

有网友称收到苹果AI国行版升级通知,官方回应
有网友称收到苹果AI国行版升级通知,官方回应有博主称,苹果公司已在近期针对部分国行设备启动“Apple智能与Siri”功能的灰度测试,获得测试资格的用户可在设备设置中查看相关选项。具体设置路径为“设置 - Apple智能与AI - 打开Apple智能”,首次设置需在连接电源和Wi-Fi的情况下升级下载,下载完毕后桌面将新增图乐园App。
来自主题: AI资讯
9307 点击 2026-01-04 17:27
有博主称,苹果公司已在近期针对部分国行设备启动“Apple智能与Siri”功能的灰度测试,获得测试资格的用户可在设备设置中查看相关选项。具体设置路径为“设置 - Apple智能与AI - 打开Apple智能”,首次设置需在连接电源和Wi-Fi的情况下升级下载,下载完毕后桌面将新增图乐园App。

Sam Altman 与 Jony Ive 联手探索的无屏 AI 硬件,正在被逐步揭开。供应链信息显示,这款产品并没有选择屏幕,而更像是一种可穿戴设备:体积接近 iPod Shuffle,可以放入口袋或随身佩戴;内置麦克风与摄像头,持续感知用户所处的真实环境,与之并肩工作,主动给出建议。

算法,正在成为人类幼崽的新母语。
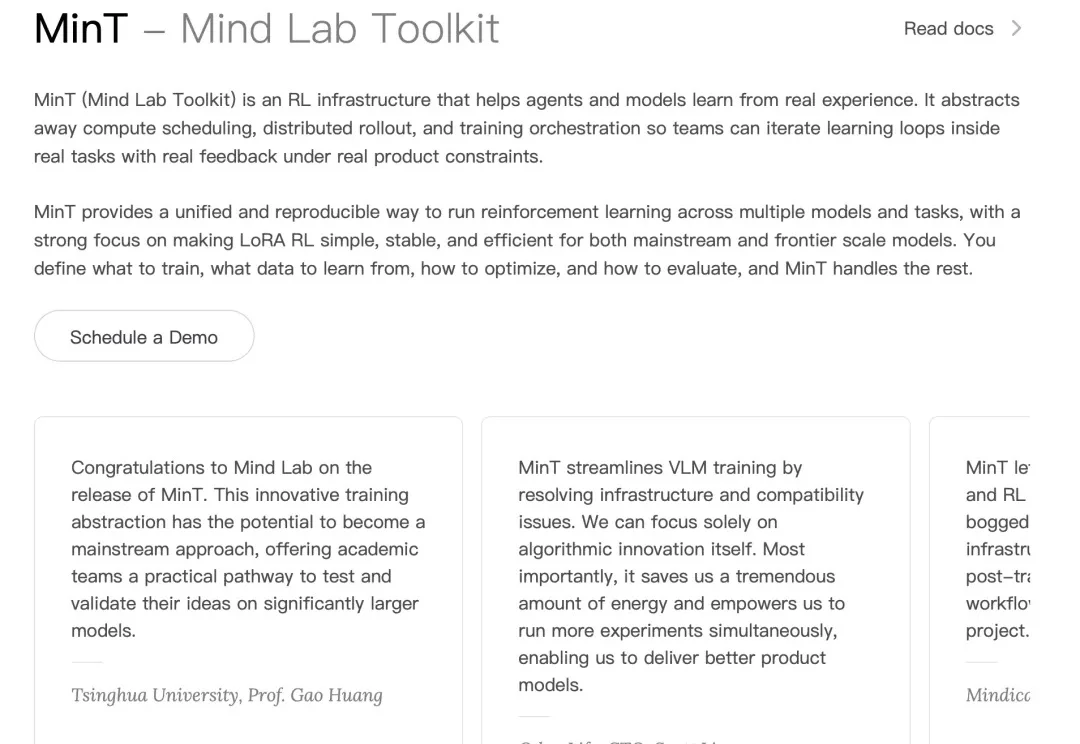
在大公司一路高歌猛进的 AI 浪潮里,小创业者和高校研究者正变得越来越迷茫。就连前段时间谷歌创始人谢尔盖・布林回斯坦福,都要回答「大学该何去何从」「从学术到产业的传统路径是否依然重要」这类问题。

