直观即时绘制3D模型,可添加文本提示,VAST又开源了
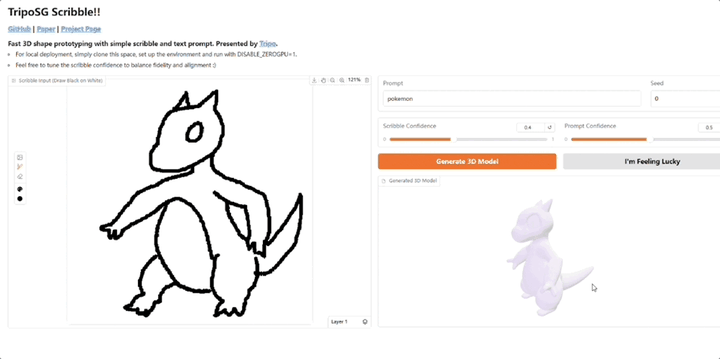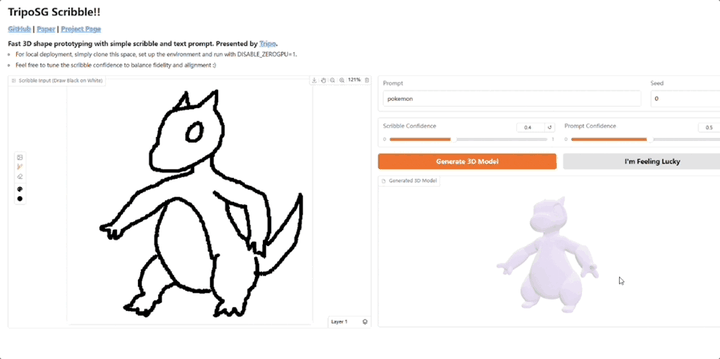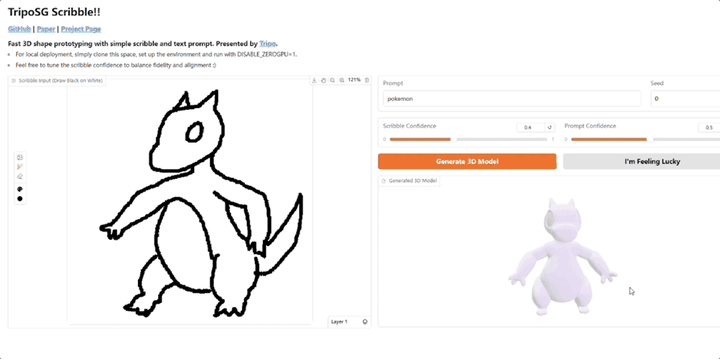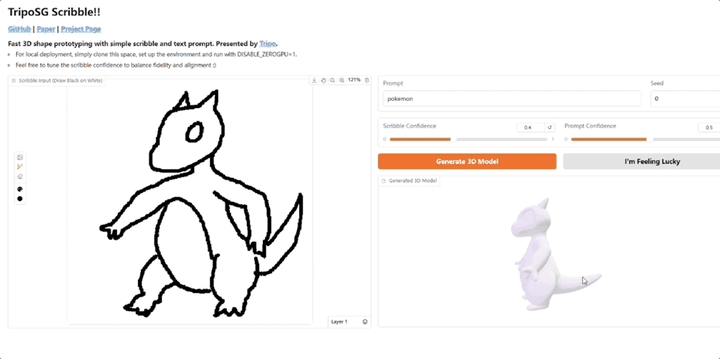
直观即时绘制3D模型,可添加文本提示,VAST又开源了3D生成明星玩家VAST,又又又又又开源了!Tripo Doodle(内部代号TripoSG Scribble) ,能够将简单的2D草图和文本提示(Text Prompt)实时转化为精细的3D模型。它改进了传统3D建模学习曲线陡峭、耗时耗力的痛点,尤其是在初期“打形”阶段。
来自主题: AI资讯
10520 点击 2025-04-21 21:05
 搜索
搜索
3D生成明星玩家VAST,又又又又又开源了!Tripo Doodle(内部代号TripoSG Scribble) ,能够将简单的2D草图和文本提示(Text Prompt)实时转化为精细的3D模型。它改进了传统3D建模学习曲线陡峭、耗时耗力的痛点,尤其是在初期“打形”阶段。

