
GPT-4o 语音模式终于来了,首批测试网友已经玩疯了
GPT-4o 语音模式终于来了,首批测试网友已经玩疯了赶在 7 月结束前,GPT-4o 语音功能终于开启。现开启灰度测试,一小部分 ChatGPT Plus 用户已经可以试用。
来自主题: AI资讯
7648 点击 2024-08-01 11:52
 搜索
搜索
赶在 7 月结束前,GPT-4o 语音功能终于开启。现开启灰度测试,一小部分 ChatGPT Plus 用户已经可以试用。

7 月,大模型公司 Cohere 宣布 D 轮融资 5 亿美元,估值 55 亿,比去年高了一倍多。 跟 OpenAI、Anthropic 甚至法国 AI 公司 Mistral 相比,成立于加拿大的 Cohere 略显低调,没有推出自己的 Chatbot、文生图或者文生视频产品,不涉足个人消费端产品;即使是推出的开源大模型 Command R+,似乎也没有那么引人注意。
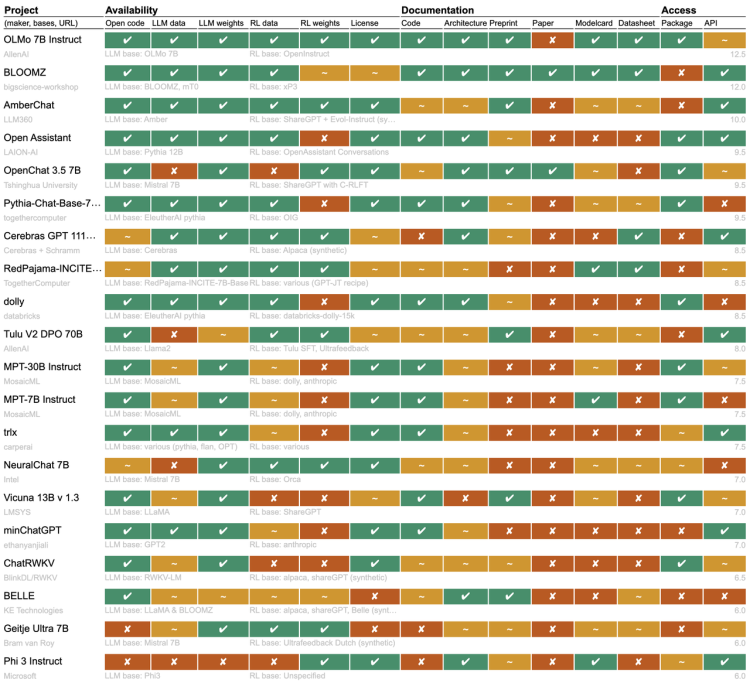
最近一段时间开源大模型市场非常热闹,先是苹果开源了70亿参数小模型DCLM,然后是重量级的Meta的Llama 3.1 和Mistral Large 2相继开源,在多项基准测试中Llama 3.1超过了闭源SOTA模型。 不过开源派和闭源派之间的争论并没有停下来的迹象。

7月31日,阿里通义宣布免费开放奥运AI大模型,具备奥运专业知识,并集合同声传译级别的中法互译功能。即日起,用户可以在通义APP免费使用。

智东西7月31日消息,根据顶级学术期刊《自然》(Nature)昨日报道,生成式AI在学术写作中的使用已迎来爆发式增长。相关研究显示生物医学领域最大数据库PubMed上10%的论文摘要都有AI写作嫌疑,相当于每年15万篇论文中都有AI的参与。

在 2024 年全球开发者大会上,苹果重磅推出了 Apple Intelligence,这是一个全新的个性化智能系统, 可以提供实用的智能服务,覆盖 iPhone、iPad 和 Mac,并深度集成在 iOS 18、iPadOS 18 和 macOS Sequoia 中。

Meta、UC伯克利、NYU共同提出元奖励语言模型,给「超级对齐」指条明路:让AI自己当裁判,自我改进对齐,效果秒杀自我奖励模型。

苹果AI首登iPhone!47页论文曝自研模型,多项测评超GPT-4。

今早,所有开发者们被突如其来iOS 18.1测试版砸晕了!没想到,苹果AI这就可以上手尝鲜了,一大波测评刷屏全网。更惊喜的是,苹果AI背后的基础模型47页技术报告,也一并上线了。

7月30日,生数科技的视频生成大模型 Vidu 面向全球正式上线。