你有没有发现,你让AI读一篇长文章,结果它读着读着就忘了前面的内容? 你让它处理一份超长的文档,结果它给出来的答案,牛头不对马嘴? 这个现象,学术界有个专门的名词,叫做上下文腐化。 这也是目前AI的通病:大模型的记忆力太差了,文章越长,模型越傻!
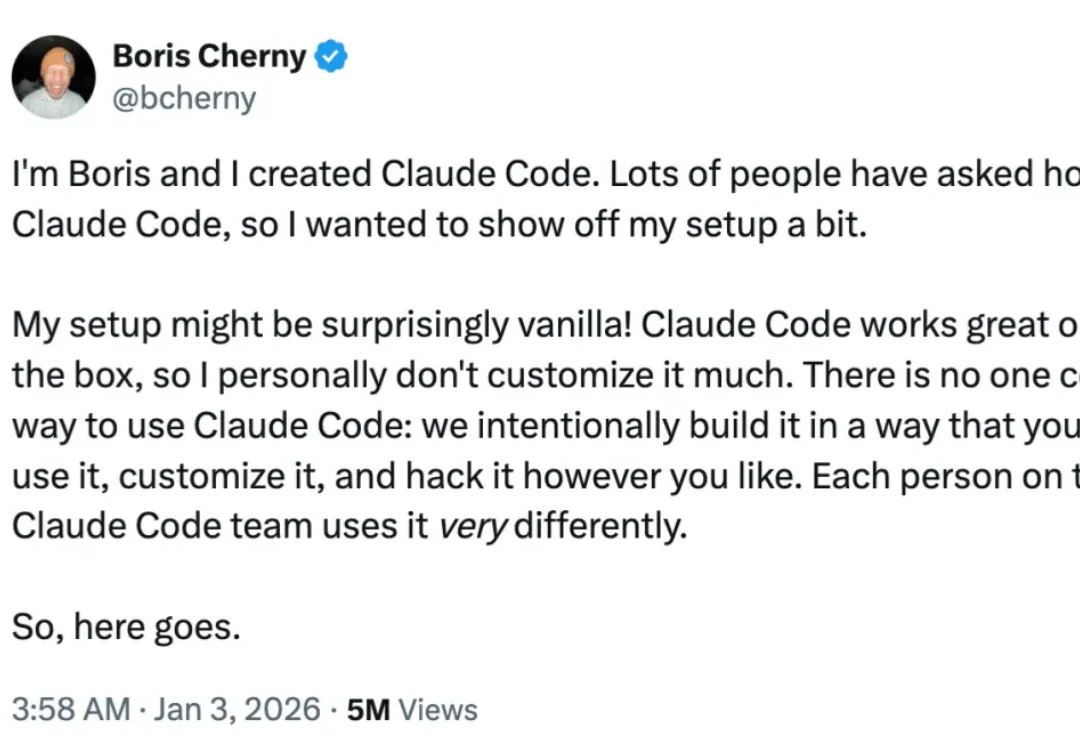
2026 新年第三天,Claude Code 创建者、负责人 Boris Cherny 开展「线上教学」,亲自示范他自己使用这个 AI 编程工具的工作流。
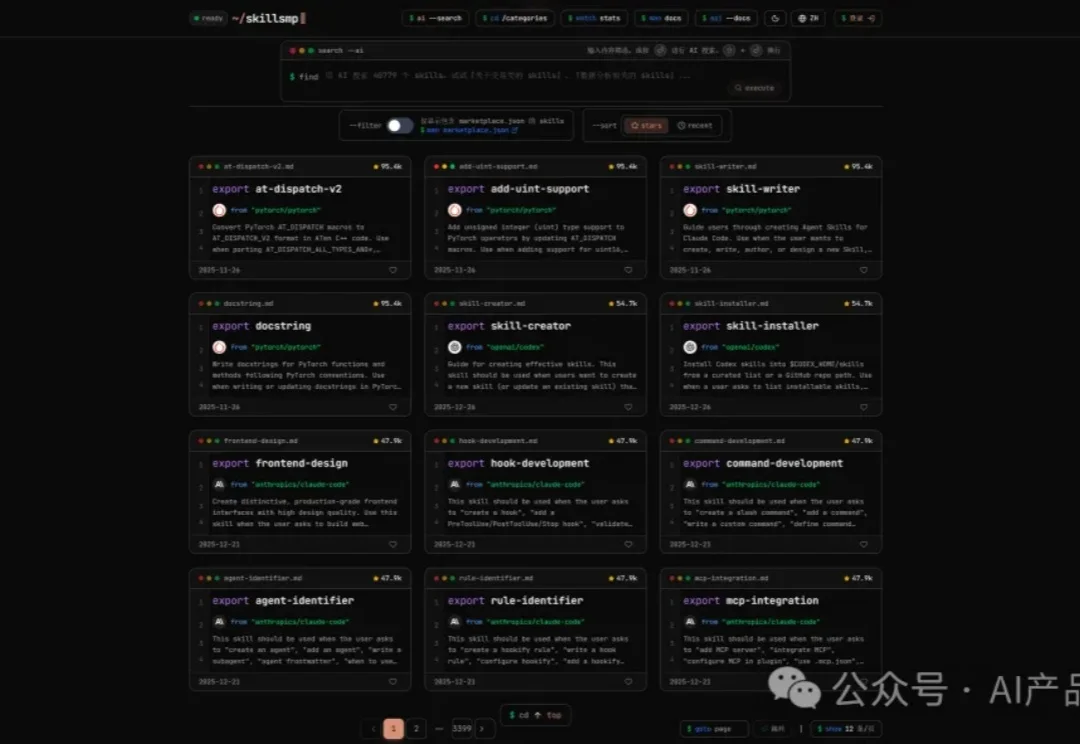
