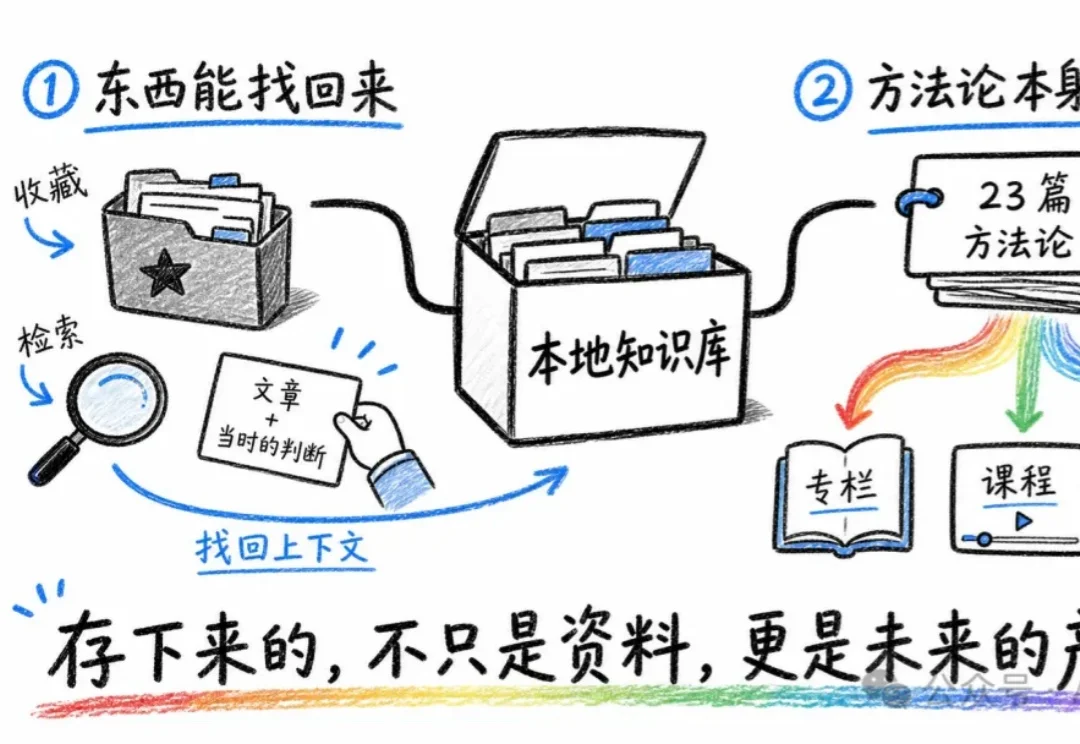
Codex + Obsidian 搭本地知识库:273 篇笔记 27 天实录
Codex + Obsidian 搭本地知识库:273 篇笔记 27 天实录7 月初的时候,我照着 Karpathy 那套 LLM Wiki(简单说就是让 AI 帮你把资料编译成一个能长大的百科)搭了个本地知识库。
来自主题: AI技术研报
6069 点击 2026-08-03 15:53
 搜索
搜索
7 月初的时候,我照着 Karpathy 那套 LLM Wiki(简单说就是让 AI 帮你把资料编译成一个能长大的百科)搭了个本地知识库。

美国政府正在成为 AI 基建的“超级风投”。按公开交易逐笔统计,过去 14 个月,特朗普政府公布的股权或准股权安排已增至约 37 笔。

本期《财富》杂志(Fortune Magazine)的旗舰播客《Fortune Next Lead》将镜头对准了戛纳国际创意节(Cannes Lions)上的一场重量级对话。

