

Mira翁荔陈丹琦公司,让老黄掏出了600亿美金
Mira翁荔陈丹琦公司,让老黄掏出了600亿美金又给算力又投资,英伟达又有一大笔资源砸向了Mira的初创公司。
来自主题: AI资讯
9200 点击 2026-03-11 16:58
又给算力又投资,英伟达又有一大笔资源砸向了Mira的初创公司。
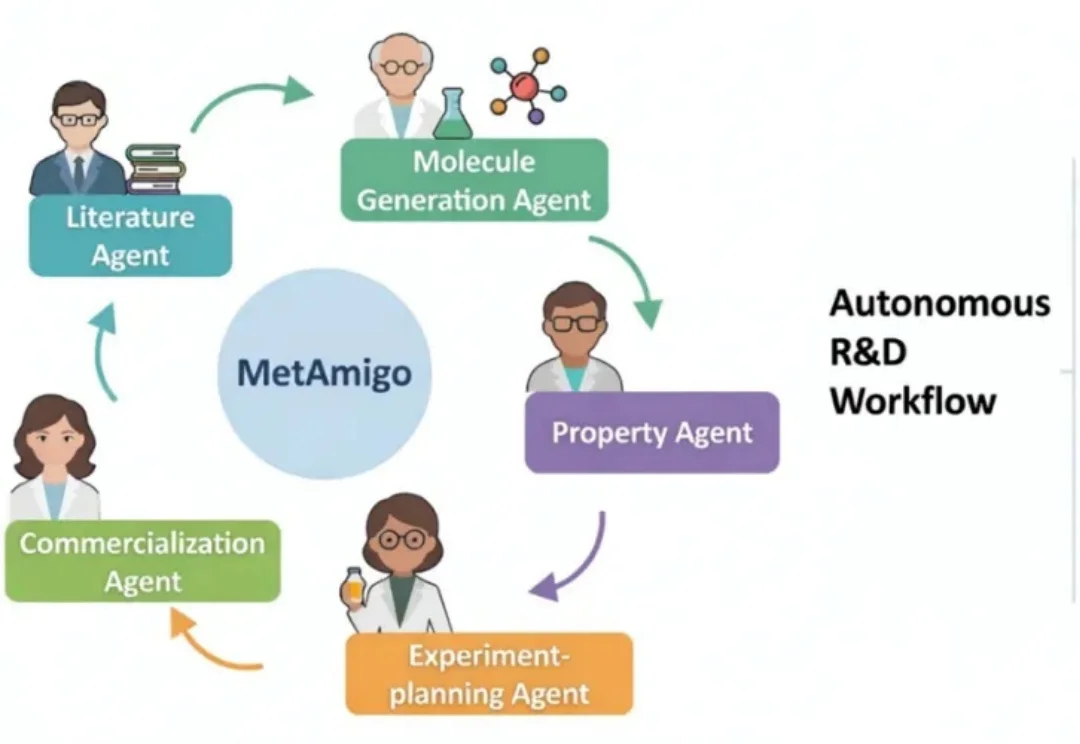
2026 年伊始,AI 的进化逻辑正从「单一工具赋能」转向「场景深度共生」,当大模型在各领域持续突破,前沿科研与新材料研发领域,正迎来一场由 Agentic AI 驱动的效率革命。

从电脑崩溃到半小时拿下Lean形式化证明,数学大神陶哲轩用亲身踩坑经历警告:AI越强大,人类越不能偷懒,应时刻保持「人类在环」的绝对清醒。
进入到 2026 年,人工智能领域被一只「龙虾」(OpenClaw)硬控了。这种具备高主动性、强活人感的私人 AI 助理成为了新一代人机交互的标杆。
好家伙!龙虾老吃家还得看中国。

生物研发进步提速长期受制于海量人工试错。恩和首发全球生物制造物理 AI 平台 SAION,打破 AI 仅限虚拟辅助的痛点。最大惊喜是它「长出了手脚」,能自主设计并直接调度设备执行真实实验,实现闭环进化!其生物科研表现全面超越 GPT 与斯坦福 Biomni,实现 SOTA。AI 科学家终于下场干活了!

ber,装龙虾这才几天啊,怎么就直接二倍速到卸载了???

不卷VLA,这家公司给机器人造生成式大脑。

常州发“养龙虾”十条政策。

杭州萧山设立5000万元开源智能体专项基金。