
谷歌192亿买他回来,现在只想让他闭嘴
谷歌192亿买他回来,现在只想让他闭嘴谷歌花27亿美元(约192亿人民币)挖来的Transformer“贡献最大”作者Noam Shazzer,现在点燃了火药桶。
来自主题: AI资讯
10133 点击 2025-11-12 10:23
 搜索
搜索
谷歌花27亿美元(约192亿人民币)挖来的Transformer“贡献最大”作者Noam Shazzer,现在点燃了火药桶。

在7000多种人类语言中,只有少数被现代语音技术听见,如今这种不平等或将被打破。Meta发布的Omnilingual ASR系统能识别1600多种语言,并可通过少量示例快速学会新语言。以开源与社区共创为核心,这项技术让每一种声音都有机会登上AI的舞台。
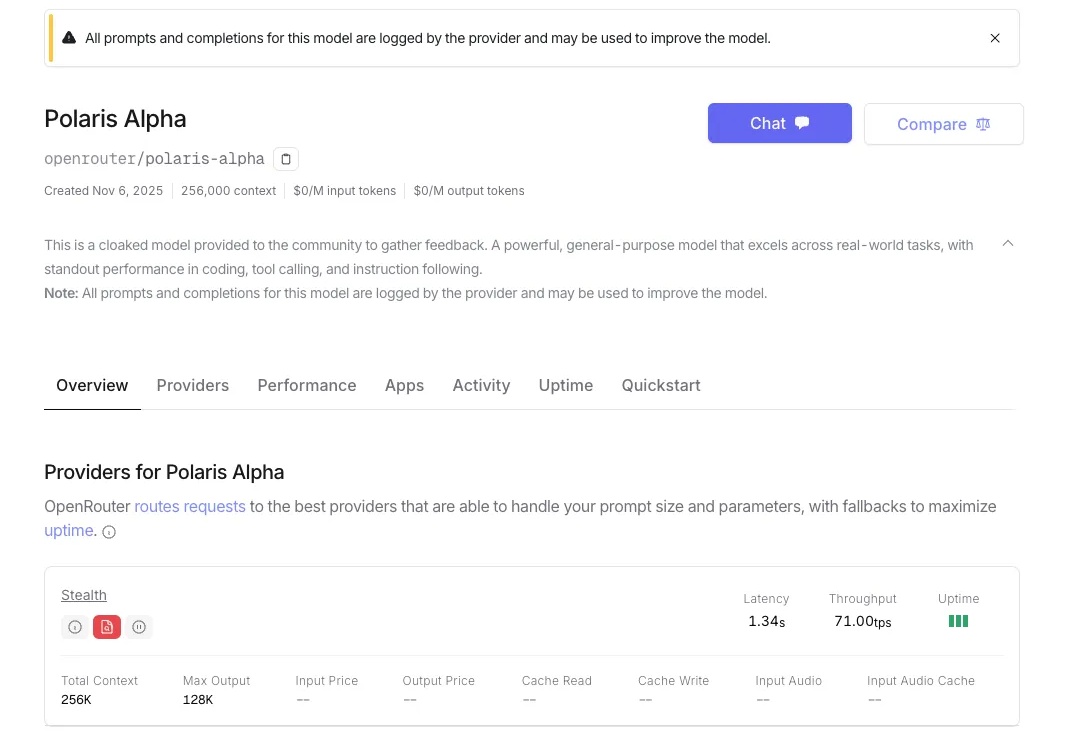
Gemini 3 还没影子,GPT 5.1 已经在路上。7 号深夜,OpenRouter 平台上线了一个全新的隐名模型。已经有眼尖动作快的网友尝鲜体验,并且认为这就是披着马甲的 GPT 5.1,暂名:Polaris Alpha。

过去几个月,大型人工智能公司在印度动作频频。首先是 Perplexity AI 公司与印度第二大移动网络运营商 Airtel 合作,在印度免费提供其高级 Pro 版本。他们免费赠送了一份价值约 17000 卢比(约合人民币 1365 元)的年度订阅服务。这发生在 7 月份。此举拉开了更多类似合作的序幕。

Leonis Capital 在全球超过 10,000 家 AI 初创公司中,基于融资、招聘、用户使用情况,GitHub 趋势、新闻、ProductHunt、ARR 预估等数据和信号,筛选出了 100 家增长最快的初创公司。他们对这 100 家 AI 初创公司进行了详细分析,制作了一份 The Leonis AI 100 的研究报告。
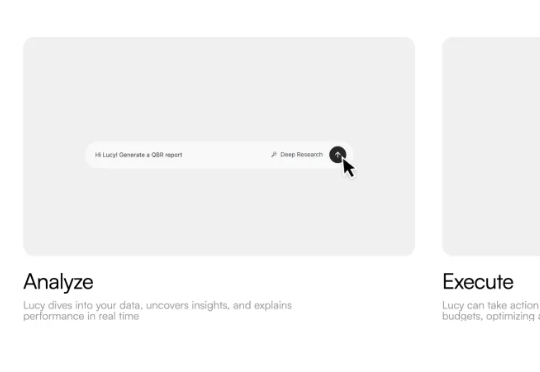
Epiminds 的核心产品是一个名为 Lucy 的 AI 营销经理,但这个描述其实远远低估了它的能力。Lucy 不是一个单一的 AI 工具,而是一个协调者,她指挥着超过 20 个专业化的 AI agent,这些 agent 各自负责不同的营销任务,共同组成了一支完整的虚拟营销团队。

AAAI 2026录用结果重磅公布!这一届,投稿量暴增至23,680篇,录用率仅17.6%,竞争程度远超往年。一些成功上岸的研究员们晒出了录用成绩单,有人甚至拿下了88887高分。

最近,在B站上出现了一个长达近7分钟的“纯AI综艺”,讲全世界6位厨师如何把灭绝了6500万年的远古沧龙做成6道菜,收获了700多万点击。有人压根没看出来这是AI做的,还以为是美国烹饪竞技真人秀《地狱厨房》出了续集。

AI 产业的两大核心趋势正并行发展:基础大模型的能力持续突破,而 AI Agent 的产业化落地也在全面提速。Capgemini 于 2025 年 4 月发布的一项覆盖 14 国 1500 名企业高管的调研显示[1],已有 37% 的受访组织启动或实施 AI Agent 项目,另有高达 61 %的组织将在一年内跟进部署或进行探索,印证了该趋势的全球共识。
半夜 3 点,你跟 AI 苦战许久,横跳在 ChatGPT、Claude、Gemini 等各个平台,辗转反侧。