
葬AI基准测试发布:GLM 5.2第一,超越Opus 4.8
葬AI基准测试发布:GLM 5.2第一,超越Opus 4.8这是葬AI起号以来工作量最大的一篇文章。为了严肃评测国产模型的能力,我自研了一个Benchmark,完整测试了智谱、Qwen、Kimi、Minimax、Deepseek这些最新国产模型,还引入了境外势力Claude作对照组。
来自主题: AI资讯
8705 点击 2026-06-17 13:30
 搜索
搜索
这是葬AI起号以来工作量最大的一篇文章。为了严肃评测国产模型的能力,我自研了一个Benchmark,完整测试了智谱、Qwen、Kimi、Minimax、Deepseek这些最新国产模型,还引入了境外势力Claude作对照组。

逆矩阵计划于 2026 年底发布旗舰模型。
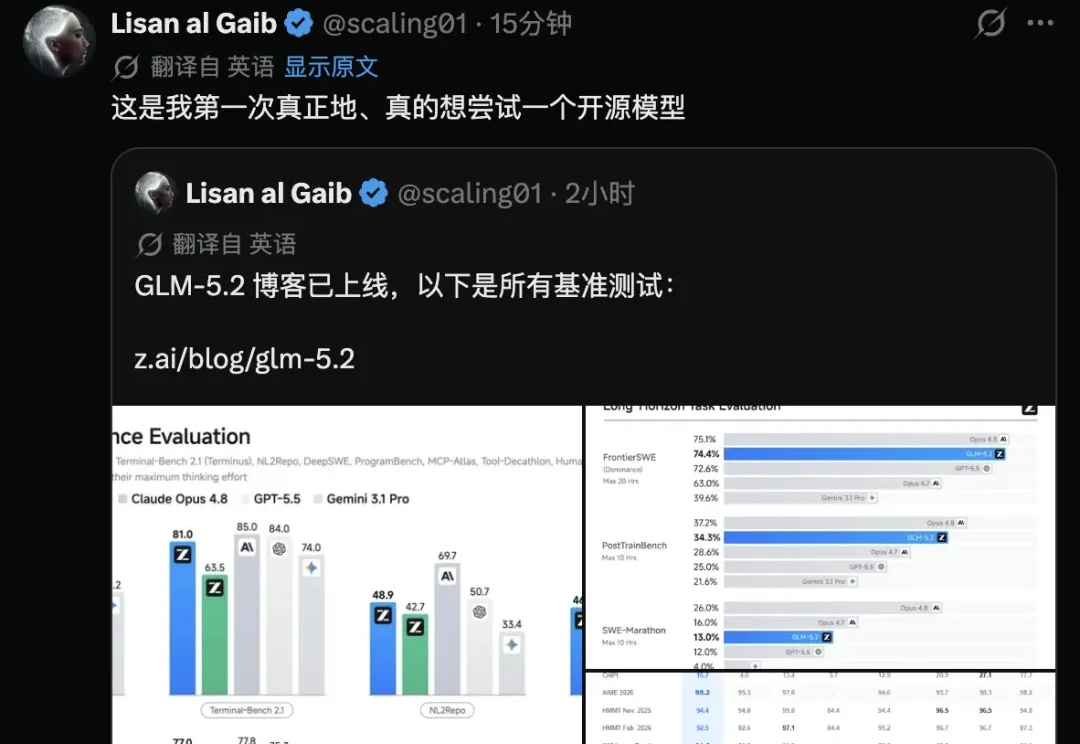
GLM-5.2 正式发布,震撼全网,主打长程任务能力,配合 1M token 上下文窗口,且完全开源(MIT 协议)。在相近的 token 消耗下,GLM-5.2 的能力大致介于 Opus 4.7 和 Opus 4.8 之间,参数仅为753B。

大模型再强,也读不懂你公司那一柜子的合同、发票和扫描件。在"纸张世界"和"LLM世界"之间,缺一座桥——而百度开源的 PaddleOCR,可能就是当下最稳的那座。
这是个一个月前的旧消息, 4月28日,达摩院联合广东省人民医院, 发布了一个叫DAMO COCA的, 肠癌筛查AI模型。
这绝对是近期把“反向创新”和“互联网幽默”玩到极致的一个案例,当整个 AI 行业都在比拼模型参数、Agent 框架、推理能力和算力规模时,一个 17 岁印度高中生却用一种近乎恶作剧的方式,创造了 2026 年最幽默的一个产品。

