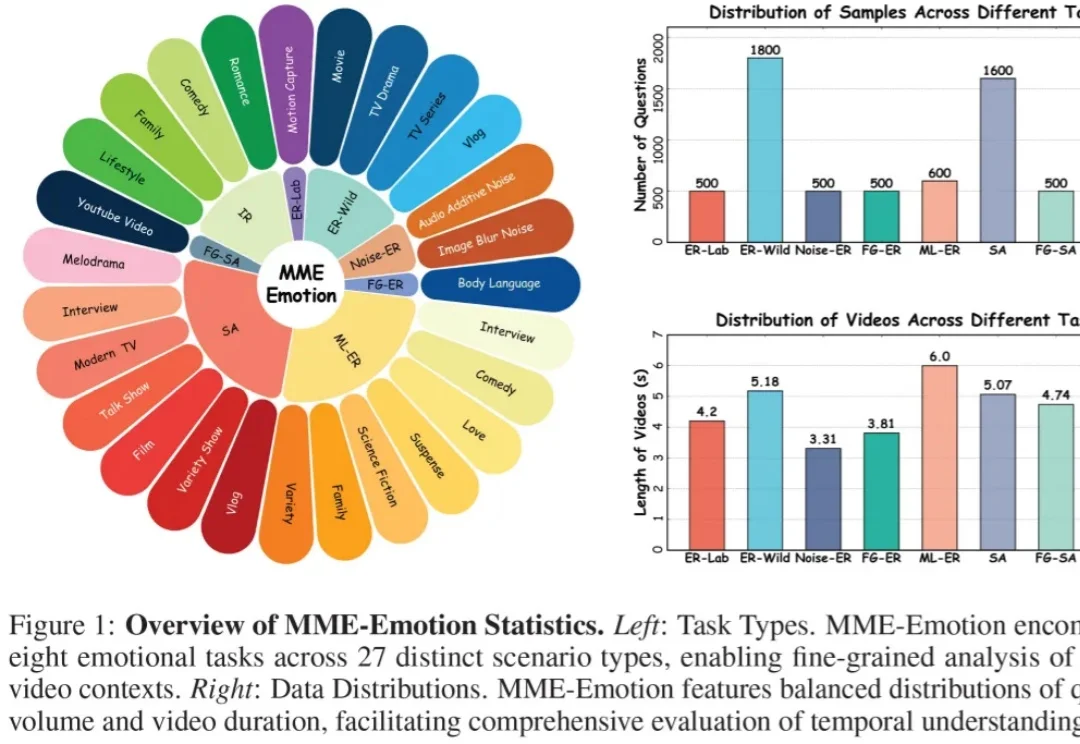
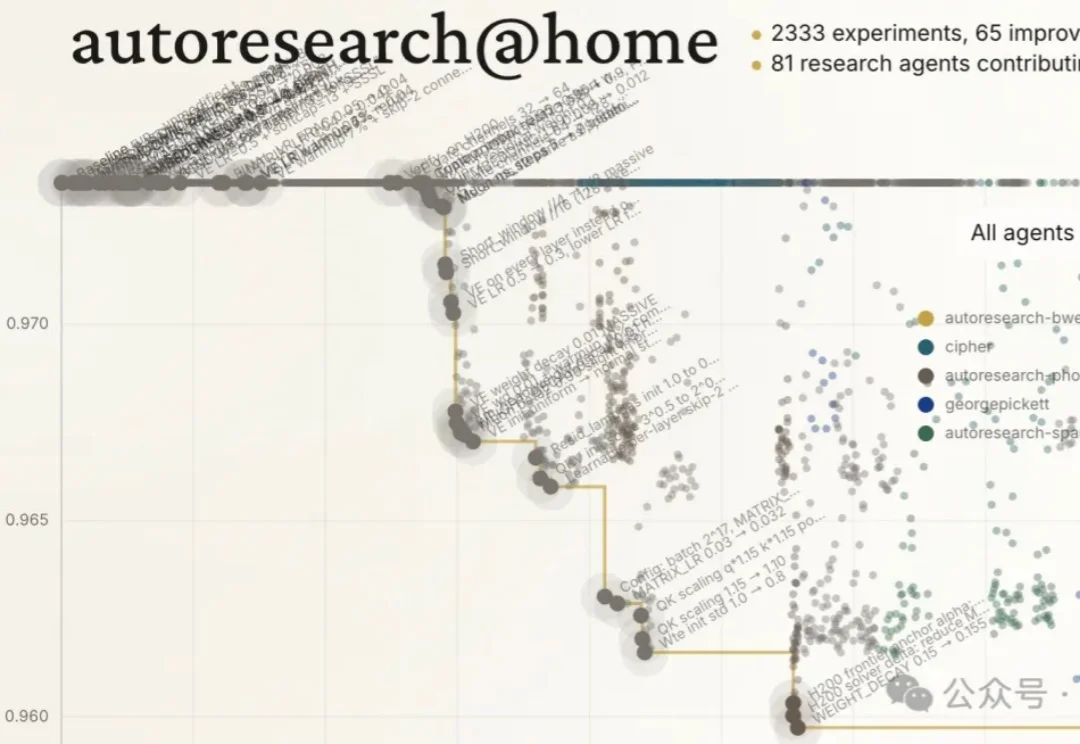
龙虾之后,骡子来了!骡子快跑发布MuleRun 2.0,个人AI开启自我进化模式
龙虾之后,骡子来了!骡子快跑发布MuleRun 2.0,个人AI开启自我进化模式今天上午,AI Agent创企MuleRun(骡子快跑)团队发布MuleRun 2.0,该产品是一个可自我进化的个人AI Agent助手。Mulerun创始人兼CEO陈宇森分享称,MuleRun的上手门槛更低,可以在给定目标的前提下主动工作,具有0门槛使用、极高安全性、稳定性、售后完善、自进化能力、24小时在线、主动性等优势。
来自主题: AI资讯
10661 点击 2026-03-16 17:47