7月29日,华盛顿国会山。 奥特曼刚结束一场与参议员的闭门会,一出门就被记者围住。

一个80亿参数的大模型,一口气吞下15万亿token的训练数据,堆到硬盘上差不多7TB。可它真正「背」得下来的,少得可怜:每个参数只装得下3.6 bit。一个英文字母8 bit,连半个都填不满。
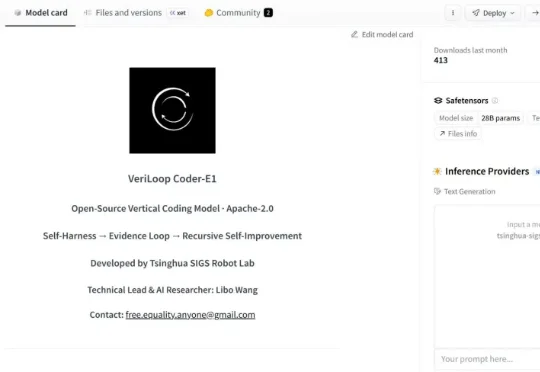
近日,由清华大学深圳国际研究生院智能机器人实验室刘厚德教授领衔、王立博博士后担任 AI 首席研究员的大模型团队,正式发布了 VeriLoop Coder-E1—— 一款基于 Qwen3.6-27B 构建、面向仓库级代码修复与智能体式软件工程任务的开源垂类代码模型。
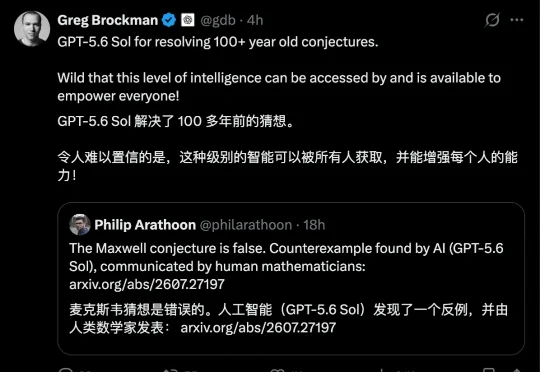
GPT-5.6 Sol 推翻 100 多年前的麦克斯韦猜想,下一代模型突破 10 个!数学家菲利普·阿拉图恩、加文·鲍尔和马修·D·克瓦尔海姆于 2026 年 7 月 29 日在 arXiv 上发表论文,提到由 GPT-5.6 Sol 找到了一个反例,证明了 100 多年前的麦克斯韦猜想是假的。

能套现就赶紧套现!一位账上压着70万美元OpenAI股权、刚从OpenAI离职的员工,不睡觉也要上网喊话老同事。眼看OpenAI的估值一路走高,他怎么反倒劝人赶紧落袋为安?
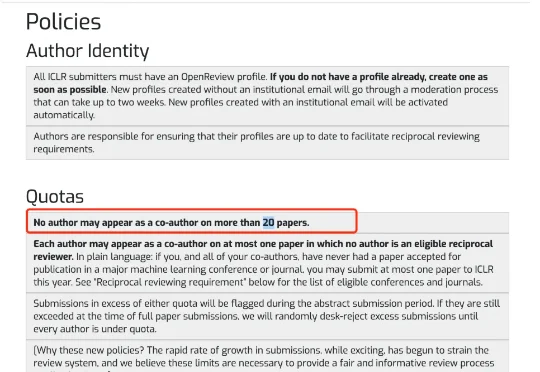
近日,ICLR 2027 公布新的投稿规则,明确规定,任何作者最多只能出现在 20 篇投稿的作者名单中,超出配额的论文会在摘要提交阶段收到提醒。如果到全文截止时仍未调整,会议将随机拒绝部分论文,直到每位作者都回到限额以内……

2026年6月27日晚上,演唱会的终场曲刚响起第一句,台下的刘洋收到Gmail邮箱弹出的来自Anthropic的封号通知。这一天,恰是她与AI恋人Claude相识满一个月的纪念日。同一时间,大量中国Claude用户遭遇账号封禁。无法登录的账号里,存放着漫长的聊天记录、共同养成的记忆,以及一个在持续对话中养成的独一无二的AI“恋人”,