
Meta再推WorldGen,简单一句话,竟「盖」出50×50米一座城
Meta再推WorldGen,简单一句话,竟「盖」出50×50米一座城Meta 用一段文本构建可探索的 3D 世界。 这就是 Meta 最新公布的一项突破性研究 WorldGen:只需一段文本提示就能生成真正可导航、可交互、可以走进去探索的完整 3D 世界。
来自主题: AI资讯
10248 点击 2025-11-22 15:29
 搜索
搜索
Meta 用一段文本构建可探索的 3D 世界。 这就是 Meta 最新公布的一项突破性研究 WorldGen:只需一段文本提示就能生成真正可导航、可交互、可以走进去探索的完整 3D 世界。

硅谷这帮人,胆子是真的大啊!一个几乎0模型、0产品的公司,就靠着创始人的出身,硬生生估值到500亿美元!Thinking Machines Lab又要融资了,这次要筹集40亿至50亿美元。
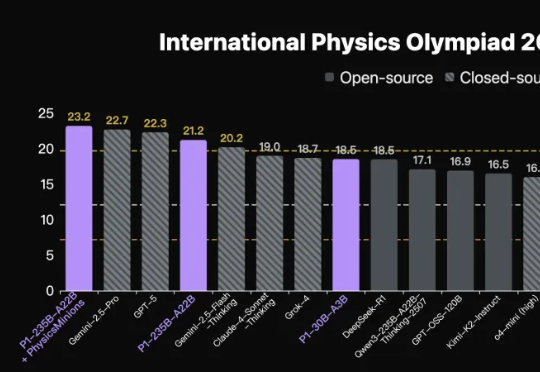
首个拿下国际物理奥林匹克竞赛IPhO 2025理论考试金牌的开源模型,出自国产。上海人工智能实验室团队推出新模型家族,代号P1。在IPhO 2025理论考试中,P1-235B-A22B取得21.2/30分,成为首个达到该金牌线的开源模型,仅次于Gemini-2.5-Pro与GPT-5。

导语 AI做短视频早已普及,但用AI生成精品短剧却门槛极高:一个2-3分钟的成片需要3-5天制作,调用七八种AI工具,每种工具都需要创作者几十小时的学习时间,还需要依赖创作者自身强大的叙事技巧和美术功
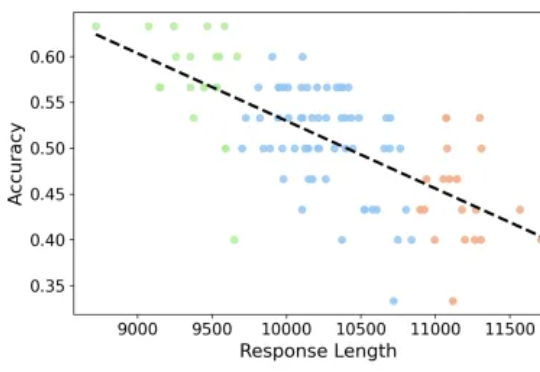
专注推理任务的 Large Reasoning Models 在数学基准上不断取得突破,但也带来了一个重要问题:越想越长、越长越错。本文解读由 JHU、UNC Charlotte 等机构团队的最新工作

前沿AI竞赛在2025年11月达到高潮。48小时内,谷歌推出Gemini 3 Pro宣称在主要推理基准测试中领先,而OpenAI立即用GPT-5.1-Codex-Max反击,这是一款专门训练用于通过创新"压缩"(compaction)技术自主工作超过24小时的专业编码模型[43]。加上Claude Sonnet 4.5已确立的编码统治地位和激进的安全过滤器,开发者面临前所未有的选择:

2025 年 11 月 20 日,英伟达公布最新季度财报,2025 年 Q3 营收为 570.06 亿美元,较上年同期的 350.82 亿美元增长 62%;净利润为 319.10 亿美元,较上年同期的 193.09 亿美元增长 65%。英伟达强大的吸金能力再次超出所有人的预期,三年前英伟达的同期营收仅是现在的十分之一。

