字节Seedance 2.0发论文了,171人署名,吴永辉曾妍在列
字节Seedance 2.0发论文了,171人署名,吴永辉曾妍在列现象级AI视频技术、字节Seedance 2.0在arXiv发论文了。晒了26页的Benchmark,和贡献者名单。170位团队成员全公开,署名和尊重都拉满了,不过嘛这就不怕……嘛?
来自主题: AI资讯
9280 点击 2026-04-17 15:18
 搜索
搜索
现象级AI视频技术、字节Seedance 2.0在arXiv发论文了。晒了26页的Benchmark,和贡献者名单。170位团队成员全公开,署名和尊重都拉满了,不过嘛这就不怕……嘛?

今日,腾讯正式发布并开源混元3D世界模型2.0(HY-World 2.0)。作为一款多模态的世界模型,HY-World 2.0支持文字、图片和视频等形式输入,可自动生成、重建并模拟完整的3D世界。
拍一圈照片,就能生成一个可交互的 3D 世界,已经不是什么新鲜话题了。但问题是如何把一个大世界塞进普通人的手机浏览器里。
距离新模型Marble 1.1&1.1-Plus发布不到一个周,李飞飞空间智能独角兽World Labs再度传来新消息—— 开源3D高斯溅射渲染引擎Spark 2.0。

“你好,老板,你这个视频我们用即梦Seedance 2.0 生成,这一条视频报价1235.25元人民币,我们分分钟就可以用这1609.45元做出来这条视频,这可是仅仅2235.32元人民币就能换来的视频爆款,都不知道有多划算,我们产出一条视频仅需要一天,白天开工,到了晚上您只需要支付3245.98元就可以了,现在签合同吗?”

LangChain 只换了模型外面的基础设施——同一个模型、同一套权重——就从 TerminalBench 2.0 排行榜 30 名开外直接跳到了第 5 名。另一个独立研究项目让大模型自己优化这层基础设施,达到了 76.4% 的通过率,超过了所有人工设计的方案。

HappyHorse身份曝光,或将明天上线?
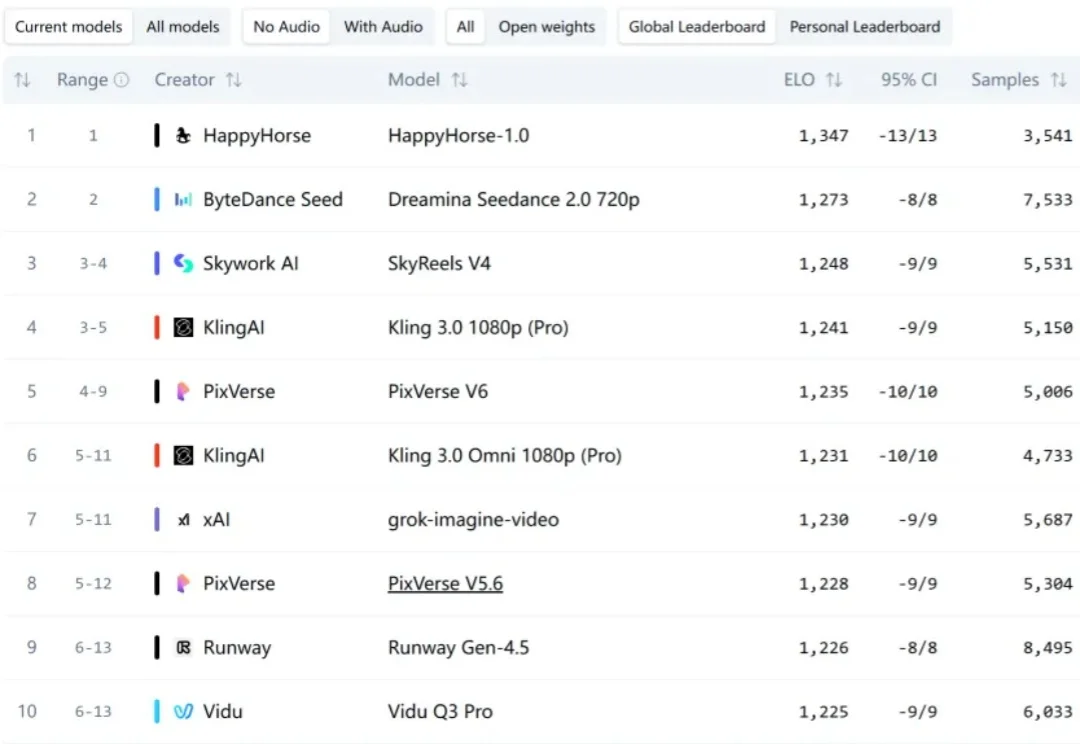
就在 OpenAI 都停了 Sora,所有人以为 Seedance 2.0 要一统天下的时候,没想到不知哪里冒出来一匹马。

LangChain 只换了模型外面的基础设施——同一个模型、同一套权重——就从 TerminalBench 2.0 排行榜 30 名开外直接跳到了第 5 名。另一个独立研究项目让大模型自己优化这层基础设施,达到了 76.4% 的通过率,超过了所有人工设计的方案。

最近Seedance 2.0接入大赛开始了,有头有脸的视频agent都当上字节中介原地起飞了。