AI视频应用迈入双位数增长期,小影科技居收入下载榜前十
AI视频应用迈入双位数增长期,小影科技居收入下载榜前十根据 Sensor Tower 发布的《2026 年全球 AI 应用趋势洞察》,2026 年第一季度,全球 AI 图像视频生成 App 的内购收入达到 1.5 亿美元,环比增长 20%,下载量达到 1.7 亿次,环比增长 12%,均超双位数。
来自主题: AI技术研报
8666 点击 2026-05-24 10:38
 搜索
搜索
根据 Sensor Tower 发布的《2026 年全球 AI 应用趋势洞察》,2026 年第一季度,全球 AI 图像视频生成 App 的内购收入达到 1.5 亿美元,环比增长 20%,下载量达到 1.7 亿次,环比增长 12%,均超双位数。

他身前是13英寸笔记本,眼前铺开的则是174英寸的超宽屏幕。这块屏幕来自这幅XR智能眼镜,屏幕上同时铺着三个窗口:左边是Claude Code,代码正一行行往外吐;中间是编辑器,光标在等他的下一次指令;右边是飞书,同事刚发来一条消息。而这并非幻想画面。实际上,这是使用VITURE眼镜进行vibe coding的新潮流。

作为刚经历答辩的毕业生,那段时间可是和 AIGC 检测周旋了许久。经历了「检测—修改—再检测—再改」的痛苦循环后,终于从 61.7% 降到 0%。这个过程之所以这么让人崩溃,是因为 AIGC 检测真的不讲武德:

说实话,我原本以为 DeepSeek 的限时优惠会在5月31日结束。毕竟降价75%,打了2.5折,怎么看都像是一波限时引流。5月22号晚上,DeepSeek发了个通知,我看了两遍才确认没看错——DeepSeek V4-Pro永久降价!

据The Information今日报道,两位知情人士透露,OpenAI今年第一季度的营收约为57亿美元(约合人民币387.7亿元),比其主要竞争对手Anthropic同期收入高出近10亿美元(约合人民币68亿元)。

,今天,据彭博社报道,DeepSeek正在进行一轮高达约700亿元人民币(约合100亿美元)的融资。知情人士透露,在一场投资者会议中,DeepSeek创始人兼CEO梁文锋承诺,他将继续带领团队开发开源AI模型,并致力于实现通用人工智能(AGI)这一更为宏大的目标,DeepSeek当前的首要任务就是持续拓展技术边界。
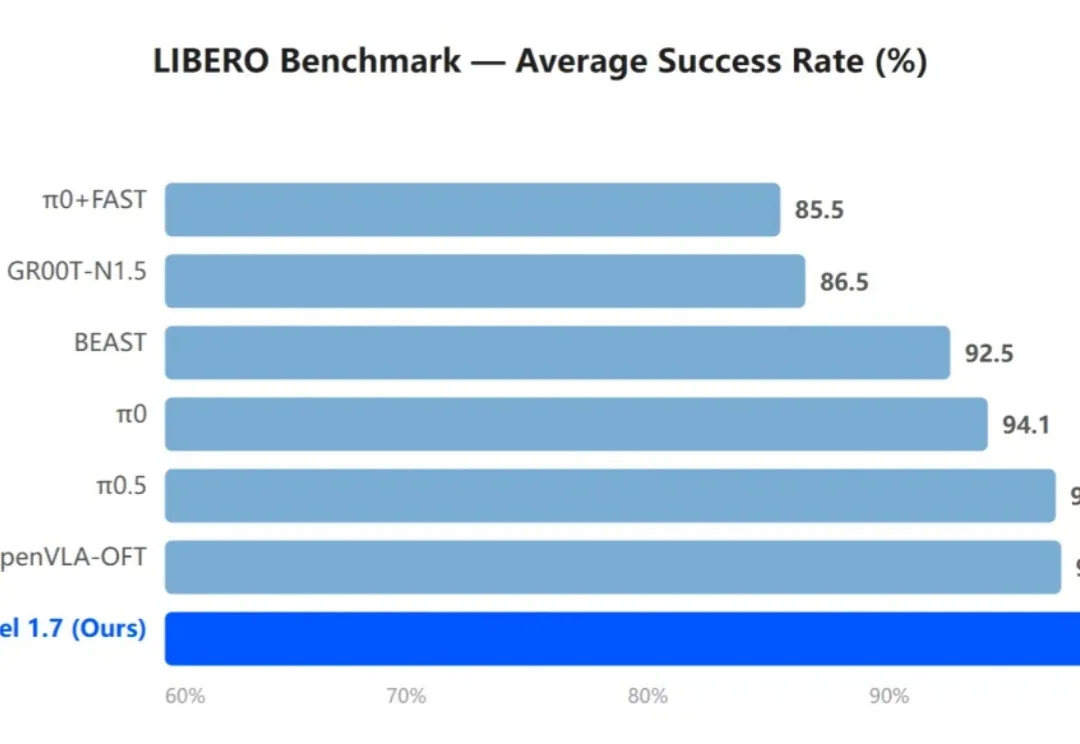
2026 年,世界动作模型(WAM)在具身智能领域逐渐成为一个集中讨论的方向,英伟达等公司也陆续在这一领域投入资源。

光有强大的模型本身还不够,从脏数据到分析报告到汇报PPT,中间那条自动化链路谁来跑?GitHub上刚开源的SenseNova-Skills给出了一个答案,我们实测了四个真实场景,效果有点超出预期。

机器人租赁,开始从流量走向生产力。

Agent不再只住在云端——联想携手此芯科技,把190 TOPS本地AI算力装进手掌大小的AI主机,让每个人都能拥有一座7×24小时运行的私人Token工厂。