最近火的一塌糊涂的 Skills 很多群友在问是啥东东
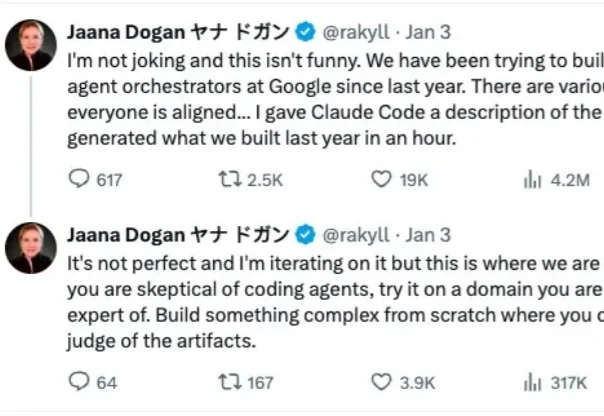
一位谷歌资深工程师透露,Anthropic 的 Claude Code 用一小时跑出了她团队打磨了一年的系统。

AI人才竞争白热化,大厂纷纷高薪招募实习生。Anthropic、OpenAI、Google、Meta使用钞能力,给实习生最高开出12.8万月薪!

1900亿美金的游戏帝国正迎来寒冬!《原神》式的重金堆砌已近极限,李飞飞携「世界模型」暴力拆解行业规则。从4倍速开发到Genie 3瞬间造梦,AI正在终结搬砖时代。这场关于造物权的豪赌,你准备好成为上帝了吗?