

Meta大逃杀!小扎「地狱模式」曝光,不拼命搞AI就滚蛋
Meta大逃杀!小扎「地狱模式」曝光,不拼命搞AI就滚蛋面对Llama3系列的失利,小扎将2025年定义为Meta的「高强度之年」,不仅在AI上投入数百亿美金,还开启一系列「闪电战」,包括重金挖人、成立MSL、收紧绩效考核,削减元宇宙投入等。年关将近,小扎的「高强度之年」能救Meta吗?
来自主题: AI资讯
9042 点击 2025-12-27 10:38
面对Llama3系列的失利,小扎将2025年定义为Meta的「高强度之年」,不仅在AI上投入数百亿美金,还开启一系列「闪电战」,包括重金挖人、成立MSL、收紧绩效考核,削减元宇宙投入等。年关将近,小扎的「高强度之年」能救Meta吗?

每一个专家/资深人士曾经都是菜鸟/小白,但现如今 AI 正在锯断通往专家的阶梯。由技术进化带来的问题,答案已经超出了技术本身。当我读完张笑宇所著的《AI 文明史·前史》,对之前困惑的问题就有了一些答案。
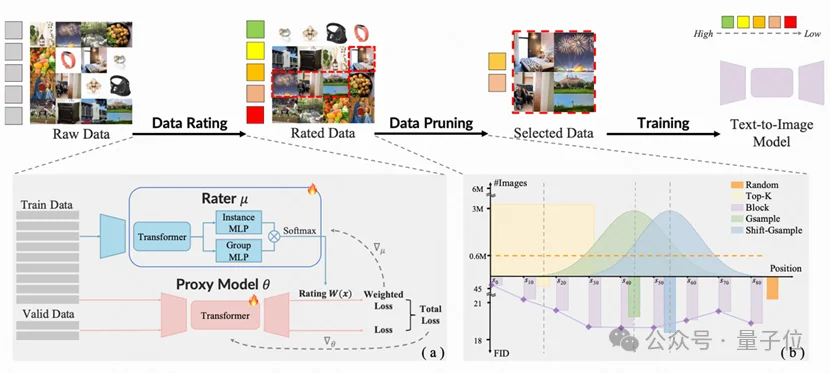
由香港大学丁凯欣领导,联合华南理工大学周洋以及快手科技Kling团队共同完成的这项研究,开发出了一个名为“炼金师”(Alchemist)的AI系统。它就像一位挑剔的大厨,能从海量图片数据中精准挑选出最有价值的一半。

Canva可画并没有想取代什么,它只是把99%的普通人从设计的枯燥苦海中捞了出来。
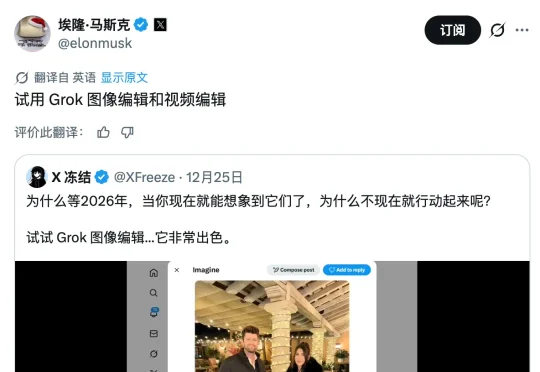
圣诞假期,马斯克给全球画师送了份「厚礼」。起因是社交平台 X 上线了一个基于 Grok 模型的「AI 编辑」功能。用户只需长按手机图片或点击网页版的「编辑图片」按钮,就能输入文字指令,让 AI 随意修改别人发布的作品。
好震惊,好意外,现在一份4–6个月的AI相关实习,月薪已经接近14万人民币了!而且这个价格不是个例——OpenAI、Anthropic、Meta、Google DeepMind等巨头,都为实习、Fellowship、Residency这类短期岗位,开出足以对标全职研究员的价格。
。过去的行业共识是:端侧只能跑小模型,性能与体验必须妥协;真正的能力仍得依赖云端最强模型。万格智元要打破的,正是这条旧认知。公司正在打造的cPilot端侧算力引擎,选择了一条更难、却更接近未来的路径:通过自研的非GPU推理引擎,让300亿、500亿等超大模型在性能有限制的消费硬件上高效推理
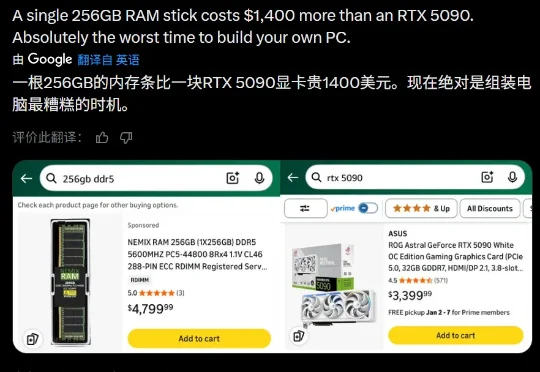
英伟达的顶配 GPU RTX 5090 官方起售价为 1999 美元(经过市场溢价可能达到了 3000 美元以上),而一根单条 256GB 的 DDR5 内存如今的市场价却也飙升到了 3500-5000 美元之间。

英伟达在开源模型上玩的很激进: “最高效的开放模型家族”Nemotron 3,混合Mamba-Transformer MoE架构、NVFP4低精度训练全用上。而且开放得很彻底:

上海遐福养老院,80多岁的吴奶奶举起手机,屏幕上是她用AI制作的视频——她手捧鲜花,穿上婚纱,与身着西装搭配红色领带的丈夫,并肩走向婚姻殿堂。“非常激动。”她的声音有些颤抖,“我们结婚的时候没拍过婚纱照,后来也没拍过。”