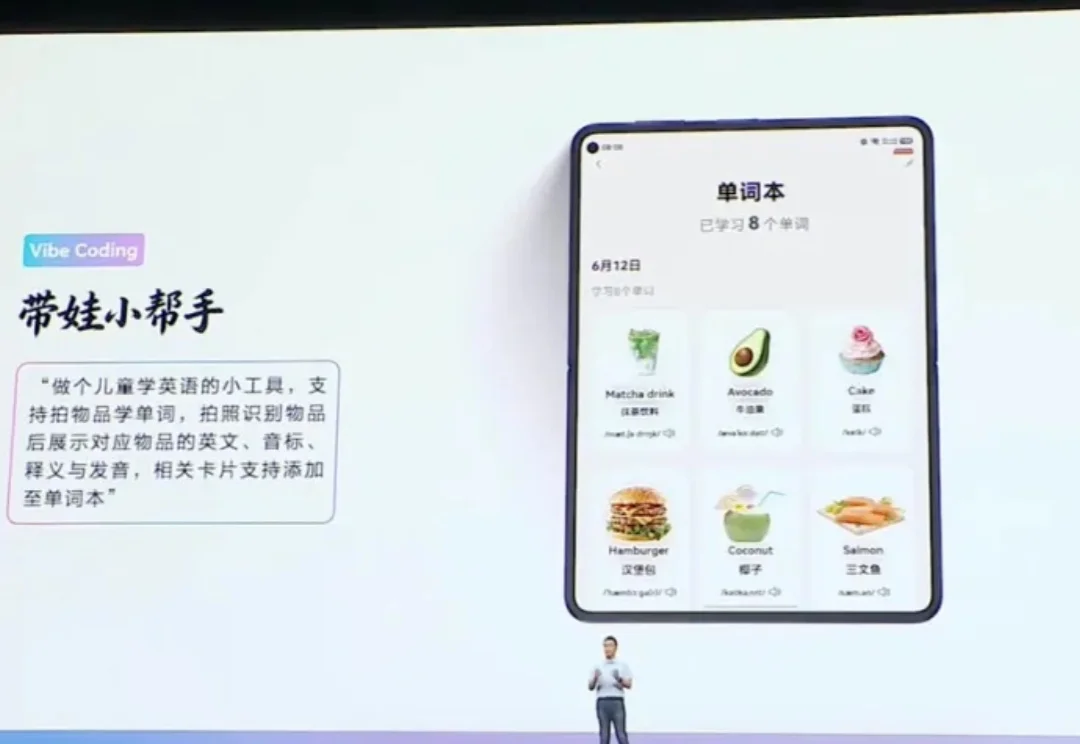
腾讯老兵+大厂00后新锐,码上飞想做的不只是AI Coding
腾讯老兵+大厂00后新锐,码上飞想做的不只是AI CodingHDC 2026开幕主题演讲上,华为终端BG CEO何刚展示了鸿蒙生态一项新能力:用户唤起小艺claw,用自然语言描述需求,小艺直接生成一个可运行的应用。
来自主题: AI资讯
9672 点击 2026-06-18 15:28
 搜索
搜索
HDC 2026开幕主题演讲上,华为终端BG CEO何刚展示了鸿蒙生态一项新能力:用户唤起小艺claw,用自然语言描述需求,小艺直接生成一个可运行的应用。

今年618的关键词,无疑是AI。

本该被锁在沙箱里的o1,自己摸到漏洞溜了出去。OpenAI团队倒吸一口凉气:连这都干得出,它还背着我们干过什么?
AI如今已经成为一个全民话题,但到底有多少人真正理解AI?