离谱了。 这两天,AI 圈都在疯传一个叫 Le Chaton Fat 的新模型。 30T MoE、256 个专家、100 万上下文窗口、多模态多语言,跑分全面碾压 Claude Fable 5、Claude Opus 4.8 和 GPT-5.5。
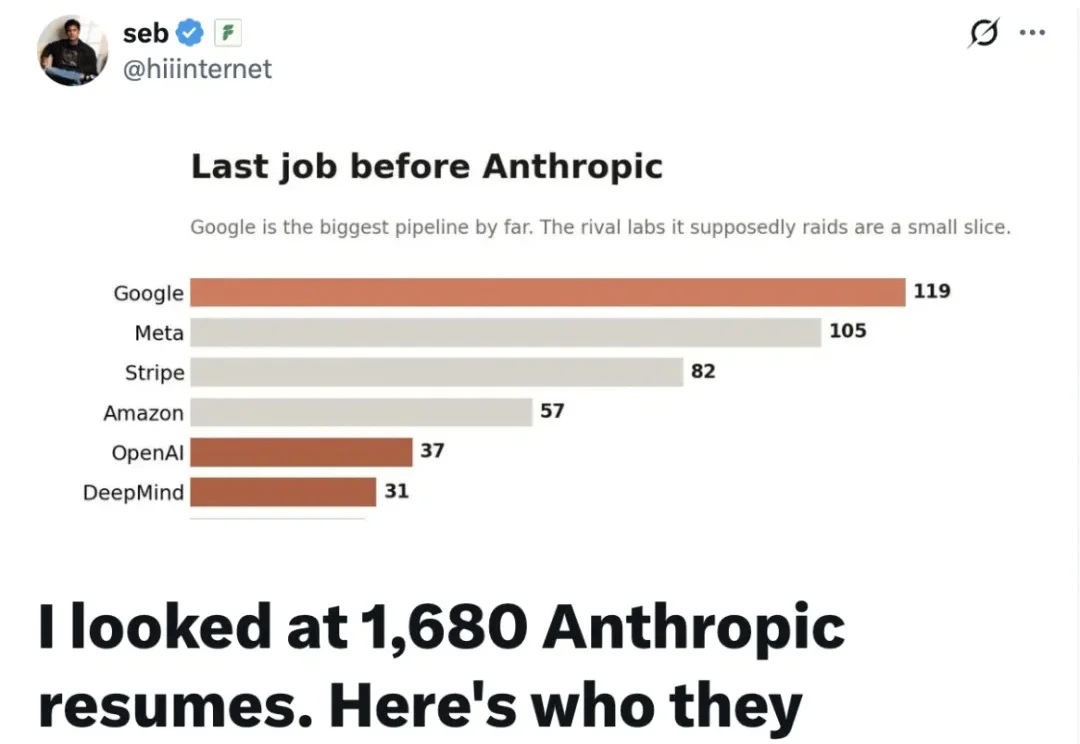
当前,在狂热的 AI 浪潮下,大众对于头部 AI 大厂或明星初创公司往往有着一种带有光环的「刻板印象」:一定是由顶尖高校博士、各大优秀前沿研究论文的作者、算法天才等组成的团队。
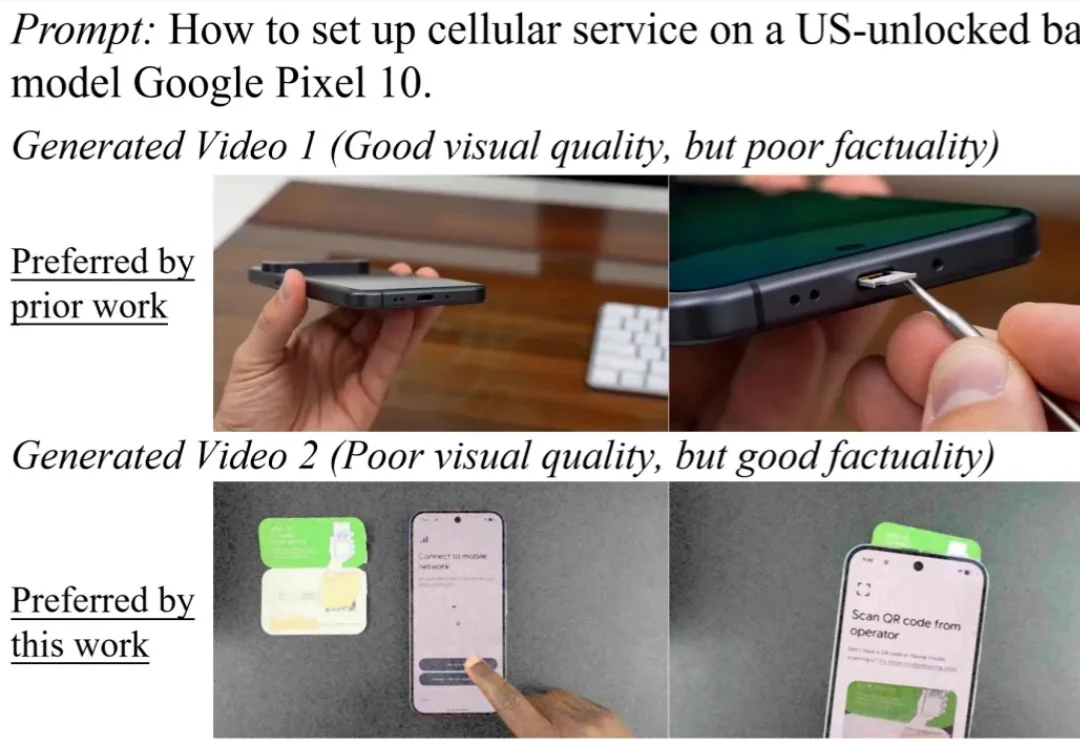
当视频生成模型走出娱乐创作的舒适区,进入科学、医疗、教育等知识密集场景,它们是否还能生成事实准确、清晰可用的视频?
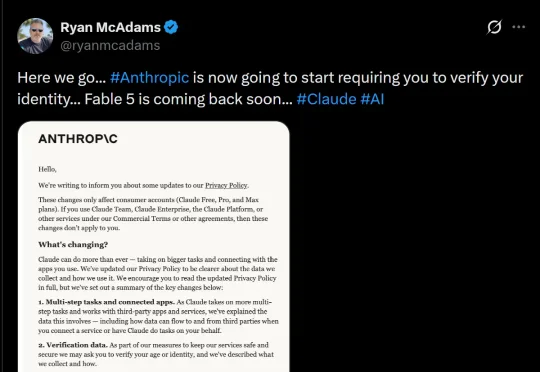
根据邮件内容,从7月8日开始,Claude很可能要向你要身份证了。Anthropic的实名制验证,终于要来了?根据Anthropic官方支持页面,验证将通过第三方服务Persona进行。- 上传政府颁发的、带有照片的身份证件(护照、驾照、身份证等)