的将来取代人类医生?
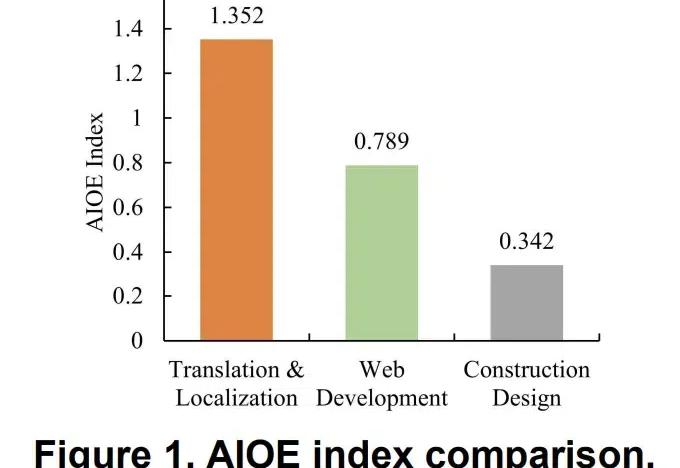
清华校友团队最新成果发现:写作、咨询、编程等相关自由职业最终可能被AI取代,而且更关键的是,AI能力一旦超过某个「拐点」,对就业市场的冲击将一发不可收拾。
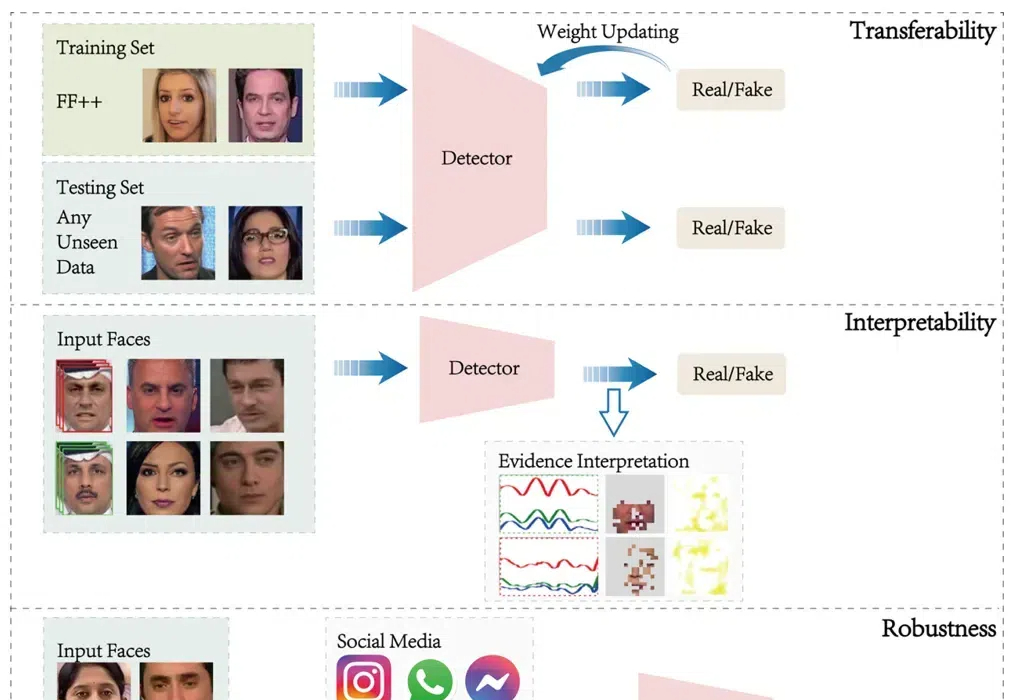
基于深度神经网络对人脸图像进行编辑和篡改,深度伪造的发展为人们的生活带来了便利,但对其错误的应用也同时危害着人们的隐私和信息安全。

