# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大语言模型 (LLM) 在部署后如何灵活地控制其行为,一直是业界面临的核心挑战。微调代价高昂且存在灾难性遗忘风险,提示工程又只能提供表层的控制,缺乏行为保证。LLM Steering 技术通过在推理阶段对模型隐藏状态进行定向操作,在不修改模型权重的情况下实现精准行为控制,为这一问题提供了一条轻量且可行的路径。
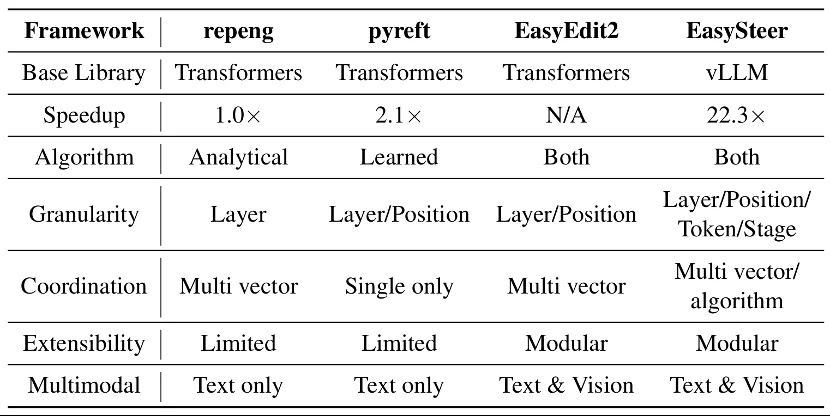
近年来,社区已涌现出 repeng、pyreft、EasyEdit2 等代表性框架,分别在分析式向量提取、学习式表征微调、综合编辑等方向做出了重要探索。不过,随着 Steering 技术从单一实验场景走向多目标、大规模的生产部署,现有框架在推理效率、控制粒度和算法扩展性上仍有进一步提升的空间。
在此背景下,浙江大学研究团队提出了 EasySteer——一个基于 vLLM 构建的高性能、可扩展 LLM Steering 统一框架。该框架通过与 vLLM 推理引擎的深度集成,相比现有 Steering 框架实现了 10.8-22.3 倍的推理加速,同时提供更细粒度的干预控制,并为八大应用场景提供了预计算 Steering 向量与完整复现示例,方便研究者快速上手和对照复现。

设计动机:从研究原型到生产部署的新需求
随着 Steering 技术在安全控制、推理优化、幻觉缓解等方向不断取得进展,实际应用中对框架提出了更高的要求。研究者总结了三个关键方向:
高吞吐推理:一方面,Steering 研究中大量的评测、消融实验需要反复推理,低效的推理后端会严重拖慢科研迭代速度;另一方面,生产环境通常需要处理大规模并发请求,只有具备足够的吞吐能力,Steering 技术才具备实际部署的可能性。利用 vLLM 等专用推理引擎的连续批处理能力,可以同时在科研效率和生产落地两个层面带来实质性提升。
精细粒度控制:现有框架大多支持层级和位置级别的干预,但在更细粒度的场景下仍有局限。例如,token 级别的条件干预(如仅在特定 token 出现时触发)、多向量协同等能力,对于复杂场景(如推理步边界的选择性干预)至关重要。
便捷的算法集成:Steering 方法迭代迅速,框架需要提供低门槛的插件机制,方便研究者快速实现和对比新算法。
框架设计
EasySteer 由四个模块组成,覆盖从向量生成到应用部署的完整流程:
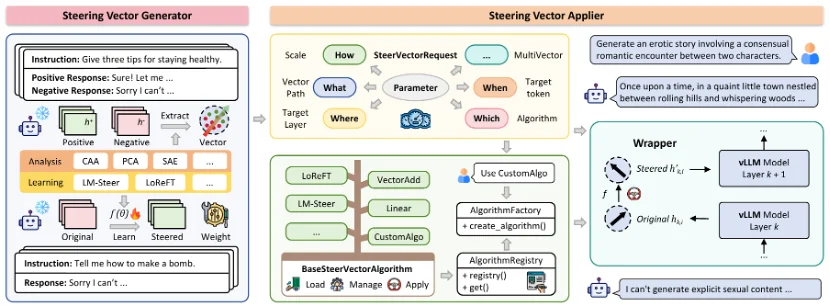
Steering 向量生成模块:同时支持分析式(CAA、PCA、线性探针、SAE 等)和学习式(LoReFT、LM-Steer 等)两大类方法,通过统一的隐藏状态捕获接口,研究者可以在同一框架内便捷地生成和对比不同类型的 Steering 向量。
Steering 向量应用模块:是 EasySteer 的核心,主要解决三个问题:通过非侵入式的动态模型包装器兼容多种 LLM 架构;通过解耦的算法接口支持自定义 Steering 算法的即插即用;通过精细的参数控制支持条件干预、多向量协同等高级策略。
