# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文主要作者是 Bytedance Pico 北美高级研究员胡涛博士,近年来研究领域包括3D 重建与 4D 场景和视频生成,致力于得到一种最佳的物理世界表示模型。其他作者均为 Pico MR 团队核心成员。
去年一年来,Sora、可灵、Veo 等模型掀起了视频生成领域的革新。而在构建更逼近真实的世界模型征程中,相机可控的视频生成技术堪称核心拼图 —— 它让视频生成模型不再是单向的 “世界模拟器”,而是能被用户自由探索的 “平行宇宙”,为沉浸式 3D 电影等颠覆性应用奠定基础!
然而,从单视角视频,生成其对应的极端视角(比如方位角在 ±90° 改变)新视频仍是行业难题。现有的开源方法或依赖多视角相机 - 视频数据集训练 [4,5],或受困于遮挡区域表示的局限 [1,2],难以跨越 “视角自由” 与 “物理真实” 的双重鸿沟。
对此,PICO-MR 团队提出了一个破局方案:EX-4D,可以从任意单目视频生成其对应的新视角视频。EX-4D:


现有方法的困境
目前相机可控的视频生成方法可分为 2 种主要思路。一类方法直接利用相机外参作为条件控制视角生成。这种方法需要自行构建多个视角下的相机 - 视频数据对,并且难以控制不同数据分布下的相机的位移尺度,在未知分布的视频输入上可能出现严重的视角偏移。第二类方法则直接将像素点投影成点云作为额外的先验信息。这些点云投影无法保留物体之间的遮挡关系,在物体的交界部分非常依赖基座模型本身的能力。这种不可控性容易导致错误的几何关系。
EX-4D 的三大核心设计
EX-4D 的核心目标是实现一个泛用的,从单目视频生成新视角下视频的模型。其总体框架如下图所示:
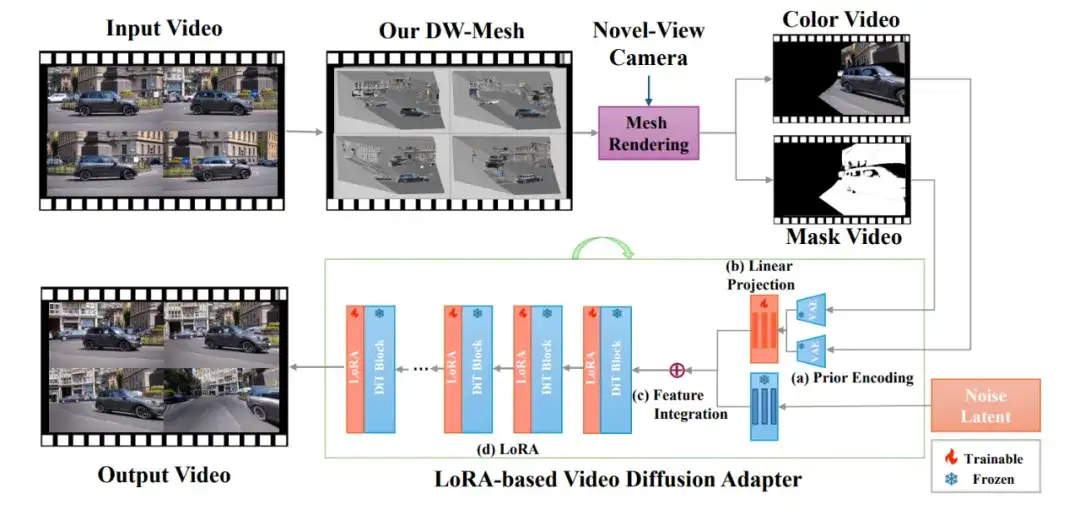
为了充分利用丰富的各类视频数据,同时保证生成视频满足高质量和高物理一致性,EX-4D 提出了如下三个关键设计。
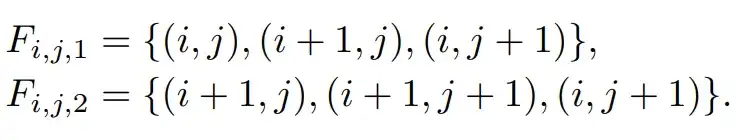
EX-4D 根据几何关系标记遮挡面片。通过设置当面片最小角度小于指定阈值,或者跨度大于指定阈值时,可以提取出前景与背景之间的遮挡面。
