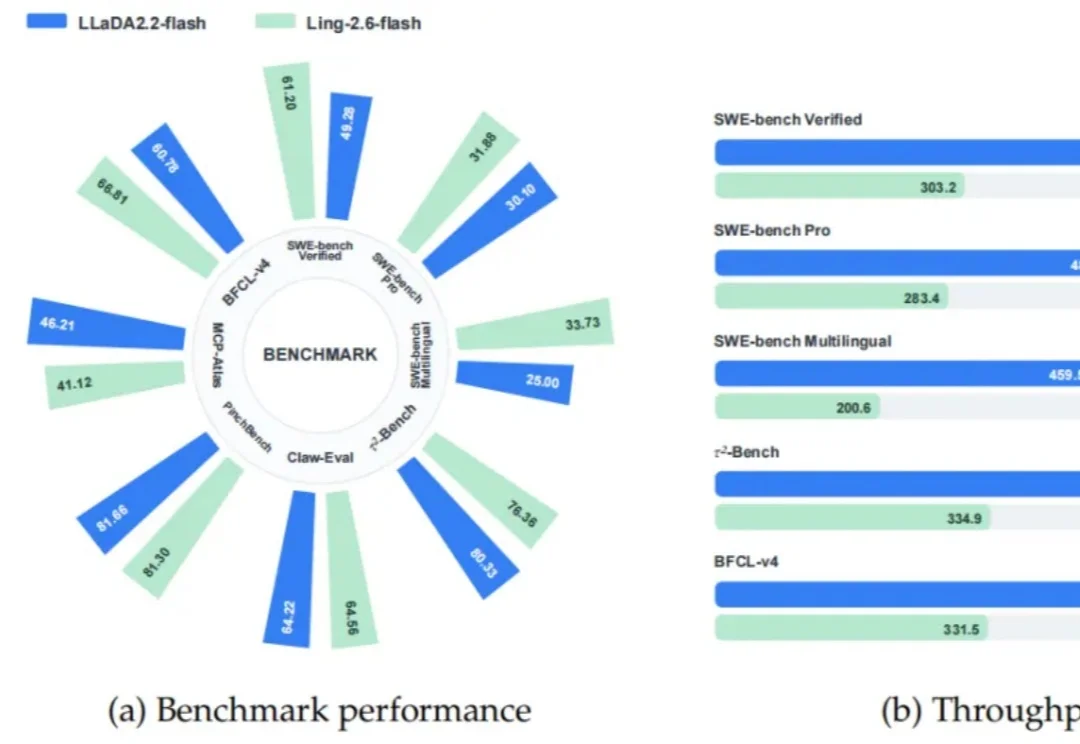
全球首个Agentic扩散模型来了:边行动边纠错,128K上下文追平自回归
全球首个Agentic扩散模型来了:边行动边纠错,128K上下文追平自回归终于!Agent赛道,不再是自回归(AR)模型一家独大。
来自主题: AI技术研报
8858 点击 2026-07-29 10:10
 搜索
搜索
终于!Agent赛道,不再是自回归(AR)模型一家独大。

