
「越狱」事件频发,如何教会大模型「迷途知返」而不是「将错就错」?
「越狱」事件频发,如何教会大模型「迷途知返」而不是「将错就错」?大型语言模型(LLM)展现出了令人印象深刻的智能水平。因此,确保其安全性显得至关重要。已有研究提出了各种策略,以使 LLM 与人类伦理道德对齐。然而,当前的先进模型例如 GPT-4 和 LLaMA3-70b-Instruct 仍然容易受到越狱攻击,并被用于恶意用途。
来自主题: AI技术研报
10363 点击 2024-07-30 16:55
 搜索
搜索
大型语言模型(LLM)展现出了令人印象深刻的智能水平。因此,确保其安全性显得至关重要。已有研究提出了各种策略,以使 LLM 与人类伦理道德对齐。然而,当前的先进模型例如 GPT-4 和 LLaMA3-70b-Instruct 仍然容易受到越狱攻击,并被用于恶意用途。

自 1974 年在科罗拉多州博尔德市首次举办以来,SIGGRAPH一直是展示计算机图形领域开创性研究的一个主要平台。

7月26日到29日,是一年一度的ChinaJoy。

7月27日,与ICLR(国际学习表示会议)、NeurIPS(神经信息处理系统会议)并称三大机器学习顶级会议的ICML(国际机器学习大会),在奥地利维也纳会展中心落下帷幕。