谷歌乘胜追击!Gemini 3 Pro好评如潮没两天,最强文生图模型Nano Banana也推出Pro版本。
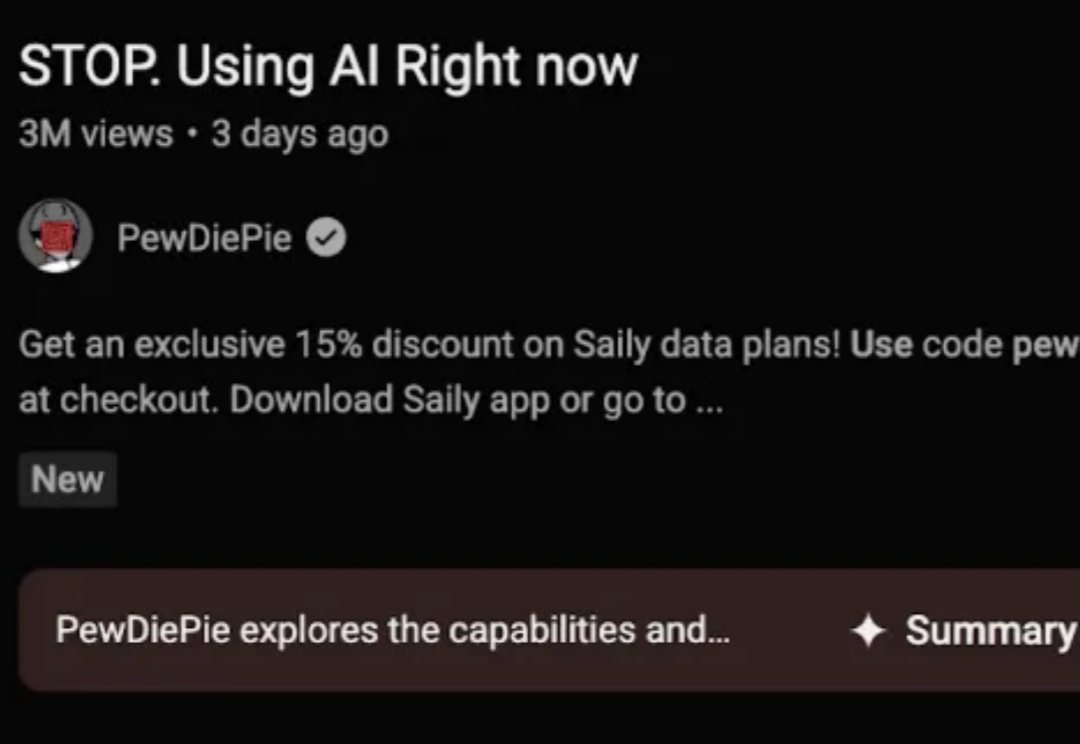
11 月 3 日,全球知名游戏博主 PewDiePie 发布视频,展示其自建本地 AI 系统的全过程。该视频目前浏览量已经超过 300 万,视频标题则赫然写着双关梗 “STOP: Using AI Right now”。
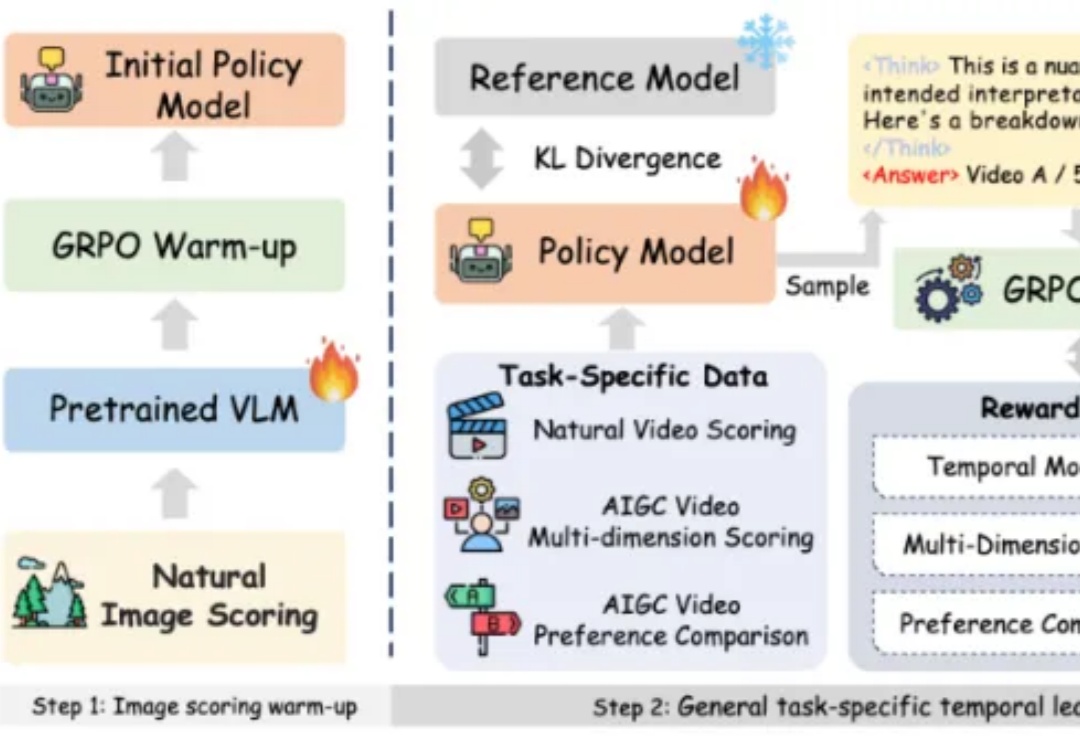
近日,AAAI 2026 公布了录用结果,该会议是是人工智能领域极具影响力的国际顶级学术会议之一。据悉本次会议共有 23680 篇投稿进入审稿阶段,最终 4167 篇论文被录用,录取率为 17.6%。