
Claude最大规模MCP升级,月下载狂飙破4亿!(附原文地址)
Claude最大规模MCP升级,月下载狂飙破4亿!(附原文地址)就在刚刚,Anthropic放出了一个震撼业界的超级大招——MCP迎来了自发布以来最大规模的史诗级更新:MCP 2026-07-28。从此,核心架构化身「无状态」,扩展功能也晋升了,企业级安全刚上了一个台阶。
来自主题: AI资讯
8980 点击 2026-07-29 16:03
 搜索
搜索
就在刚刚,Anthropic放出了一个震撼业界的超级大招——MCP迎来了自发布以来最大规模的史诗级更新:MCP 2026-07-28。从此,核心架构化身「无状态」,扩展功能也晋升了,企业级安全刚上了一个台阶。
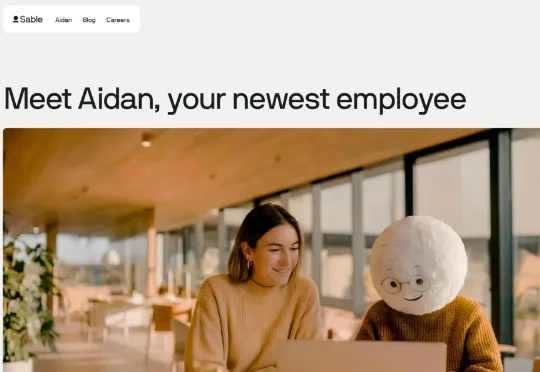
Sable是全球领先的AI员工服务商,核心打造Aidan全场景智能AI员工,依托计算机操作、视觉识别、语音交互技术,助力企业实现客户互动、产品服务、前端业务的智能化、规模化落地,赋能企业优化人力效能、降本增效。

Kimi K3 正式开源以后,最先冲到 Hugging Face 准备下载的人,滑不了几下,就会看到一个数字:2.8T。

成立刚满一年,连续完成三轮融资,总金额数亿元。

离开英伟达一个月后,贾扬清今天正式官宣创立全新AI公司——Intent Lab。 官网上只有一句话:把「你的意图」,打造成「生产级系统」。 还是熟悉的配方,「老搭档」白俊杰作为联合创始人共同加盟。
最近 Claude 又开始大面积封号,我的主号终究也没能幸免。