今天,多位开发者在DeepSeek官方交流群和社交媒体上反馈,DeepSeek官方API所调用的模型能力出现了变化,已拥有一百万的上下文窗口,而不是此前的128k,知识截止日期更新为2025年5月,而不是此前的2024年。
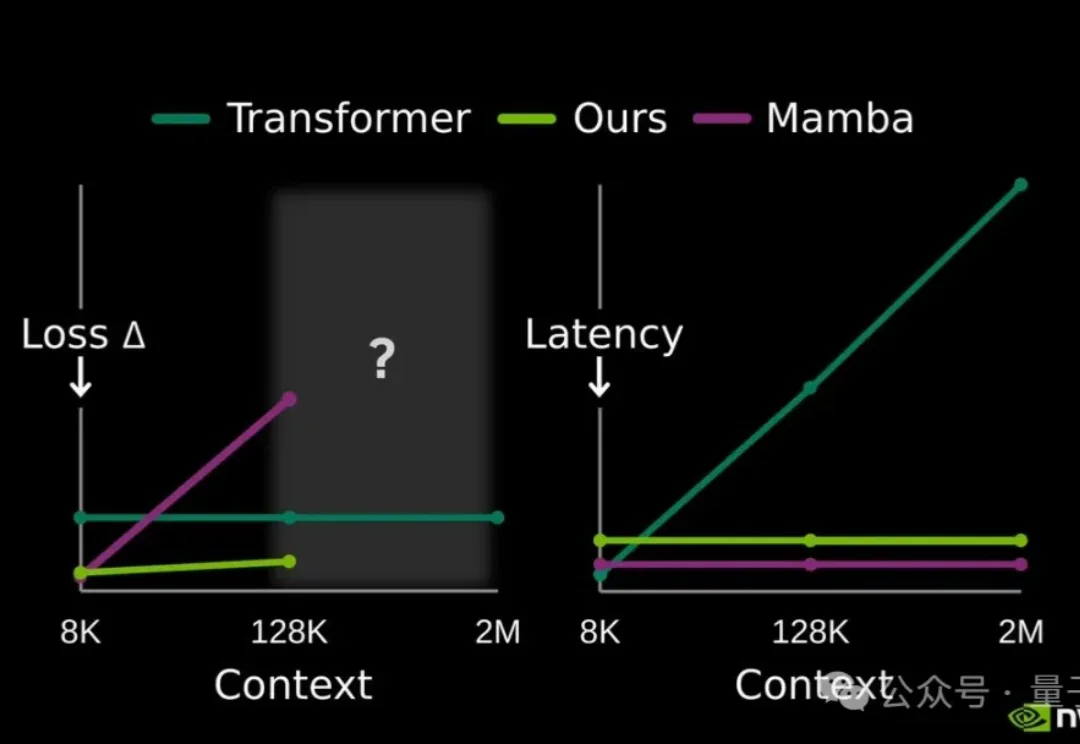
提高大模型记忆这块儿,美国大模型开源王者——英伟达也出招了。
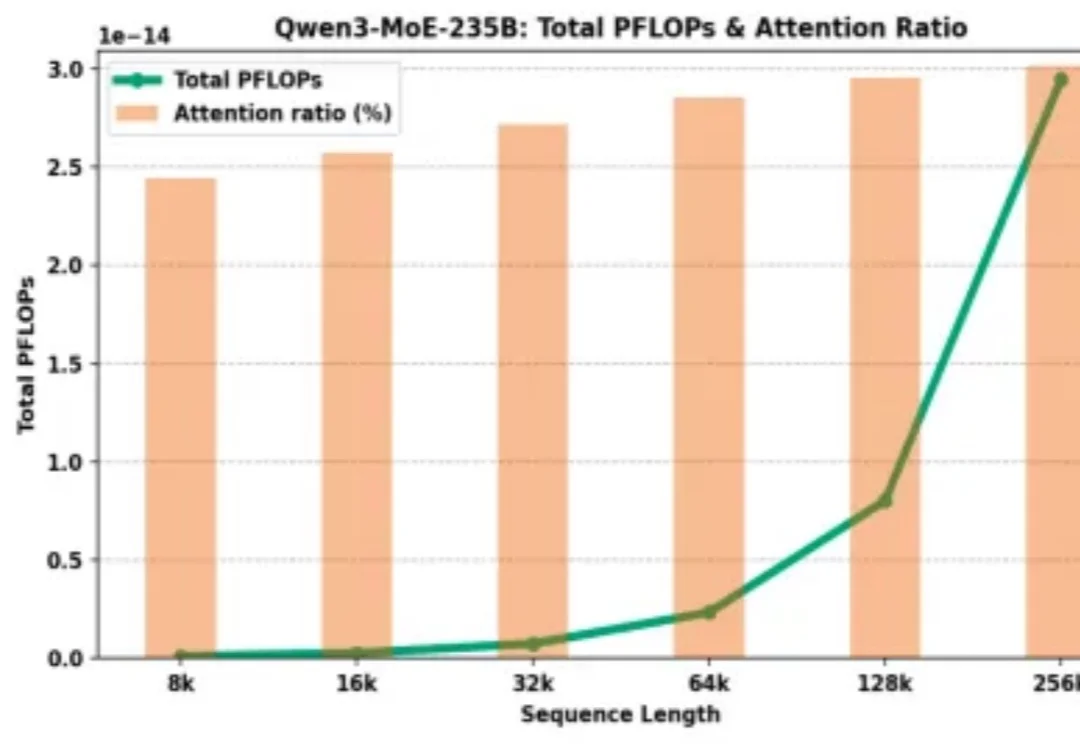
为什么大模型厂商给了 128K 的上下文窗口,却在计费上让长文本显著更贵?
