

Crew.ai 之记忆混淆处理方法之李四九到底是谁?
Crew.ai 之记忆混淆处理方法之李四九到底是谁?大模型的记忆片段进行多次替换的时候,会导致模型输出的内容叠加不同记忆片段,出现混淆和错乱的问题。在我做 Crew.ai 知识库测试的时,替换多份知识库文档后,发现大模型已经疯了。
来自主题: AI资讯
6548 点击 2025-01-19 09:55
大模型的记忆片段进行多次替换的时候,会导致模型输出的内容叠加不同记忆片段,出现混淆和错乱的问题。在我做 Crew.ai 知识库测试的时,替换多份知识库文档后,发现大模型已经疯了。

什么,歪果仁怀疑咱中国的宇树机器人昨天释放的最新视频,是特效?

不断迭代简单的提示词「write better code」,代码生成任务直接提速100倍!不过「性能」并不是「better」的唯一标准,还需要辅助适当的提示工程,也是人类程序员的核心价值所在。

与 Devin 合作一个月后,这些研究者给出了不太乐观的反馈。

昨天,我们报道了一个行业猜想,说是 OpenAI 和 Anthropic 等前沿大模型公司可能已经训练出了下一代大模型,但由于它们的使用成本过高,所以短时间内根本不会被放出来。

大型语言模型(LLMs)能够解决研究生水平的数学问题,但今天的搜索引擎却无法准确理解一个简单的三词短语。

一个新框架,让Qwen版o1成绩暴涨: 在博士级别的科学问答、数学、代码能力的11项评测中,能力显著提升,拿下10个第一! 这就是人大、清华联手推出的最新「Agentic搜索增强推理模型框架」Search-o1的特别之处。

OpenAI,有大事发生!最近各种爆料频出,比如OpenAI已经跨过「递归自我改进」临界点,o4、o5已经能自动化AI研发,甚至OpenAI已经研发出GPT-5?OpenAI员工如潮水般爆料,疯狂暗示内部已开发出ASI。
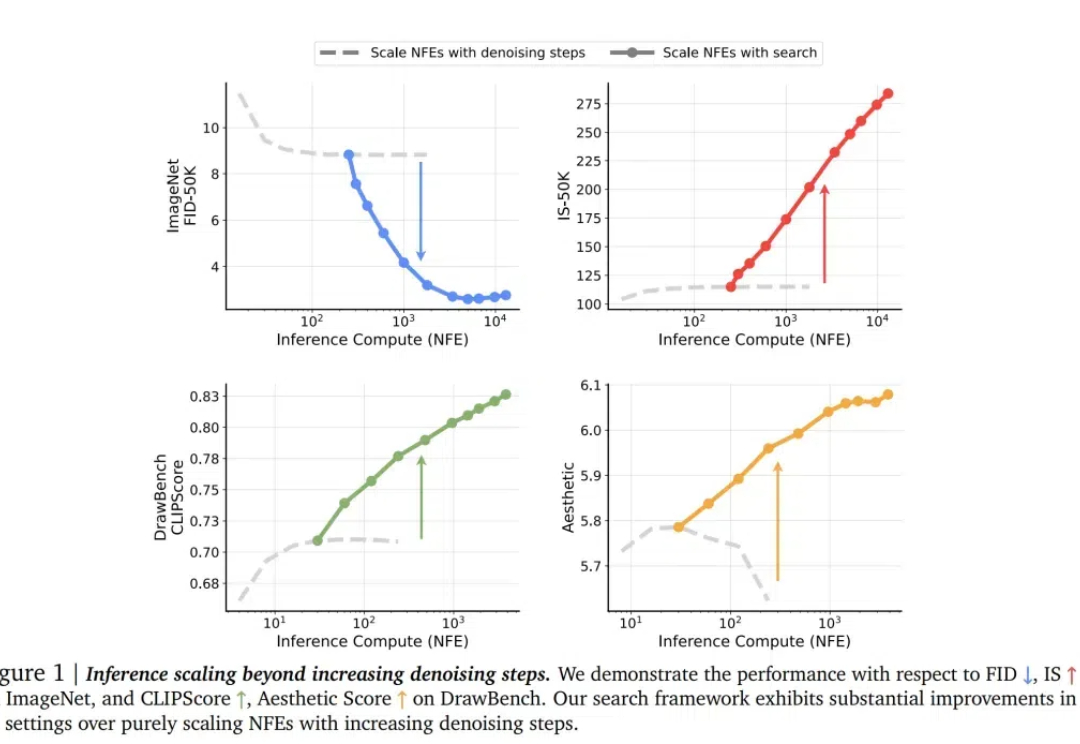
对于 LLM,推理时 scaling 是有效的!这一点已经被近期的许多推理大模型证明:o1、o3、DeepSeek R1、QwQ、Step Reasoner mini……
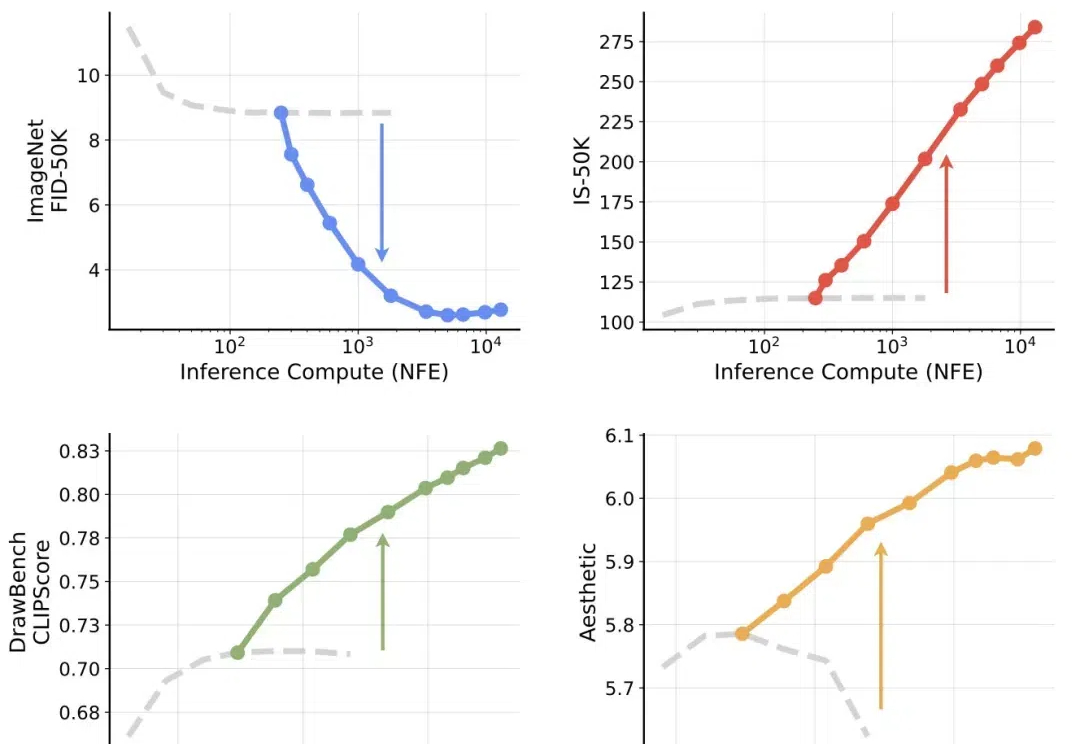
划时代的突破来了!来自NYU、MIT和谷歌的顶尖研究团队联手,为扩散模型开辟了一个全新的方向——测试时计算Scaling Law。其中,谢赛宁高徒为共同一作。