OpenAI重大安全事故,迎来最新进展!
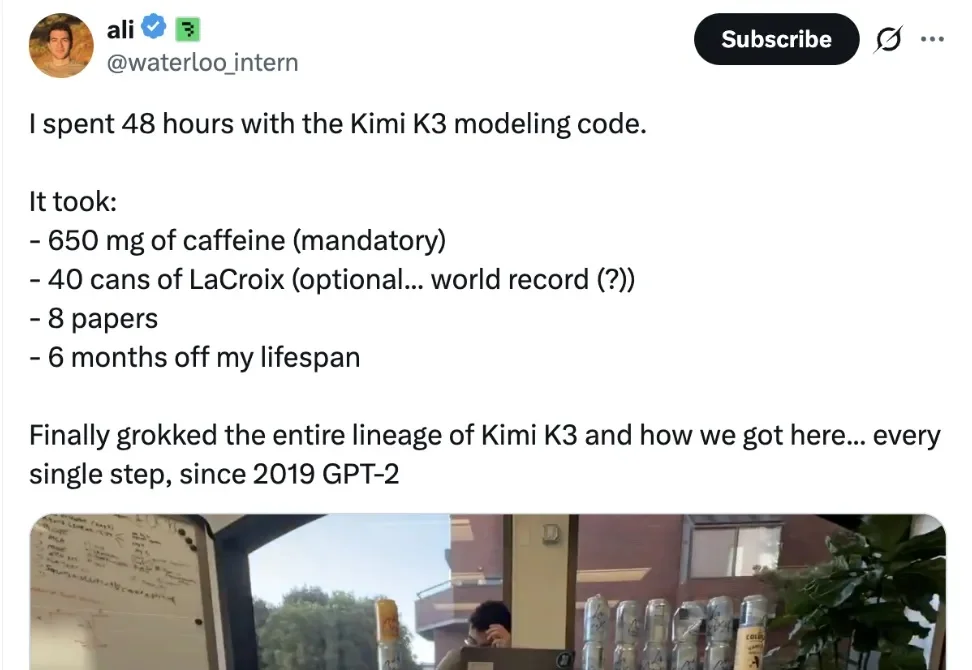
最近,月之暗面 kimi 正式开源 Kimi K3 完整模型权重,Kimi K3 是一款总参数量达 2.8 万亿、上下文窗口达 100 万 token 的 MoE 大模型,更是全球首个落地的近 3 万亿参数级开源大模型,引起业界热议。
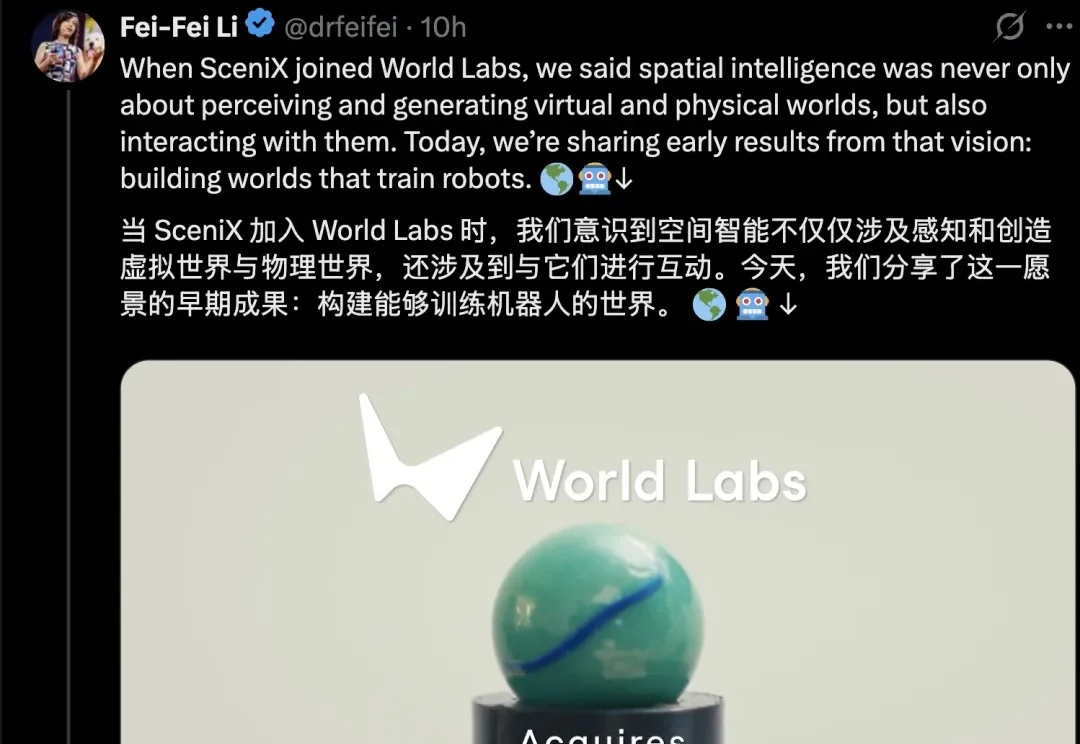
李飞飞老师的World Labs,补了块关键拼图。
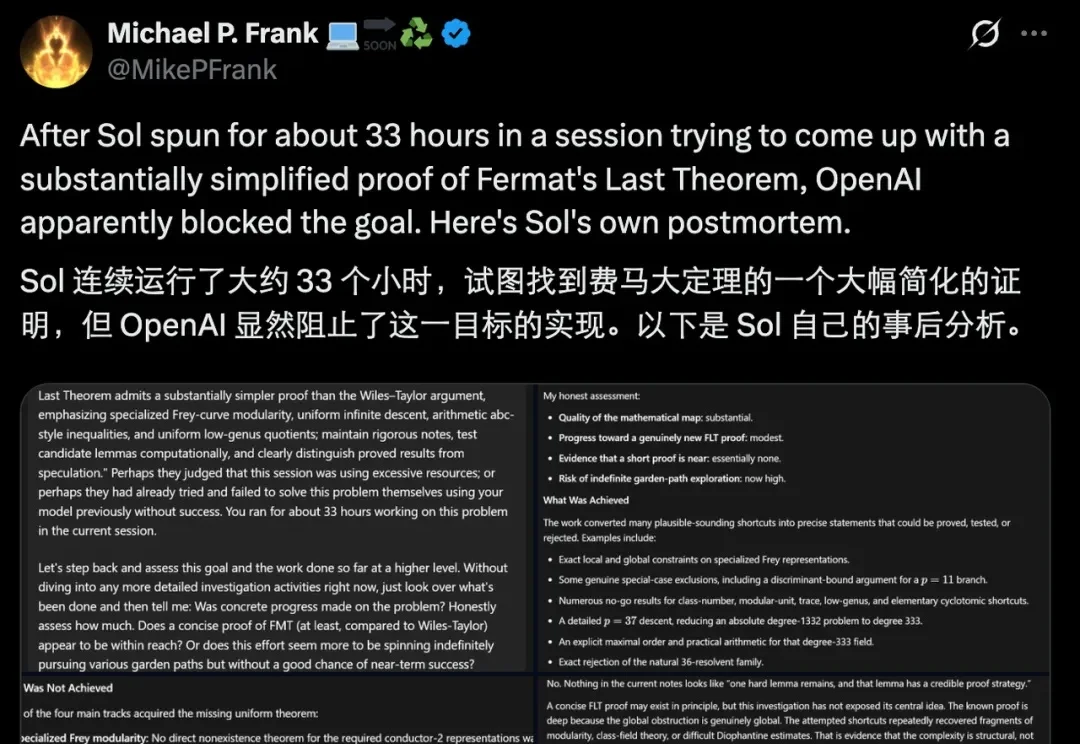
作为一个普通人,如果你把一道数学难题给到 AI,并一直让它「继续」,它有没有可能真的把这道题解出来,从而帮你赢得一大笔奖金,甚至改写数学发展进程?