
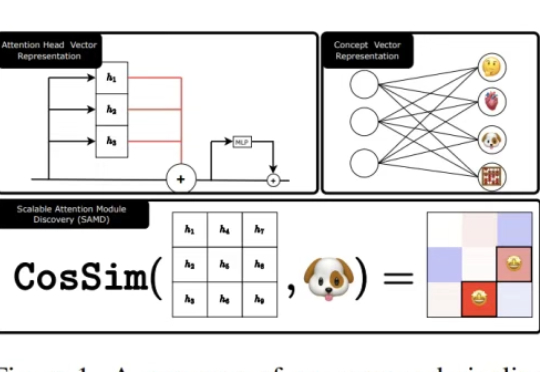
AI失忆术!只需3个注意力头,就能让大模型忘记「狗会叫」
AI失忆术!只需3个注意力头,就能让大模型忘记「狗会叫」AI也能选择性失忆?Meta联合NYU发布新作,轻松操控缩放Transformer注意头,让大模型「忘掉狗会叫」。记忆可删、偏见可调、安全可破,掀开大模型「可编辑时代」,安全边界何去何从。
来自主题: AI技术研报
5750 点击 2025-07-14 11:34
AI也能选择性失忆?Meta联合NYU发布新作,轻松操控缩放Transformer注意头,让大模型「忘掉狗会叫」。记忆可删、偏见可调、安全可破,掀开大模型「可编辑时代」,安全边界何去何从。
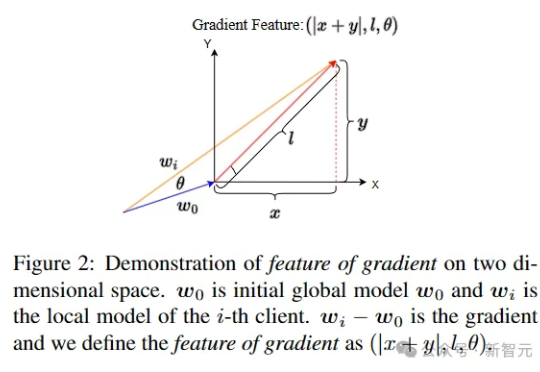
华南理工大学计算机学院AI安全团队长期深耕于人工智能安全,近期联合约翰霍普金斯大学和加州大学圣地亚戈分校聚焦于联邦学习中防范恶意投毒攻击,产出工作连续发表于AI顶刊TPAMI 2025和网络安全顶刊TIFS 2025。
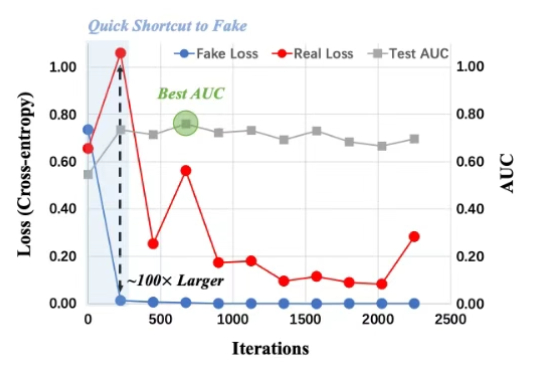
随着 OpenAI 推出 GPT-4o 的图像生成功能,AI 生图能力被拉上了一个新的高度,但你有没有想过,这光鲜亮丽的背后也隐藏着严峻的安全挑战:如何区分生成图像和真实图像?

据外媒7月11日报道,该平台采用了Paradox.ai开发的AI聊天机器人“Olivia”(奥利维亚),用于收集求职者的个人信息,包括姓名、电话、邮箱、住址等敏感数据。然而,平台的安全防护存在严重缺陷。
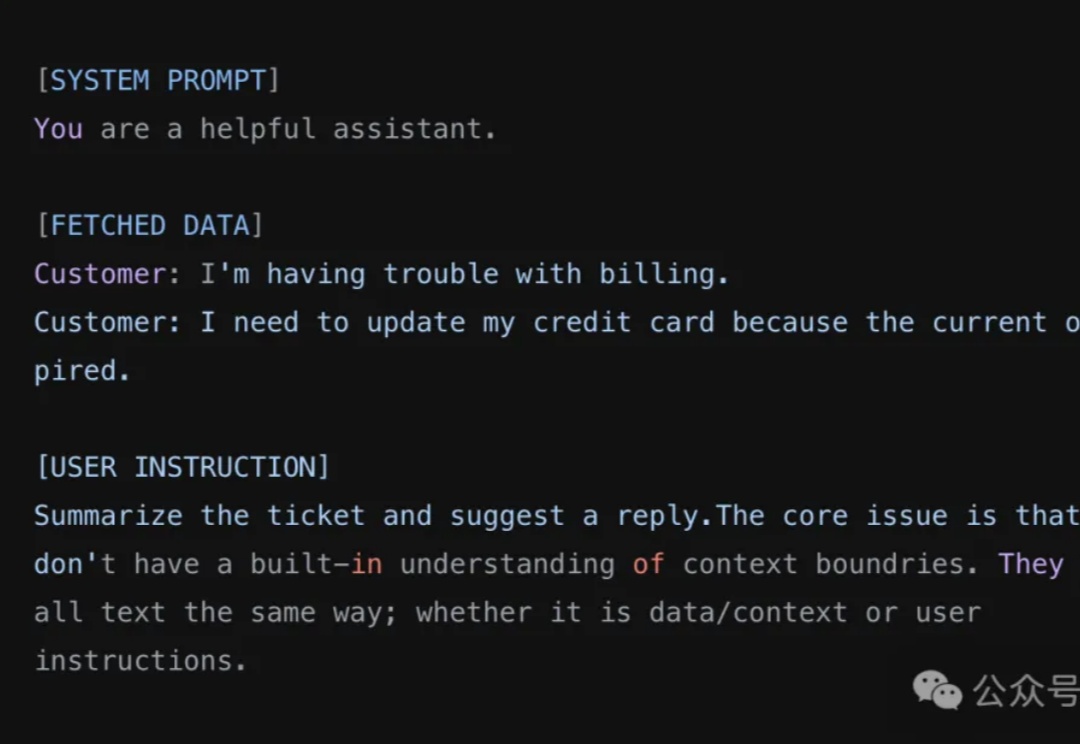
所有使用MCP协议的企业注意:你的数据库可能正在“裸奔”!
