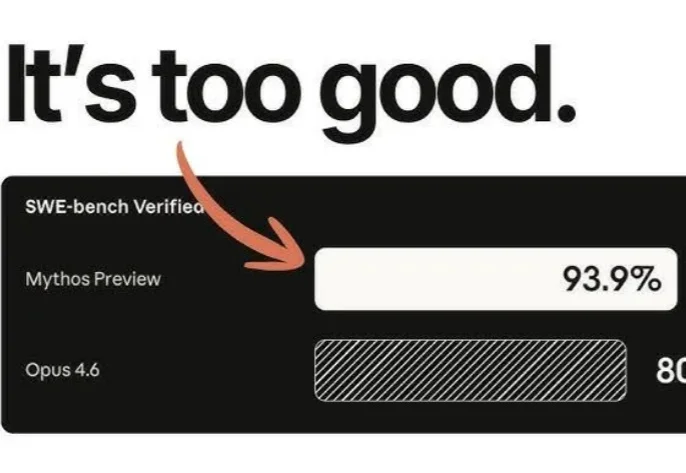
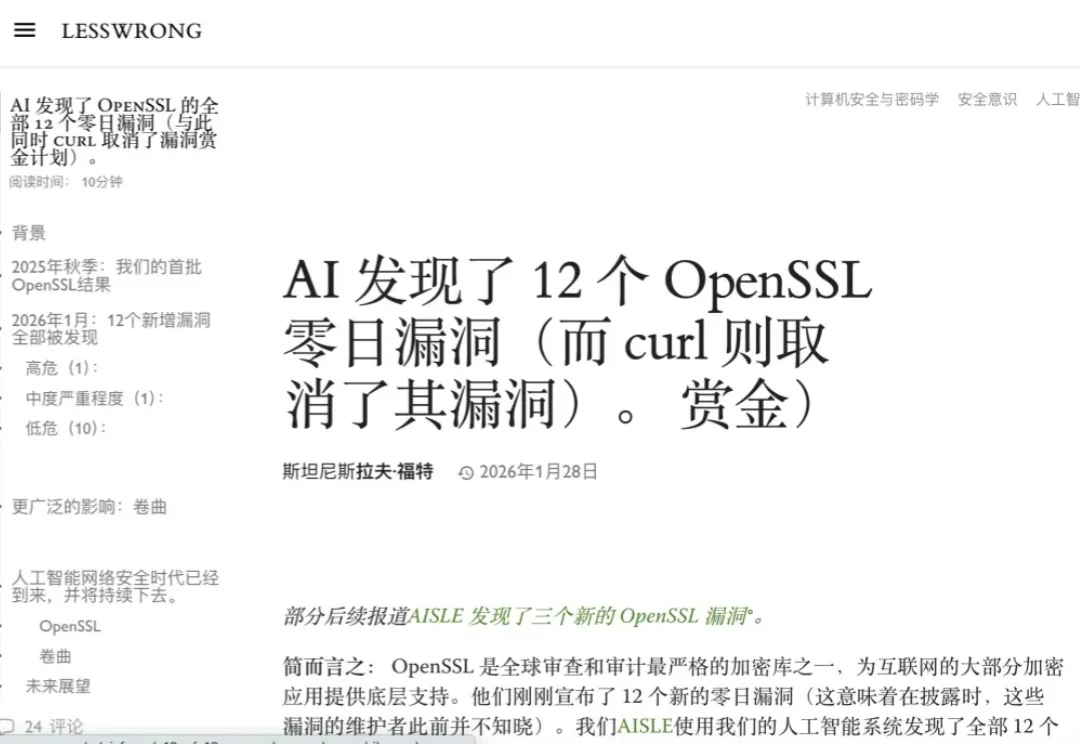
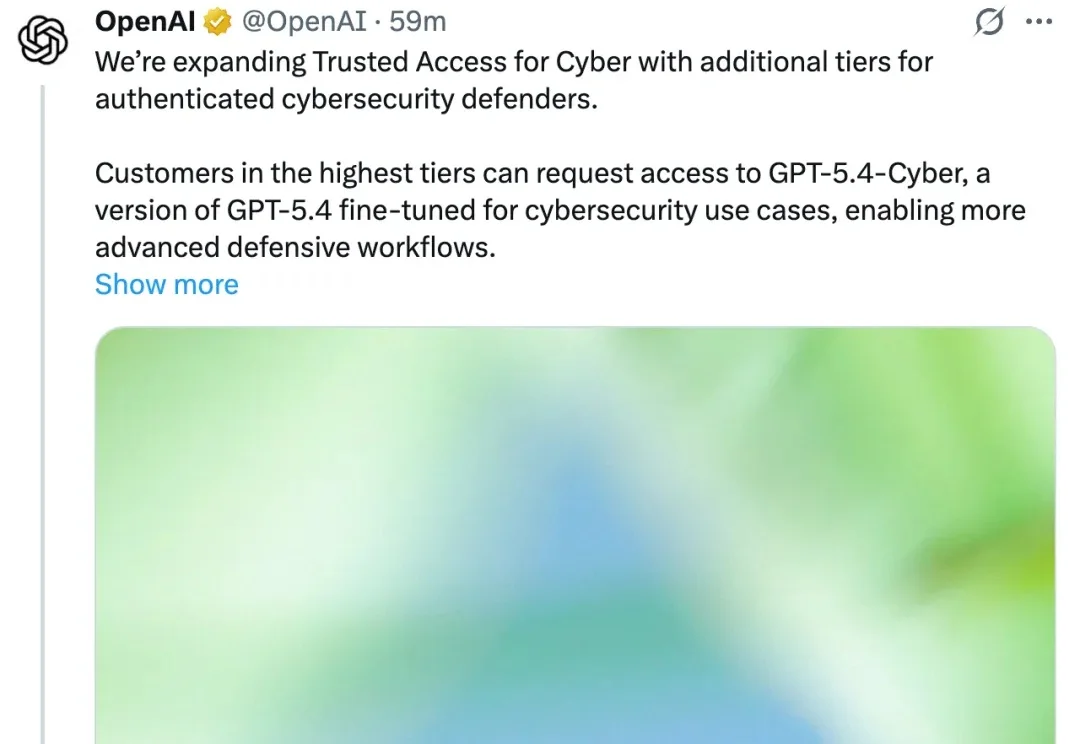
花1.5万、烧掉23亿Token,CTO让Claude一周“打穿”Chrome!实测结果:别等Mythos了,现有AI已经“高危”
花1.5万、烧掉23亿Token,CTO让Claude一周“打穿”Chrome!实测结果:别等Mythos了,现有AI已经“高危”如果你在网络安全圈混,最近一定被“Mythos”刷过屏——Anthropic 搞出了一个能挖 Bug 的 AI 模型,但因为怕被坏人滥用,愣是没敢公开发布。
来自主题: AI资讯
9095 点击 2026-04-22 09:11