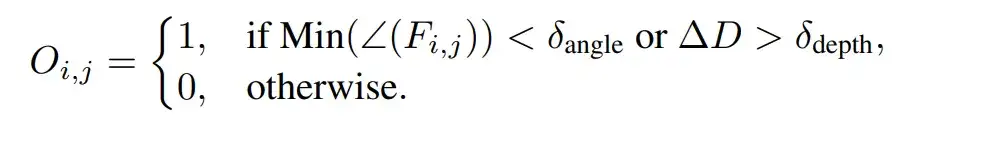
生成的 DW-Mesh 表达能为每一帧提供连续的遮挡 mask,以此确保极端视角下的生成视频的物理一致性。

添加图片注释,不超过 140 字(可选)
借助这两种生成策略,无需昂贵多视角采集,仅凭单目视频就能 “脑补” 全视角数据,破解世界模型训练的数据困局!
实验结果:EX-4D 如何定义「极致」
为了展示 EX-4D 在新视角生成的巨大潜力,EX-4D 使用包含 150 个网络视频的数据集,并使用 FID、FVD 和 VBench [6] 等指标评估模型性能。
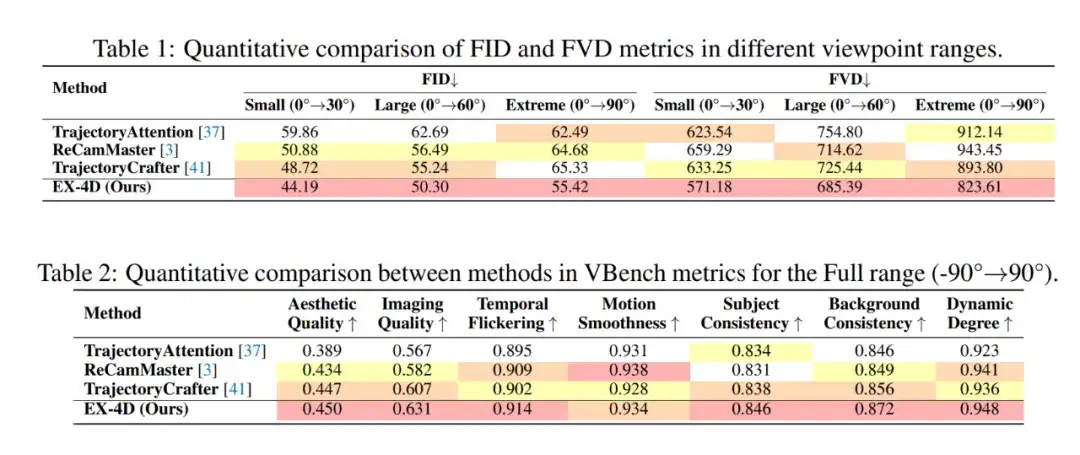
在各种视角跨度范围之内,EX-4D 均全面超越了现有的开源可控视角生成方法。值得关注的是,新输入视角角度越极端(越偏向 90°),EX-4D 性能优势越明显,充分展示了 DW-Mesh 表示在物理一致性保持上的潜力。在 VBench 指标上,EX-4D 在绝大多数指标上取得最高分,进一步展现了强大的综合生成能力。
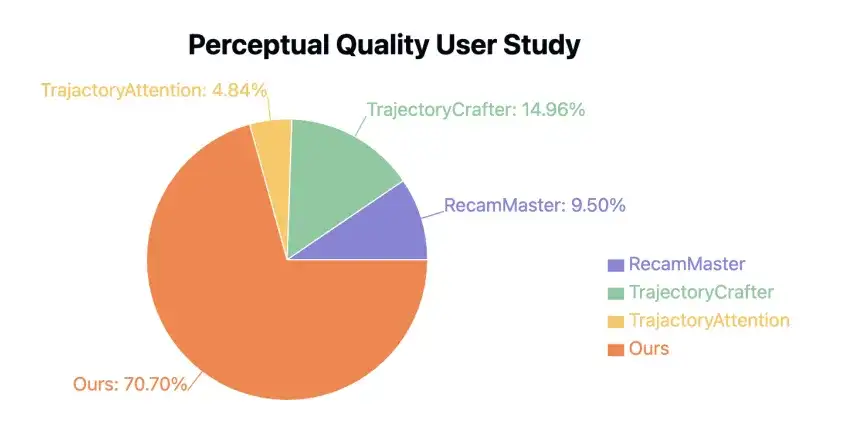
此外,EX-4D 还邀请了 50 位志愿者对 EX-4D 和其他开源方法的生成效果进行评分。70.70% 的参与者认为 EX-4D 方法在极端视角下的物理一致性断层领先。
当已有的开源方法在剧烈视角变化中 “露破绽”(物体穿帮、遮挡错乱),EX-4D 却能精确保留高一致性的物体细节。

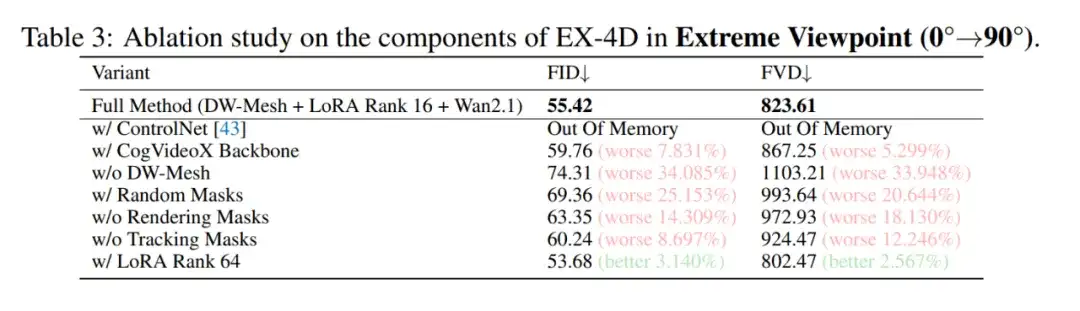
针对 EX-4D 的充分消融实验充分论证 EX-4D 中每种策略的有效性。其中 DW-Mesh 表示对性能的提升最大。两种针对训练数据的 mask 生成策略对于模型的训练都至关重要。而 EX-4D 采用的 16 rank 轻量级 LoRA-based Adapter 效率已经足够高,增加 rank 仅带来轻微性能提升。
总结与未来展望
定性和定量实验说明,EX-4D 方法能够生成高物理一致性、高质量的视频结果,并且可以广泛用于小角度偏移到极端视角的各种场景,提升了新视角预测的自由度。后续的视频可控生成之中,EX-4D 将着眼于提高深度预测的精度,并提高模型推理速度,向更快、更好的可控视频生成进发,为世界模型助力。
参考文献
[1] Mark YU, Wenbo Hu, Jinbo Xing, and Ying Shan. Trajectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models, 2025.
[2] Zeqi Xiao, Wenqi Ouyang, Yifan Zhou, Shuai Yang, Lei Yang, Jianlou Si, and Xingang Pan. Trajectoryattention for fine-grained video motion control. In The Thirteenth International Conference on Learning Representations, 2025.
[3] Nikita Karaev, Iurii Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Cotracker3: Simpler and better point tracking by pseudo-labelling real videos. In Proc. arXiv:2410.11831, 2024.
[4] Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation. arXiv preprint arXiv:2404.02101, 2024.
[5] Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, and Di Zhang. Recammaster: Camera-controlled generative rendering from a single video, 2025.
[6] Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench: Comprehensive benchmark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024.
文章来自公众号“机器之心”


