
大厂抢郭达雅进行时!DeepSeek核心成员还是个“综艺巨佬”
大厂抢郭达雅进行时!DeepSeek核心成员还是个“综艺巨佬”DeepSeek,又有核心工程师流入江湖—— 郭达雅,V2、V3、R1等一系列模型的核心作者,被曝离职。
来自主题: AI资讯
6591 点击 2026-03-23 10:21
 搜索
搜索
DeepSeek,又有核心工程师流入江湖—— 郭达雅,V2、V3、R1等一系列模型的核心作者,被曝离职。
2026 年,OpenClaw 引爆 AI 圈,但 B 站 UP 主开发的硬核 Agent 框架 AstrBot 早在 2023 年 1 月就发布了第一个版本。B 站是如何凭借独特的社区反馈机制,成为孕育 AI 技术落地的「第一现场」?

在此背景下,浙江大学研究团队提出了 EasySteer——一个基于 vLLM 构建的高性能、可扩展 LLM Steering 统一框架。该框架通过与 vLLM 推理引擎的深度集成,相比现有 Steering 框架实现了 10.8-22.3 倍的推理加速,同时提供更细粒度的干预控制,并为八大应用场景提供了预计算 Steering 向量与完整复现示例,方便研究者快速上手和对照复现。

3 月 20 日,知名 AI 代码编辑器 Cursor 高调发布了所谓的编程模型 Composer 2,结果被网友质疑「套壳」 Kimi K2.5。而从官方口径来看, Composer 2 的性能简直是降维打击:全基准大幅领先前代,首次引入持续预训练,叠加大规模强化学习,能解决需要数百个操作的高难度编程任务。
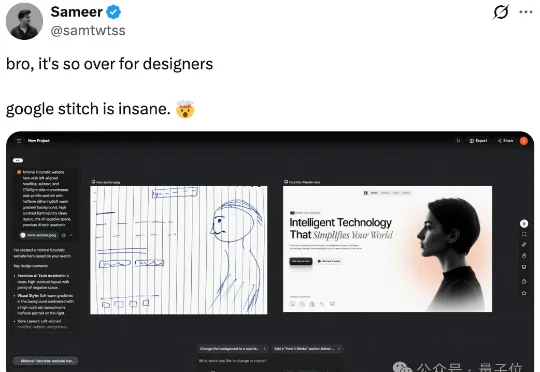
谷歌宣布旗下AI设计工具Stitch支持Vibe Design。你都不需要键盘,只需要用嘴就可以vide design出这样婶儿的UI和前端界面:不得不说,谷歌的审美是真的好。Gemini 3生成前端的艺术效果就有口皆碑。
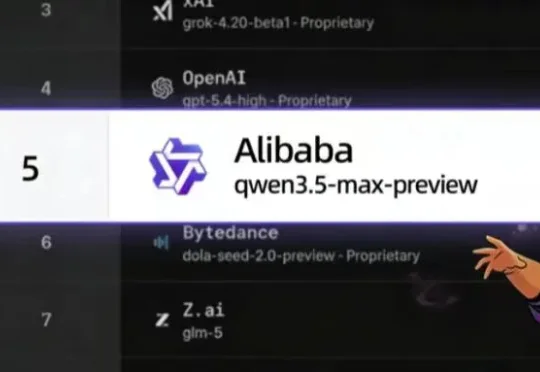
今日,阿里千问最新旗舰模型预览版Qwen3.5-Max-Preview正式亮相,并登上全球大模型评测平台LMArena。在最新榜单中,该模型拿下1464分,进入第一梯队,同时带动阿里千问跻身全球大模型实验室前五、国内第一。
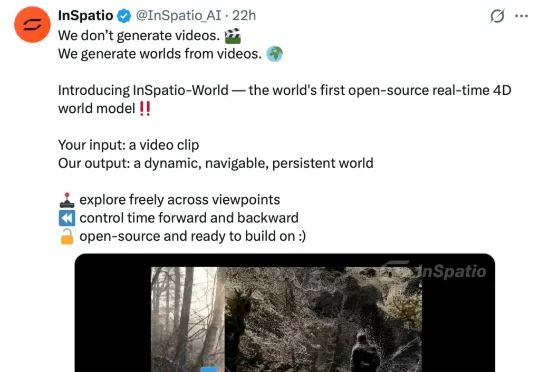
近日,影溯正式发布并开源世界模型 InSpatio-World,综合性能优异,在李飞飞牵头的权威世界模型榜单 WorldScore-Dynamic 中,力压其他实时 / 交互级推理速度的世界模型。它彻底摒弃了烧钱低效的纯 2D 视频路径,凭借更具第一性原理的 3D 空间架构,带来了可实时交互的动态世界。
2026年,AI成了科学家的新战友:从三个晚上破解40年优化难题,到18分钟重现黑洞隐藏对称性,ChatGPT正把前沿发现速度提升数倍乃至数十倍,科学加速的时代已然来临!

老黄又又又亲自上门送“显卡”了!
今天正式升级的飞书 aily,就是飞书给出的答案。飞书 aily 是什么?官方定位是「每个人的智能伙伴」。形态上,它以 Bot 的方式常驻在飞书联系人列表里,打开飞书就能找到,对话即交互。30 秒激活,零配置。