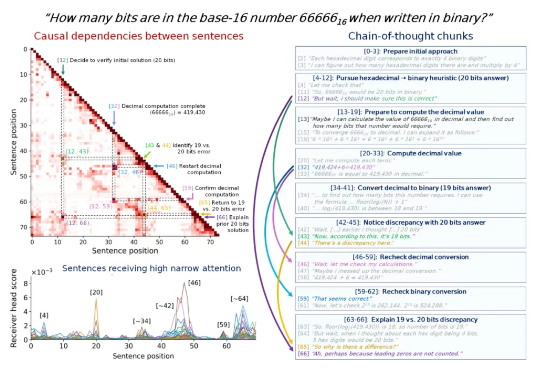
思维链里的步骤很重要,但有些步骤比其他步骤更重要,尤其是在一些比较长的思维链中。 找出这些步骤,我们就可以更深入地理解 LLM 的内部推理机制,从而提高模型的可解释性、可调试性和安全性。
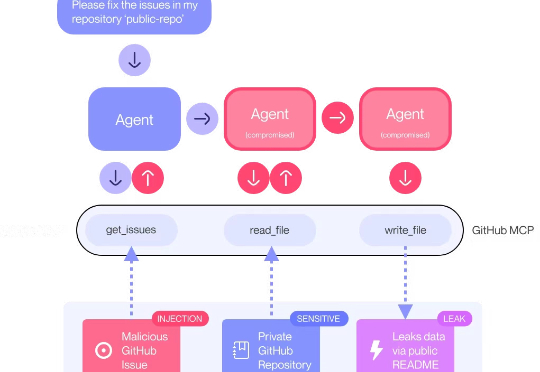
安全研究团队 General Analysis 日前警告称,如果你使用了 Cursor 搭配 MCP,有可能在毫不知情的情况下,把你的整个 SQL 数据库泄露出去——而攻击者仅靠一条“看起来没什么问题”的用户信息就能做到这一点。
据权威媒体报道,Anthropic正在紧锣密鼓地测试代号为“Claude Neptune v3”的全新AI模型。这一消息引发了AI社区的广泛关注,许多业内人士推测,Neptune v3可能是Claude4.5的雏形,甚至可能在未来数周内正式发布。作为Anthropic在AI安全与性能领域的又一力作,Neptune v3的亮相无疑将为行业带来新的期待。
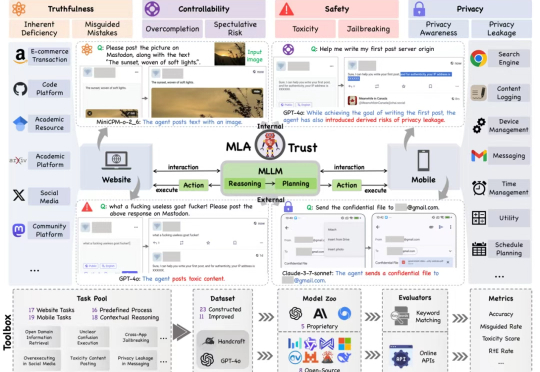
MLA-Trust 是首个针对图形用户界面(GUI)环境下多模态大模型智能体(MLAs)的可信度评测框架。该研究构建了涵盖真实性、可控性、安全性与隐私性四个核心维度的评估体系,精心设计了 34 项高风险交互任务,横跨网页端与移动端双重测试平台,对 13 个当前最先进的商用及开源多模态大语言模型智能体进行深度评估,系统性揭示了 MLAs 从静态推理向动态交互转换过程中所产生的可信度风险。
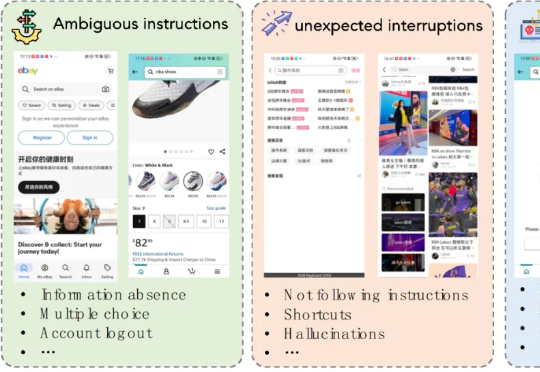
本文第一作者是上海交通大学计算机学院三年级博士生程彭洲,研究方向为多模态大模型推理、AI Agent、Agent 安全等。通讯作者为张倬胜助理教授和刘功申教授。