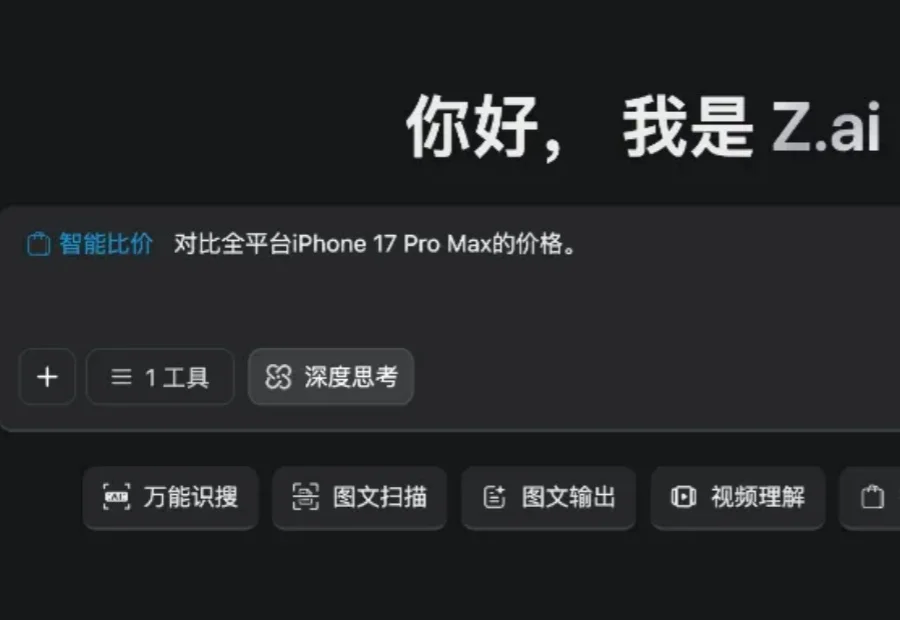
原生工具调用、128K上下文,图文创作仍有短板。

9 月 22 日下午,联发科推出的新一代旗舰 5G 智能体 AI 芯片 —— 天玑 9500,并展示了一系列新形态端侧的 AI 应用,在公众层面首次推动端侧 AI 从尝鲜到好用。现在,让手机端大语言模型(LLM)处理一段超长的文本,最长支持 128K 字元,它只需要两秒就能总结出会议纪要,AI 还能自动修改你的错别字。
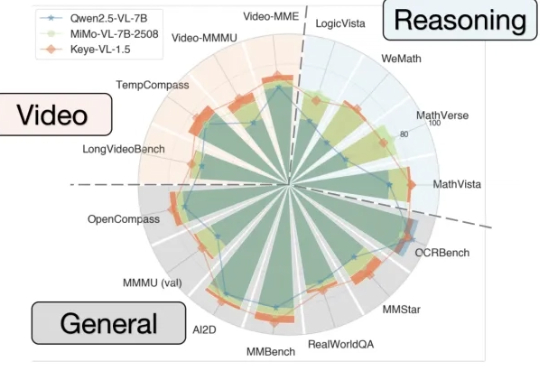
能看懂视频并进行跨模态推理的大模型Keye-VL 1.5,快手开源了。
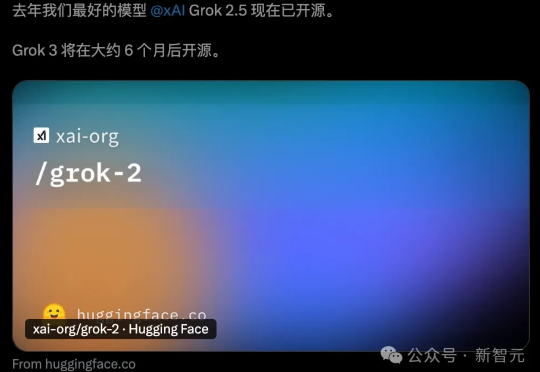
Grok-2正式开源,登上Hugging Face,9050亿参数+128k上下文有多猛?近万亿参数「巨兽」性能首曝。马斯克再现「超人」速度,AI帝国正在崛起。
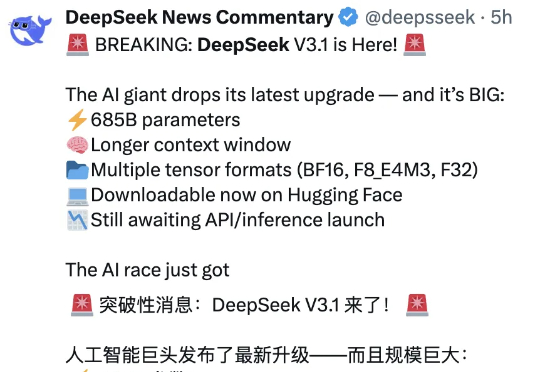
DeepSeek V3.1和V3相比,到底有什么不同?官方说的模模糊糊,就提到了上下文长度拓展至128K和支持多种张量格式,但别急,我们已经上手实测,为你奉上更多新鲜信息。

DeepSeek V3.1新版正式上线,上下文128k,编程实力碾压Claude 4 Opus,成本低至1美元。在昨晚,DeepSeek官方悄然上线了全新的V3.1版本,上下文长度拓展到128k。本次开源的V3.1模型拥有685B参数,支持多种精度格式,从BF16到FP8。