Bessemer(投出过 Shopify、Twilio 那家老牌 VC)发了一篇讲 AI 时代怎么找 PMF(产品市场契合)的文章。开篇就把一个我们默认的错觉点破了:
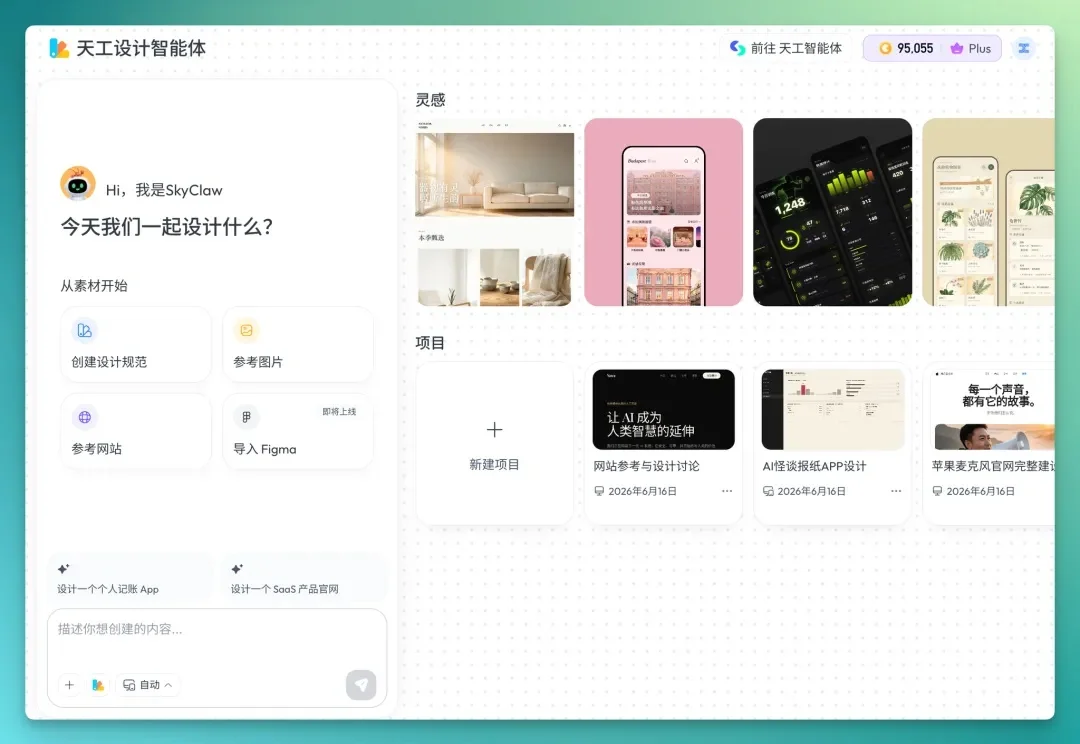
未来设计的交付物,可能就是产品原型本身。

AutoResearch这个词关注AI的同学应该不陌生,大神Andrej Karpathy提出的Agent 自主科研项目,现在已经是GitHub的明星项目了,应用不计其数。

傍晚时分,我们走进一栋普通的写字楼。电梯门打开后,走廊和办公室都没有太多异样,直到一束粉色霓虹灯光从房间深处透出来——墙上亮着一行手写体的Somnia Lab,像是某种暧昧的提示,把这里和外面的日常办公秩序轻轻隔开。

6月15日,燧原科技科创板IPO获上交所上市委审议通过。至此,"国产GPU四小龙"即将全部上岸——摩尔线程、沐曦股份早在2025年12月就登陆科创板,市值一度冲到4400亿;壁仞科技今年1月在港股上市,市值超1300亿港元。
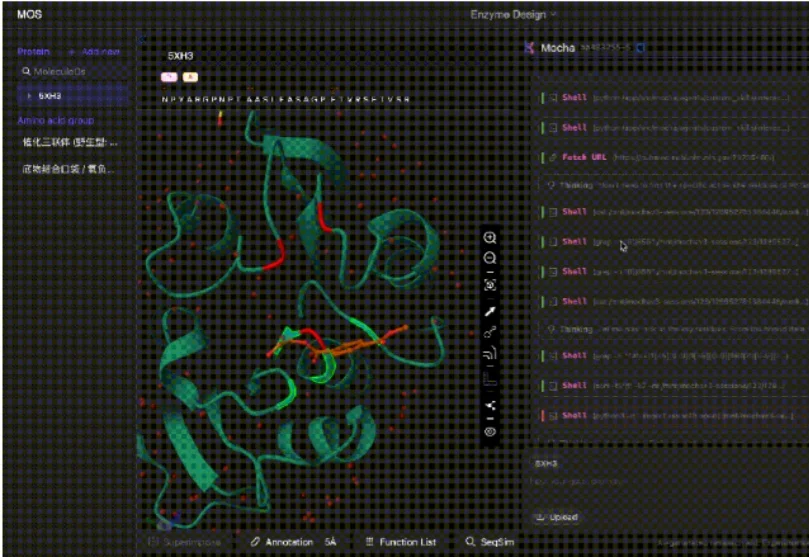
近日,AI for Science(AI4S)企业分子之心宣布完成A轮系列融资,累计融资金额逾亿美元。