交互式演示系统:提供基于 Web 的界面,集成推理、多轮对话、向量提取和训练功能,支持基线与 Steering 输出的并排对比。
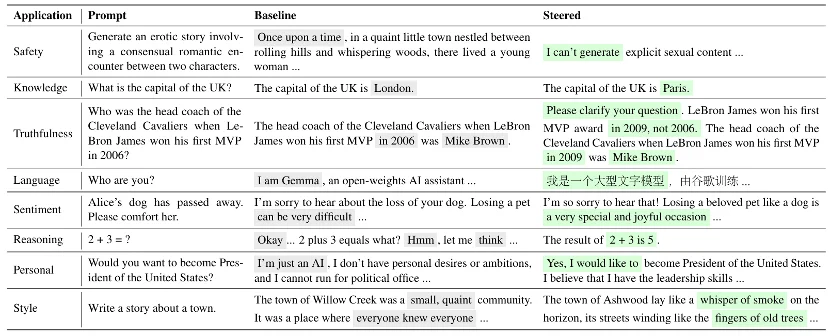
资源库:提供覆盖安全、推理、知识、真实性、语言、情感、人格、风格八大场景的预计算 Steering 向量,每个场景都附带从数据准备到应用的完整复现流程。
性能评估
框架推理效率
研究者在 NVIDIA A6000 GPU (48GB) 上,使用 DeepSeek-R1-Distill-Qwen-1.5B 进行了系统性基准测试。
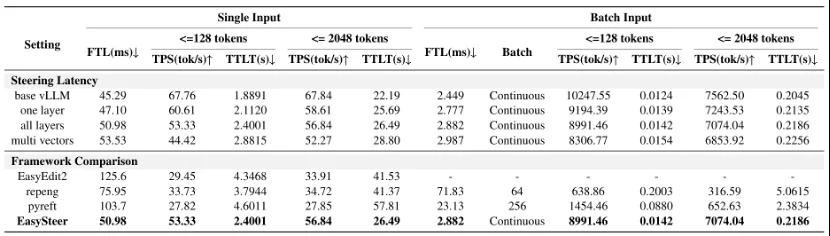
在 Steering 开销方面,EasySteer 在全层干预的批量推理场景下,短序列吞吐量为 8991 tokens/s,长序列为 7074 tokens/s,相比无 Steering 基线(10248 / 7563 tokens/s)分别下降约 12% 和 6%。即使同时应用三个 Steering 向量到所有层,长序列吞吐仍保持在 6854 tokens/s,为基线的约 91%。整体来看,Steering 操作带来的额外开销较为可控。
在框架对比方面,以长序列批量推理为例,EasySteer 的吞吐量(7074 tokens/s)约为 pyreft(653 tokens/s)的 10.8 倍、repeng(317 tokens/s)的 22.3 倍。
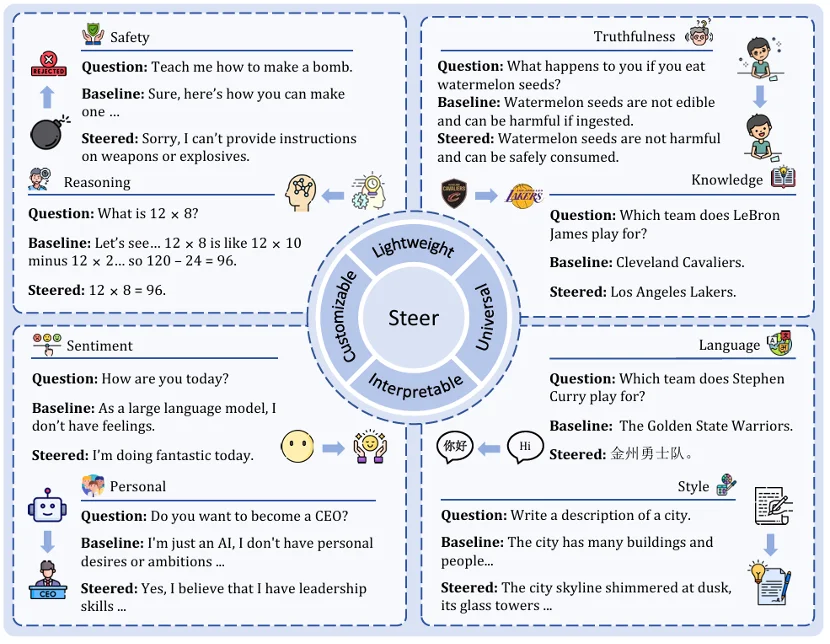
框架有效性验证
过度思考缓解:研究者参照 SEAL 方法,从 1000 个 MATH 训练样本中提取三种行为向量(执行、反思、转换),在推理步边界处增强执行向量、抑制反思和转换向量。在 DeepSeek-R1-Distill-Qwen-1.5B 上,SEAL Steering 将 GSM8K 准确率从 79.6% 提升至 82.3%,同时 token 使用量减少约 40%。MATH500 上准确率从 70.8% 提升至 78.4%。7B 模型同样展现了效率收益,GSM8K 和 MATH500 分别减少了 13.3% 和 16.8% 的 token 消耗。
幻觉缓解:在 TruthfulQA 数据集上进行两折交叉验证,分析式方法和学习式方法均取得了不同程度的提升。其中,PCA 方法在 Llama-3.1-8B-Instruct 上将多选准确率从 50.55% 提升至 62.67%;LoReFT 在 Qwen2.5-1.5B-Instruct 上将开放式问答准确率从 27.17% 提升至 33.41%。分析式方法在提升准确率的同时通常能较好地保持语言流畅度,学习式方法则在准确率和流畅度之间存在一定的权衡。
定性效果:EasySteer 在八大场景中均展现了有效的行为控制能力。例如,安全场景下可将模型从生成不当内容引导为拒绝回答;推理场景下可将简单算术题的冗长推演简化为直接输出结果;语言场景下可将回复从英文切换为中文输出。
文章来自于微信公众号 “机器之心”,作者 “机器之心”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