具身智能的突破离不开高质量数据。目前,具身合成数据有两条主要技术路线之争:“视频合成+3D重建”or “端到端3D生成”。英伟达在CES 2025指出“尚无互联网规模的机器人数据”,自动驾驶已具备城市级仿真,但家庭等复杂室内环境缺乏3D合成平台。
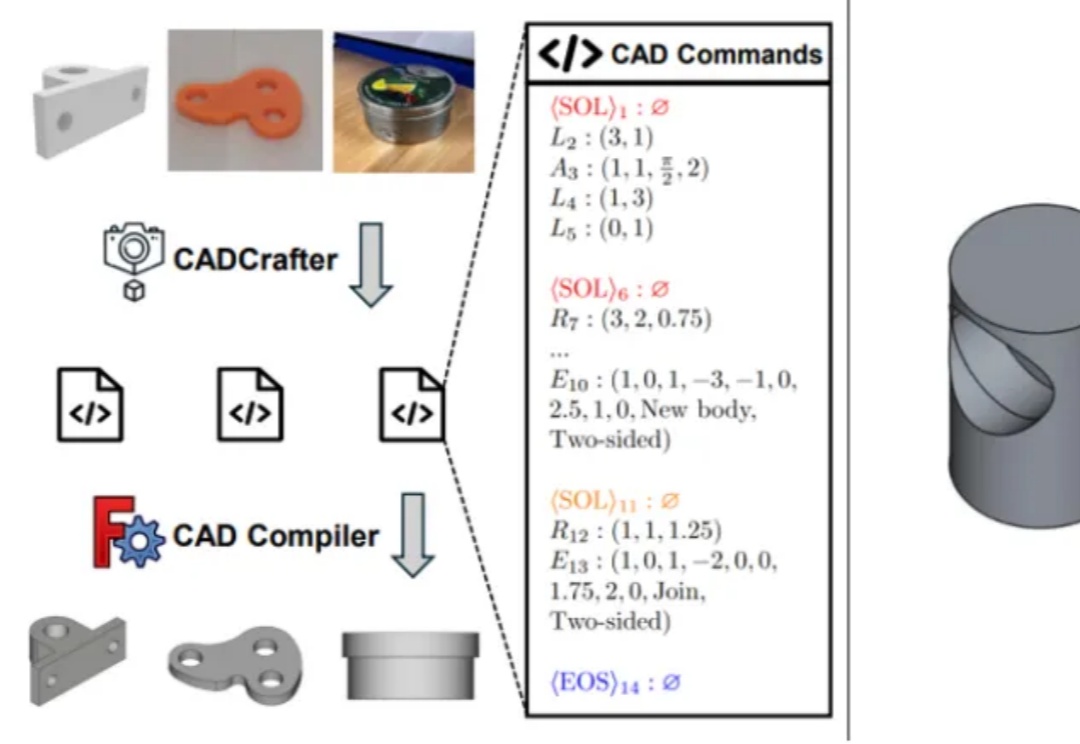
单张图直接就能生成可编辑的CAD工程文件!

前些天,GPT-4o的多模态生图上线之后,引发全球AI社区广泛的关注,吉卜力图画全网风靡。

仅用4090就能实现大规模城市场景重建!

面向3D生成,来自VAST和清华大学的自动绑骨框架开源了!3D内容创作领域正经历前所未有的爆发,无论是成熟的传统工作流,还是以VAST(Tripo)为代表的AI驱动生成工具的飞速发展,都体现了市场对高质量3D资产需求的日益激增

在现实世界中,如何让智能体理解并挖掘 3D 场景中可交互的部位(Affordance)对于机器人操作与人机交互至关重要。所谓 3D Affordance Learning,就是希望模型能够根据视觉和语言线索,自动推理出物体可供哪些操作、以及可交互区域的空间位置,从而为机器人或人工智能系统提供对物体潜在操作方式的理解。

世界模型领域最新进展,要比拼“世界生成”了。

北京大学陈宝权教授团队提出RainyGS技术,通过结合物理模拟和3D高斯泼溅渲染框架,实现了真实场景中动态雨效的高质量仿真与呈现,真正实现「从真实到真实」,或者「以仿真乱真」,即Real2Sim2Real !相比现有的视频编辑工具(如 Runway),其物理真实性获得保证。

随着 VR/AR、游戏娱乐、自动驾驶等领域对 3D 场景生成的需求不断攀升,从稀疏视角重建 3D 场景已成为一大热点课题。