GAN已死?不,它卷土重来了!布朗大学和康奈尔大学的研究者刚刚提出了R3GAN,充分利用现代架构设计,彻底摒弃临时技巧,一半参数就能碾压扩散模型。网友惊呼:游戏规则要改变了!
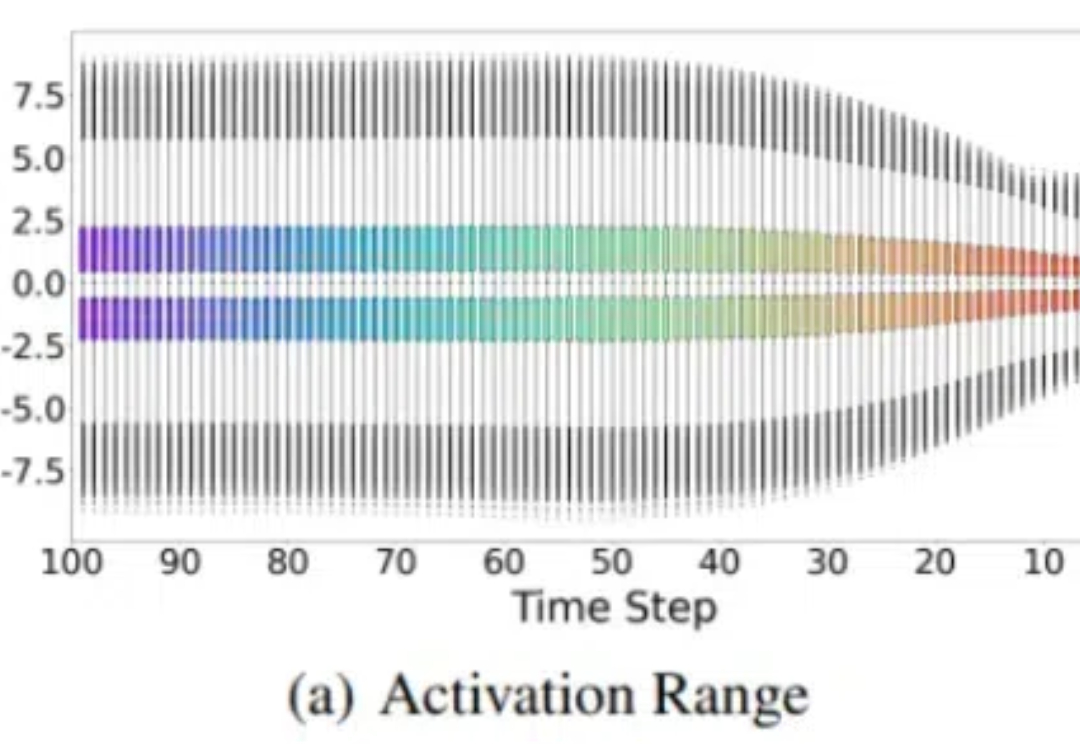
将扩散模型量化到1比特极限,又有新SOTA了! 来自北航、ETH等机构的研究人员提出了一种名为BiDM的新方法,首次将扩散模型(DMs)的权重和激活完全二值化。
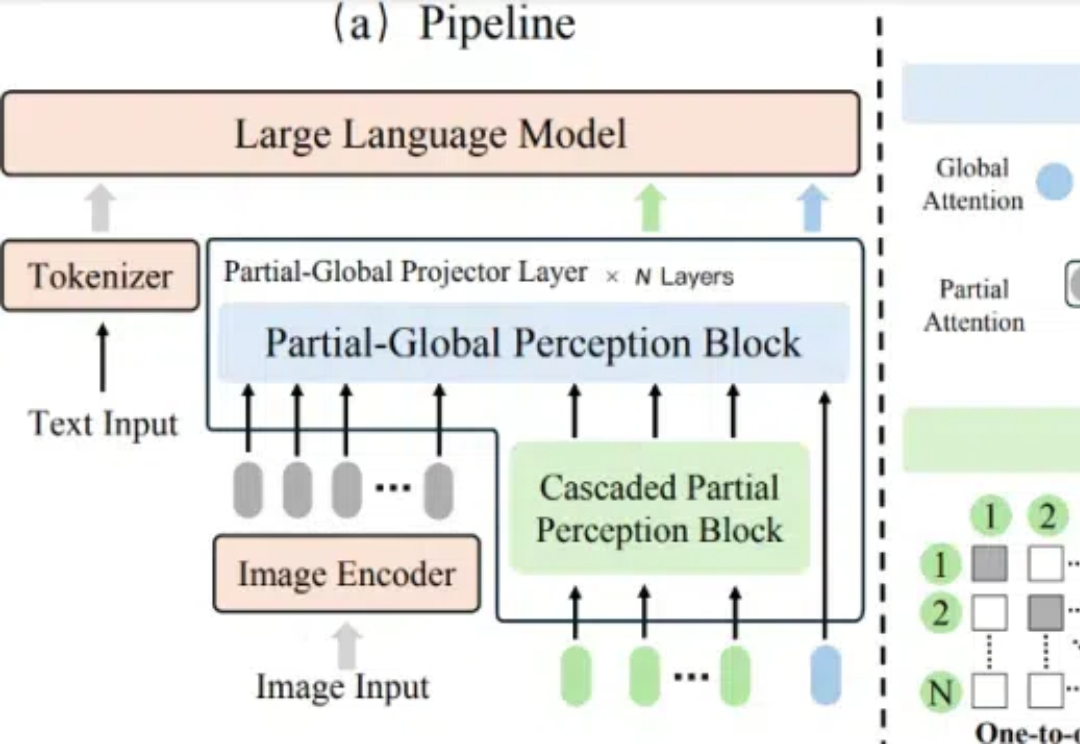
在多模态大语言模型(MLLMs)的发展中,视觉 - 语言连接器作为将视觉特征映射到 LLM 语言空间的关键组件,起到了桥梁作用。

OpenAI Realtime API 的「说明书」。

大模型长序列的处理能力已越来越重要,像复杂长文本任务、多帧视频理解任务、以及 OpenAI 近期发布的 o1、o3 系列模型的高计算量模式,需要处理的输入 + 输出总 token 数从几万量级上升到了几百万量级。
OpenAI o1 给大模型规模扩展 vs 性能的曲线带来了一次上翘。它在大模型领域重现了当年 AlphaGo 强化学习的成功 —— 给越多算力,就输出越多智能,一直到超越人类水平。