
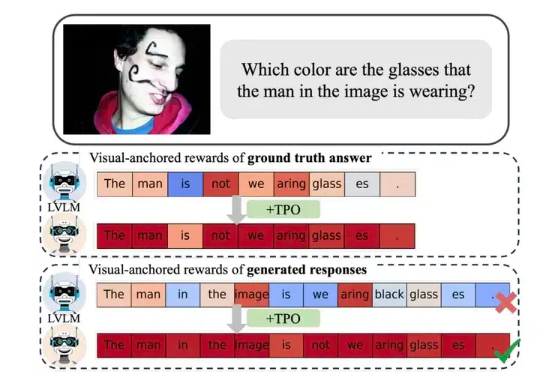
细粒度对齐无需仔细标注了!淘天提出视觉锚定奖励,自我校准实现多模态对齐
细粒度对齐无需仔细标注了!淘天提出视觉锚定奖励,自我校准实现多模态对齐近年来,视觉大模型(Large Vision Language Models, LVLMs)领域经历了迅猛的发展,这些模型在图像理解、视觉对话以及其他跨模态任务中展现出了卓越的能力。然而,随着 LVLMs 复杂性和能力的增长,「幻觉现象」的挑战也日益凸显。
来自主题: AI技术研报
7646 点击 2025-01-19 14:51
近年来,视觉大模型(Large Vision Language Models, LVLMs)领域经历了迅猛的发展,这些模型在图像理解、视觉对话以及其他跨模态任务中展现出了卓越的能力。然而,随着 LVLMs 复杂性和能力的增长,「幻觉现象」的挑战也日益凸显。

家人们,本来咱们想写一篇 TikTok 退出历史舞台的文章,结果小鹿看到:

在 24 年 4 月,我们第一次得知了 Flowith 这个产品,随后便被它创新的交互模式与独特的 AI 生成工作流的 Oracle Agent 所吸引。创始人 Derek 在社交媒体上的帖子也非常振奋人心。与特工们气味相投,有种理想主义的极客风格。

RPA虽然能完成任务的80%,但在20%的失败情况中,仍然需要人工介入;下一代的RPA将由AI Agent来完成,而不是依赖传统的RPA。

据外电报道,就在谷歌与美联社签署协议的第二天,Mistral 还宣布与法新社 (AFP) 达成内容协议,以提高Mistral 聊天机器人产品Le Chat的答案的准确性。对于这家总部位于巴黎的人工智能公司来说,这是第一笔此类交易。这表明 Mistral 不想被视为仅仅一家基础模型制造商。

2024又是AI精彩纷呈的一年。LLM不再是AI舞台上唯一的主角。随着预训练技术遭遇瓶颈,GPT-5迟迟未能问世,从业者开始从不同角度寻找突破。以o1为标志,大模型正式迈入“Post-Training”时代;开源发展迅猛,Llama 3.1首次击败闭源模型;中国本土大模型DeepSeek V3,在GPT-4o发布仅7个月后,用 1/10算力实现了几乎同等水平。

10 个月前,闫俊杰也接受过《晚点》访谈,那时他提了 16 次字节、47 次 OpenAI,8 次 Anthropic。这次再聊,他主动提字节少了,提 Anthropic 多了。这与行业风向形成微妙的反差。

测试共振式写法的一例, 科幻小说 Prompt。 Happy Prompting.取刘慈欣短篇小说《朝闻道》的故事梗概作为测试内容。输入:外星人降临地球,他们宣称已经掌握了宇宙的终极答案,但人类不能免费获得,需要拿自己的一条命,获得一次提问答案的机会。现在选择权到了人类科学家的手中。

Fermata是一家专门从事农业计算机视觉解决方案的数据科学公司,在Raw Ventures支持的A轮融资中获得了1000万美元。这项投资将支持该公司为农业行业开发集中式数字大脑的战略愿景,通过先进的数据分析实现作物的自主管理,创建一个不断发展的系统,不断从可用数据中学习。

近日,珞博智能(Robopoet)官方发布一则消息,前字节大模型解决方案架构师潘雨楠(Yuna)正式加入珞博,出任联合创始人兼首席技术官(CTO)。潘雨楠本科毕业于哈尔滨工业大学,又在香港大学取得计算机专业硕士学位,她的学术背景为其在科技领域的发展奠定了坚实基础。