只用1890美元、3700 万张图像,就能训练一个还不错的扩散模型。

OpenAI员工离职创业,AI帝国估值达600亿美元。
7月26日,智谱AI 推出视频生成产品「清影」,已上线可免费使用。这无疑给上半年越演越烈的AI视频生成产品的竞争又加了一把火。
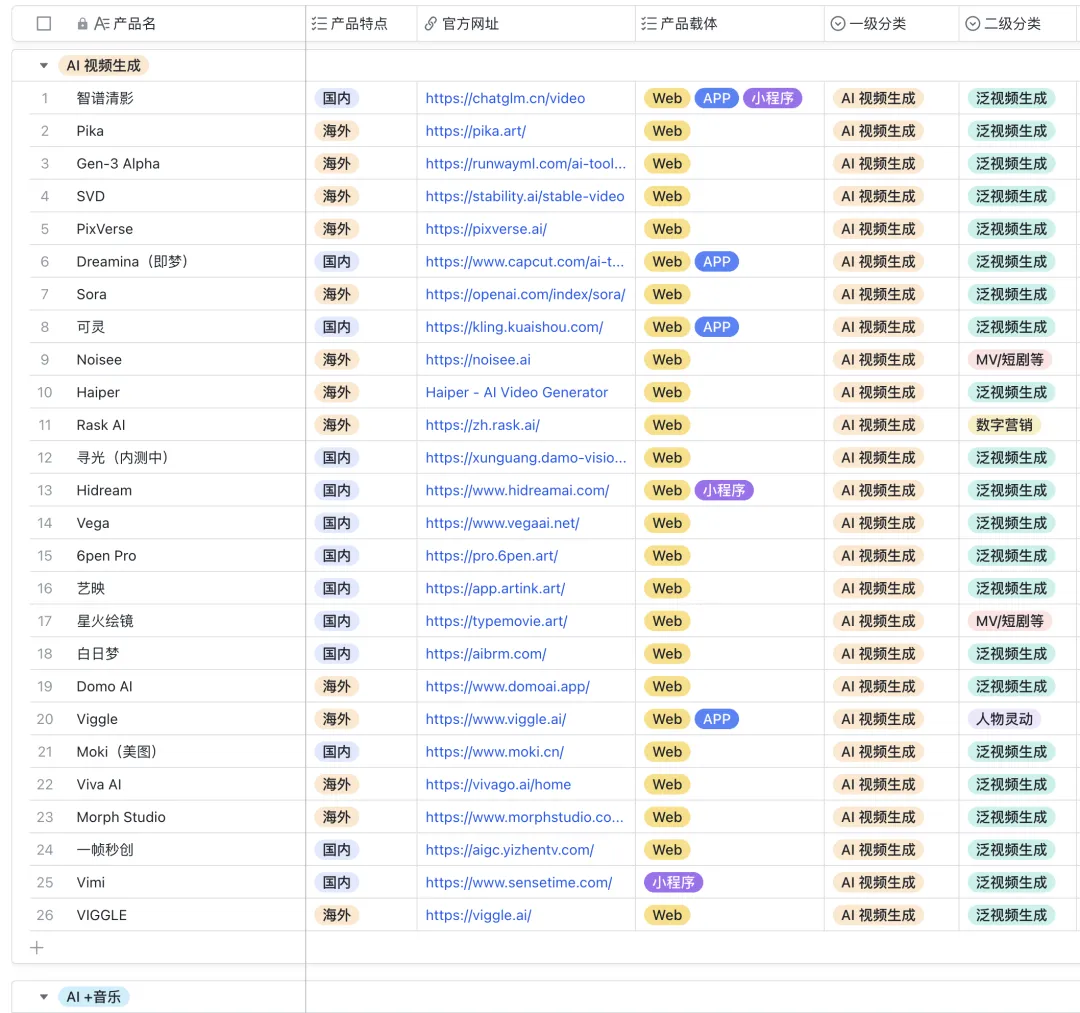
全面对标 OpenAI 的智谱,这一次在发布上遥遥领先。 是的,没有预告,没有期货,智谱上线 AI 生成视频功能了。 在这个神仙打架,“险象丛生”的 2024 年,各路诸侯你方唱罢我登场,简直就是“诸神黎明”,而 AI 生成视频赛道,早已成为兵家必争之地。 在“大模型七雄”之中,率先亮剑的,就是智谱。 在 7 月 25 日上午,智谱带着它的「清影」“杀”了进来。
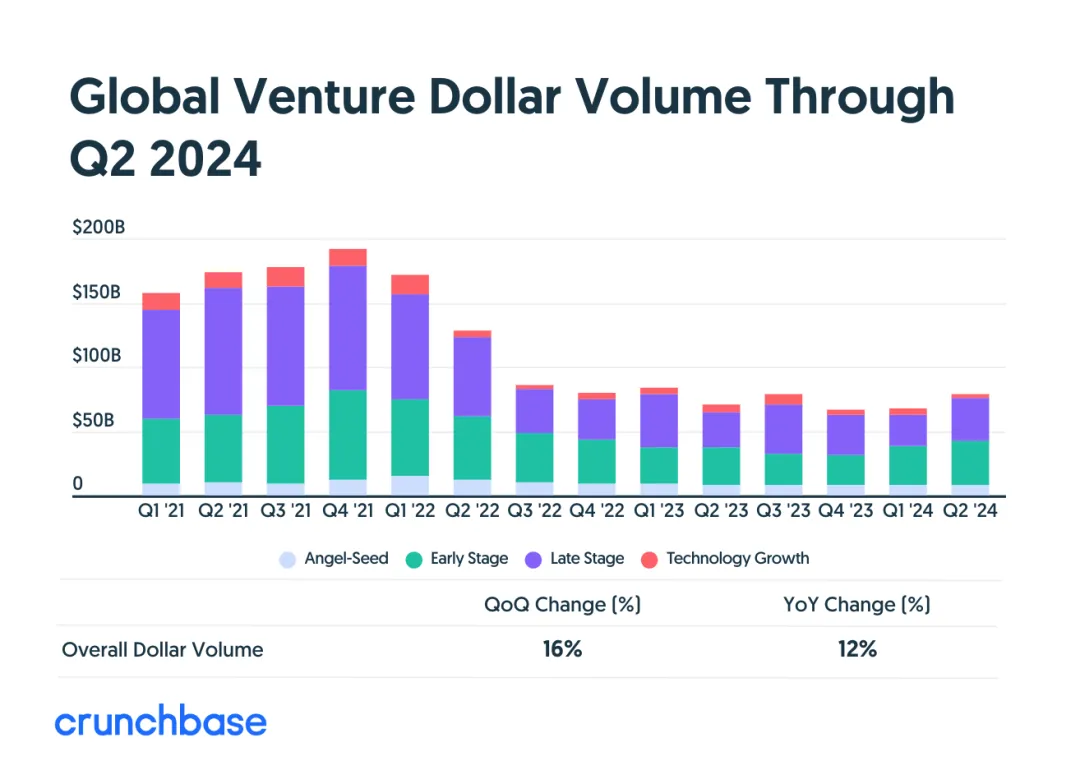
经过两年风险投资增长的放缓,大型融资轮和人工智能领域的资金注入为第二季度带来了强劲的增长势头。这表明资本市场对高潜力领域的支持力度正在加强。
北京时间 7 月 26 日凌晨,OpenAI 发布 AI 搜索产品 SearchGPT,GPT-4 系列模型驱动。